Chapitre 4 Les facteurs clés de succès d’une politique d’open data
Dans cette section, nous allons essayer de résumer les facteurs de succès d’une politique d’open data en nous appuyant principalement sur trois sources librement réutilisables.
Tout d’abord, l’outil d’évaluation de l’état de préparation d’une politique d’open data élaboré par la Banque Mondiale en amont de projets d’ouverture de données. Même s’ils sont plus adaptés pour des contextes nationaux, les critères de cet outil de positionnement ont été revus par une communauté mondiale ce qui en fait une source de référence.
Nous nous appuyons aussi sur la checklist des 72 règles destinées aux producteurs de données réalisée par Opquast. Elle propose des critères précis qui servent à évaluer un portail open data et les jeux de données qu’ils contiennent. Chaque critère comprend le détail de l’objectif, de la solution technique pour s’y conformer et le moyen d’évaluation.
Enfin, la check-list des prérequis pour se lancer dans l’OpenData établie par le projet OpenDataLab de la préfecture de région Occitanie permet de mesurer ses points forts et faibles en amont d’une démarche d’ouverture de données. La feuille de calcul proposée dans le kit pour les collectivités permet d’obtenir une visualisation sous forme de matrice pour mesurer la préparation d’une organisation sur le pilotage, l’organisation, l’ouverture des données, l’engagement citoyen, l’animation de l’écosystème et le retour sur investissement.
Ces trois outils ont en commun d’offrir un cadre d’analyse pour déterminer si les conditions sont réunies pour une politique d’open data réussie. Chaque configuration administrative et politique étant différente, ces recommandations doivent être adaptées au contexte de chaque institution. On peut synthétiser ces recommandations en quatre facteurs principaux :
obtenir un soutien au plus haut niveau
configurer l’organisation pour l’ouverture
faciliter la découverte et l’utilisation des données
rester à l’écoute et interagir avec les usagers
4.1 Obtenir un soutien au plus haut niveau
Le soutien politique au plus haut niveau est la condition sine qua none sans laquelle une politique d’open data ne peut être enclenchée et réussie. Les projets d’ouverture des données publiques font souvent face à des résistances liées d’une part aux obligations de protection des données qui incombent aux agents, et d’autre part au fait que certaines personnes (à l’intérieur comme à l’extérieur des administrations)ont toujours bénéficié d’un accès privilégié à l’information et aux données. Il est donc important d’avoir un soutien politique fort et durable pour surmonter ces résistances et assumer les risques politiques (et autres) induits par l’ouverture des données.
L’engagement doit être affirmé au plus haut niveau politique et présenté publiquement. Si possible, cet engagement pourra être renforcé par un vote de l’assemblée compétente (le conseil départemental dans notre cas) dans une délibération qui exposera les ambitions et les moyens mis en oeuvre. C’est ce qu’ont fait par exemple la ville de Nantes et le département du Gers.
Au delà d’un engagement politique, il peut être utile de communiquer auprès du public sur les ambitions de l’institution en matière d’ouverture des données. Cela nécessite en préalable de mettre en place un plan stratégique dans laquelle l’organisation décline les objectifs qu’elle attribue à l’ouverture des données et affiche ses ambitions. Par exemple, la région Ile-de-France s’est fixée pour objectif, avant même l’adoption de la loi pour une République numérique, de parvenir à l’open data par défaut. Le conseil régional a adopté un rapport qui, pour atteindre cet objectif, impose aux administrations une règle « appliquer ou expliquer » : les données doivent être ouvertes par défaut ou l’administration concernée doit rendre compte des raisons pour lesquelles elles ne le sont pas. Un plan stratégique doit aussi afficher un calendrier et des priorités : par exemple, la région PACA dans sa feuille de route stratégique Open Data indique 28 pistes d’actions réparties sur la période 2015-2017 et organisées en deux niveaux de priorité. Il faut aussi penser la gouvernance pour que l’exécution du plan soit suivie. À ce titre, la feuille de route de la région PACA évoquée précédemment organise la gouvernance du projet entre deux niveaux : un comité de pilotage composé d’élus et de cadres dirigeants de l’administration régionale et un groupe de travail qui comporte toutes les organisations contributrices et des invités issus de la société civile locale. Enfin, cette feuille de route stratégique doit inclure un budget défini et provisionné avec des ressources, notamment financières, pour soutenir le développement de services.
