Objectifs de la journée
- Comprendre ce qu’est une donnée
- Appréhender la variété des types de données existantes
- Comprendre le data pipeline
- Appréhender les enjeux politiques et juridiques attachés aux données
Qu’est-ce qu’une donnée ?
Qu’est-ce qu’une donnée ?
D’après vous ?
Sociologie historique de la quantification

Sociologie historique de la quantification

Sociologie historique de la quantification
La statistique est à la fois :
- outil de gouvernement (Statistik - 18e siècle), et
- outil de preuve (statistics - 19e siècle)
Sociologie historique de la quantification
Quantifier, c’est convenir puis mesurer
Le verbe quantifier est employé ici dans un sens large : exprimer et faire exister sous une forme numérique ce qui, auparavant, était exprimé par des mots et non par des nombres. En revanche, l’idée de mesure, inspirée de l’épistémologie traditionnelle des sciences de la nature, implique que quelque chose existe sous une forme déjà mesurable selon une métrologie réaliste, comme la hauteur de la Tour Eiffel.
Sociologie historique de la quantification
New Deal puis après-guerre : apogée de l’État keynésien => macro-économie
Aux sources de la mise en données du monde
- Rencontre, dans la Californie des années 1960, entre la Nouvelle Gauche et les Nouveaux Communalistes sur fond de LSD et de recherche militaire
- L’inspiration de la cybernétique (N. Wiener) : objets techniques et êtres humains constituent un même système sociotechhnique, régulé par l’information
- Exemple de Steward Brand, fondateur du Whole Earth Catalog puis de Wired => “Forest Gump de l’Internet”
Aux sources de la mise en données du monde

Etymologie
Latin : dare (donner) > datum (donné) > data (donnés)
Ce qui est évident, va de soi, est accepté sans discussion
Facts are ontological, evidence is epistemological, data is rhetorical. A datum may also be a fact, just as a fact may be evidence. But, from its first vernacular formulation, the existence of a datum has been independent of any consideration of corresponding ontological truth. When a fact is proven false, it ceases to be a fact. False data is data nonetheless.
Rosenberg, 2013
Etymologie
Ambiguïté en anglais de “data” qui peut être un pluriel ou un singulier collectif.
Whether in mathematics, theology, or another field, use of the term “data” emphasized the argumentative context as well as the idea of problem-solving by bringing into relationship things known and things unknown
Usage de “data”
Le sens moderne apparaît à la fin du 18e siècle => renvoie à des expériences, des collectes d’éléments.
“Raw data” is an oxymoron
Data are always already “cooked” and never entirely “raw.”
Data need to be imagined as data to exist and function as such, and the imagination of data entails an interpretive base.
[Source]
Données, données… quelles données ?
Données, données… quelles données ?

Données, données… quelles données ?
Data are commonly understood to be the raw material produced by abstracting the world into categories, measures and other representational forms – numbers, characters, symbols, images, sounds, electromagnetic waves, bits – that constitute the building blocks from which information and knowledge are created.
=> enregistrabilité => briques de base (“buildings blocks”)
Données, données… quelles données ?
While many analysts may accept data at face value, and treat them as if they are neutral, objective, and pre-analytic in nature, data are in fact framed technically, economically, ethically, temporally, spatially and philosophically.
Technically, then, what we understand as data are actually capta (derived from the Latin capere, meaning ‘to take’); those units of data that have been selected and harvested from the sum of all potential data.
[Source]
« Décidément, on ne devrait jamais parler de “données”, mais toujours d’“obtenues”. » - Bruno Latour, 1993
Données quantitatives et qualitatives
- Données quantitatives : enregistrées sous forme de nombres
- nominale (marié/célibataire/divorcé/veuf)
- ordinale (faible, moyen, fort)
- intervalles (température en degrés Celsius)
- ratio (taille en cm)
Données quantitatives et qualitatives
- Données qualitatives : non numérique => texte, image, vidéo, son, musique…
- peut être convertie en données quantitatives
- mais comment ?
- risque de perdre la richesse des données originales
- analyse qualitative
Données structurées et non structurées
Données structurées : dotées d’un modèle
- Ex : base de données relationnelle SQL
- Lisibles machine
- Faciles à analyser, manipuler, visualiser…
Données semi-structurées : pas de modèle prédéfini. Structure irrégulière, implicite… mais données organisées néanmoins, ensemble raisonnable de champs
- Exemple : XML, JSON
- possible de trier, ordonner et structurer les données
Données structurées et non structurées
Données non structurées : pas de structure commune identifiable
- Exemple : BDD NoSQL
- généralement qualitatives
- difficilement combinées ou analysées quantitativement
- les données non structurées croitraient 15x plus que les données structurées
- machine learning de + en + capable d’analyser ces données.
Données capturées et données échappées
- Données capturées : observation, enquête, expérimentation, prise de notes, senseurs… => intention de générer des données
- Données échappées : sous-produit d’un engin ou d’un système dont la fonction première est autre
- Données transitoires : échappées qui ne sont jamais examinées, transformées ou analysées
=> brutes car non converties ou combinées
Données dérivées
- Résultat d’un traitement ou une analyse supplémentaire de données capturées.
- Souvent le résultat d’un modèle
Données dérivées

Données primaires, secondaires et tertaires
- primaires : générées par un chercheur dans un cadre expérimental
- secondaires : mises à disposition d’autrui pour être réutilisées
- tertiaires : données dérivées : décomptes, catégories, résultats statistiques
Ex : recensement => pas diffusé comme données primaires et secondaires avant communicabilité des archives, diffusé comme données tertiaires
Bayésiens et fréquentistes
- fréquentistes : le monde existe indépendamment de nos interactions avec lui. Données issues d’un échantillon aléatoire, réplicable (fréquence). Expériences et tests statistiques : un énon cé est falsifié ou non falsifié.
- bayésiens : la statistique porte sur les croyances à l’égard du monde, qu’on fait évoluer au regard des données collectées
Bayésiens et fréquentistes

Le pipeline de données