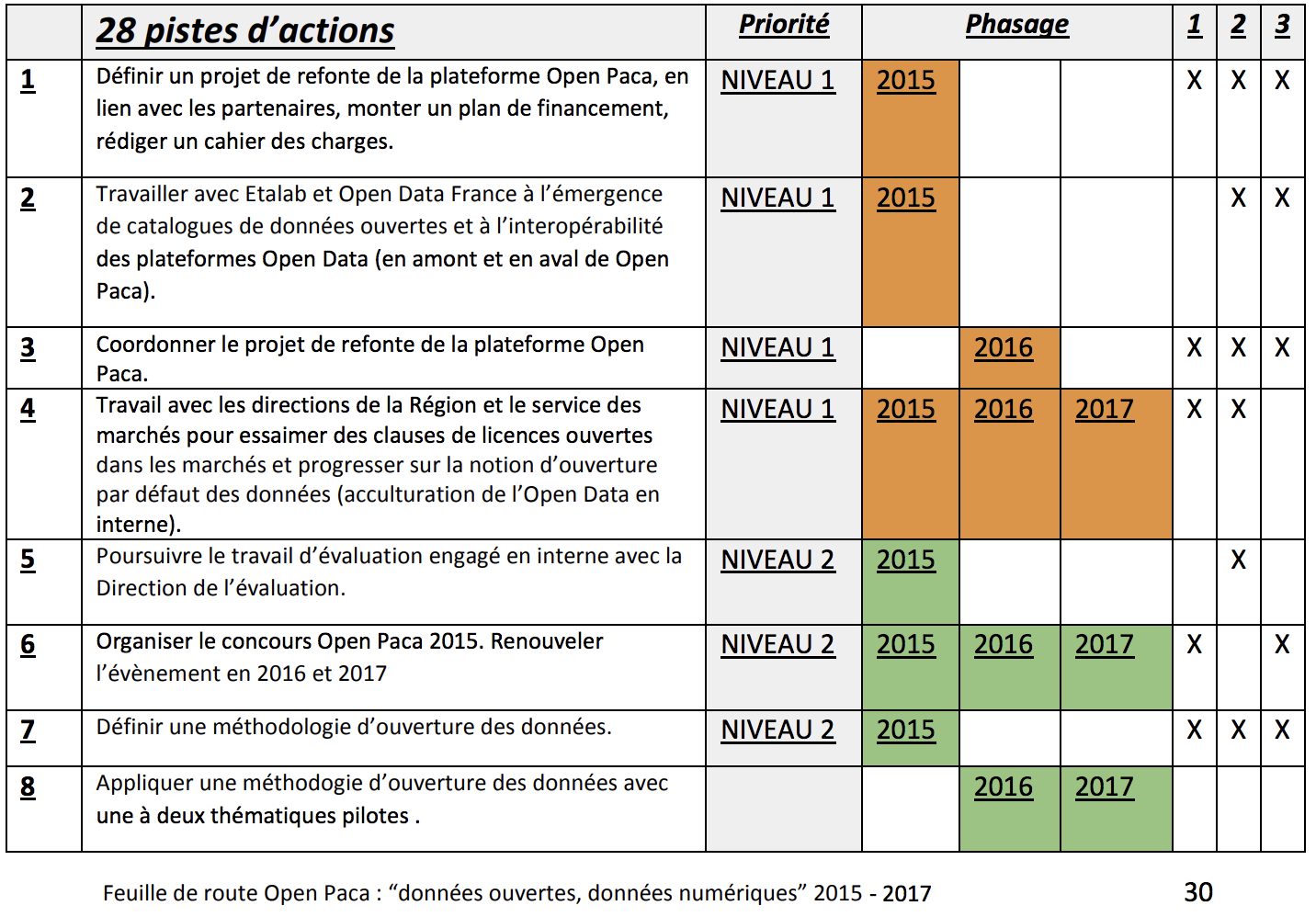
Figure 4.1: La feuille de route du plan stratégique de la région PACA
4.2 Configurer l’organisation pour l’ouverture des données
Ouvrir des données, c’est aussi ouvrir l’administration. Ce changement de paradigme implique de repenser le fonctionnement de l’organisation pour se préparer à ouvrir des données qui, pour certaines, n’avaient jusqu’alors pas fait l’objet d’une diffusion publique.
Un projet d’open data doit d’abord avoir un·e chef d’orchestre. Le responsable de projet open data est un agent qui, si possible, connait bien le fonctionnement de l’institution, a déjà coordonné ou pris part à un projet transversal et dispose d’un soutien politique et administratif important. Le rôle du chef de projet est de coordonner tous les acteurs qui interviennent dans l’ouverture des données, de relancer les producteurs de données, de s’assurer de la qualité des données et de faire le lien avec les réutilisateurs.
Le·la responsable de projet ne doit toutefois pas être la seule cheville ouvrière d’un projet open data, tout ne doit pas reposer sur elle ou lui. Il est important que les responsabilités soient partagées et clairement définies en structurant un réseau dans l’institution. La configuration la plus couramment adoptée dans les collectivités locales est celle d’un réseau de correspondants qui reprend la solution adoptée par l’Etat pour organiser le recensement des données publiques. Les correspondants sont les interlocuteurs privilégiés du responsable de projet : ils lui indiquent les données publiques ouvrables, le présentent auprès des producteurs de données et peut coordonner directement l’ouverture de certains jeux de données. Dans certaines institutions, cette configuration peut être toutefois trop lourde. On privilégiera alors une structuration du réseau plus informelle qui pourra, au fur et à mesure des échanges avec les agents, se formaliser pour que l’ouverture des données entre dans les missions des agents impliqués ce qui facilitera l’articulation avec leurs activités ordinaires.
Sur le volet organisationnel, il faudra aussi prévoir au moins un organe de contrôle. Cet organe de contrôle peut être dans certains cas divisé entre un comité technique composé d’agents, qui déterminera les orientations du projet d’open data (création du portail, sélection des jeux de données à ouvrir en priorité, choix d’une licence, communication…) et d’un comité de pilotage composé d’élus et de cadres dirigeants de l’administration qui auront à faire les arbitrages notamment lorsque l’ouverture d’un jeu de données se heurte à des résistances politiques, administratives ou techniques. En effet, si le mandat est clair, les agents pourront dédier du temps à l’ouverture des données et pourront ouvrir sans difficultés des données jusqu’alors jugées « sensibles ».
Enfin, il peut être utile de cartographier les soutiens et les résistances à la démarche d’ouverture des données. Le projet OpenDataLab préconise en amont de l’ouverture des données d’identifier les soutiens de la démarche avec un pouvoir suffisant, d’identifier les résistances et de prévoir des leviers pour les surmonter.
4.3 Faciliter la découverte et l’utilisation des données
Si l’on se fie aux deux classements internationaux de référence en matière d’open data, l’Open Data Barometer de la Web Foundation et l’Open Data Index d’Open Knowledge, les projets d’ouverture de données font face à deux écueils majeurs : la découvrabilité et la qualité des données.
Concernant le premier point, il est courant d’entendre des usagers de données ouvertes déclarer qu’ils ont les plus grandes difficultés à trouver les données qu’ils/elles cherchent. Par exemple, Jules Grandin journaliste au Monde racontait récemment dans un tweet la « déception en 4 actes » de sa recherche de données sur la fréquentation des stations de RER en région parisienne. Après une recherche Google, un jeu de données sur data.gouv.fr intitulé « comptage voyageur sur RER » lui est proposé en premier résultat. Quand il télécharge le fichier, celui ne fait qu’une ligne et deux colonnes indiquant le nombre de voyageurs sur la ligne 0.
Ce cas est révélateur de l’expérience courante et souvent décevante des usagers de données ouvertes. D’une part, les données ouvertes sont encore l’exception mais, quand elles sont ouvertes, il est très difficile de les localiser. Par exemple, le moteur de recherche de data.gouv.fr renvoie rarement vers les données qu’on cherche, c’est ce qu’a révélé une étude auprès des utilisateurs du portail réalisée par Thomas Parisot pour Etalab : tapez «élections » sur data.gouv.fr et vous trouverez plus de 650 jeux de données dont beaucoup ne sont pertinents que localement. Ainsi, pour l’Open Data Index, la question de la découvrabilité (findability) des données est un prérequis pour que l’open data remplisse son potentiel mais, à l’heure actuelle, la plupart des données sont très dures à localiser.
Pour faciliter la découverte des données, on pourra d’abord s’assurer que les métadonnées soient complètes et décrivent correctement le jeu de données. Selon une étude récente réalisée par Datactivist sur les catalogues de données de 15 villes en France, seuls 4 % des jeux de données ont une description qui dépasse les 1000 caractères soit moins d’une demi-page A4. Difficile dans ces conditions de trouver les données et de comprendre ce qu’elles contiennent. On pourra aussi s’assurer que les jeux de données ne sont pas référencés uniquement sur le portail open data. Une mesure simple mais rarement entreprise consiste à s’assurer que le site de l’institution renvoie vers les jeux de données présents sur le portail. Dans une page sur les subventions aux associations, pourquoi ne pas renvoyer vers le jeu de données qui présente les subventions attribuées les années précédentes ?
Enfin, il est important de s’assurer que le portail s’adresse à un large public et pas uniquement aux usagers habituels des données. Par exemple, il n’est expliqué nulle part sur data.gouv.fr comment ouvrir un fichier CSV même si, en France, la plupart des fichiers CSV utilisent le point-virgule et non la virgule (utilisée par défaut à l’étranger) pour séparer les valeurs. Cela demande souvent de changer le paramétrage du tableur ce qui peut dérouter de nombreux usagers. Pour éviter que les données ne s’adressent qu’à celles et ceux qui les manipulent au quotidien, on pourra entreprendre un travail de définition de personas comme l’a fait la ville de New York avec le projet « meet the users of open data. »

Figure 4.2: Les personas définis par la ville de New York pour son projet
Concernant la qualité des données, l’Open Data Barometer a soulevé cet enjeu dans son quatrième rapport :
« Les données publiques sont souvent incomplètes, périmées, de mauvaise qualité et fragmentées. Dans la plupart des cas, les portails et les catalogues de données ouvertes sont alimentés manuellement résultant d’approches informelles de gestion des données. Les procédures, les échéances et les responsabilités sont fréquemment obscures parmi les institutions gouvernementales en charge de ce travail. »
Il en résulte que, bien souvent, les données sont souvent inutilisables par manque de granularité temporelle et spatiale, l’absence de mise à jour, par une documentation qui ne permet pas de comprendre comment les données ont été produites et ce qu’elles décrivent. Ces problèmes de qualité ne concernent pas que les administrations pour lesquelles la diffusion de données est inédite, on retrouve ces problèmes pour certaines organisations dont la production de données constitue le cœur de l’activité. Par exemple, un usager des données ouvertes a listé dans un billet de blog les problèmes qu’il a rencontrés avec les données ouvertes d’Infogreffe. Son billet décrit de nombreux problèmes auquel l’usager doit faire face : des colonnes qui disparaissent, sont créées ou renommées au fil des années, des colonnes “parasites” dont le nommage ou la documentation ne permettent pas de savoir ce qu’elles contiennent, des jeux de données annualisés qui contiennent plusieurs années de données, des colonnes en doublon, des coordonnées géographiques fausses, une documentation quasi inexistante…
Pour éviter ces problèmes, on pourra s’appuyer sur la méthodologie du sprint qualité élaboré par la Fondation Internet Nouvelle Génération (FING) dans le cadre du projet Infolab. Cette méthodologie propose une centaine de points de contrôle pour s’assurer de la qualité d’un jeu de données. Pour une approche plus rapide, il peut être utile de faire un contrôle rapide des jeux de données (ce que les data scientists appellent un « sanity check ») en utilisant un outil simple comme WTF CSV qui permet de prévisualiser le contenu d’un jeu de données et donne un résumé des valeurs extrêmes et manquantes pour chaque colonne.
Figure 4.3: WTFCSV permet de prévisualiser le contenu des données
4.4 Rester à l’écoute et interagir avec les usagers
Les projets d’open data constituent généralement des politiques de l’offre dans lesquelles l’administration décide quelles données ouvrir, ce qu’elles contiennent, quand les ouvrir et les mettre à jour. Pour s’efforcer à résoudre les problèmes évoqués dans la section précédente, il nous parait important de nous orienter vers des projets d’open data qui consacrent la demande déjà dans la sélection des données à ouvrir mais aussi qui impliquent les usagers tout au long de l’ouverture des données.
Cela implique d’abord de mettre en place des moyens d’échange. La plupart des portails d’open data prévoient une fonctionnalité de commentaires et de discussions ; or, celle-ci est rarement activée souvent par crainte de ne pas être en mesure de traiter les demandes. Ne pas ouvrir les discussions, c’est se priver de la possibilité d’améliorer ses données par les retours des usagers, un des bénéfices majeurs de l’ouverture des données. Il faut aussi mettre en place une procédure pour le traitement des commentaires et former les agents à traiter les demandes même si la réponse ne peut pas toujours satisfaire le citoyen. Il est recommandé que les questions et les réponses soient publiques (on pourra s’inspirer des discussions de la communauté sur data.gouv.fr) pour que les usagers qui rencontrent le même problème avec un jeu de données puissent, d’une part, interagir entre eux pour trouver une solution et, d’autre part, consulter la réponse de l’administration sans reposer la même question. On pourra aussi avoir recours aux réseaux sociaux pour obtenir les retours des usagers. Il peut être utile d’ouvrir un compte dédié ce qui permet d’éviter d’utiliser ses comptes personnels en tant qu’agent et de ne pas interférer avec les messages du compte principal de l’institution.
Le travail d’animation territoriale constitue un autre facteur de succès de la médiation des données ouvertes. Cela commence par un travail de qualification de la demande de données provenant de la société civile et des médias et de cartographie des « champions » et des promoteurs de l’ouverture des donnés au niveau du territoire. Il peut être utile de développer des partenariats avec des organismes usagers de données pour les encourager à promouvoir la démarche et à exploiter les nouvelles données ouvertes. L’animation du réseau peut ainsi prendre des formes très variées : organisations d’évènements type hackathon ou open data camp, meetups dans lesquels producteurs et réutilisateurs de données se rencontrent, défis de réutilisation de données, ateliers de médiation dans lesquels un public sans compétence technique en la matière est accompagné dans la réutilisation de données…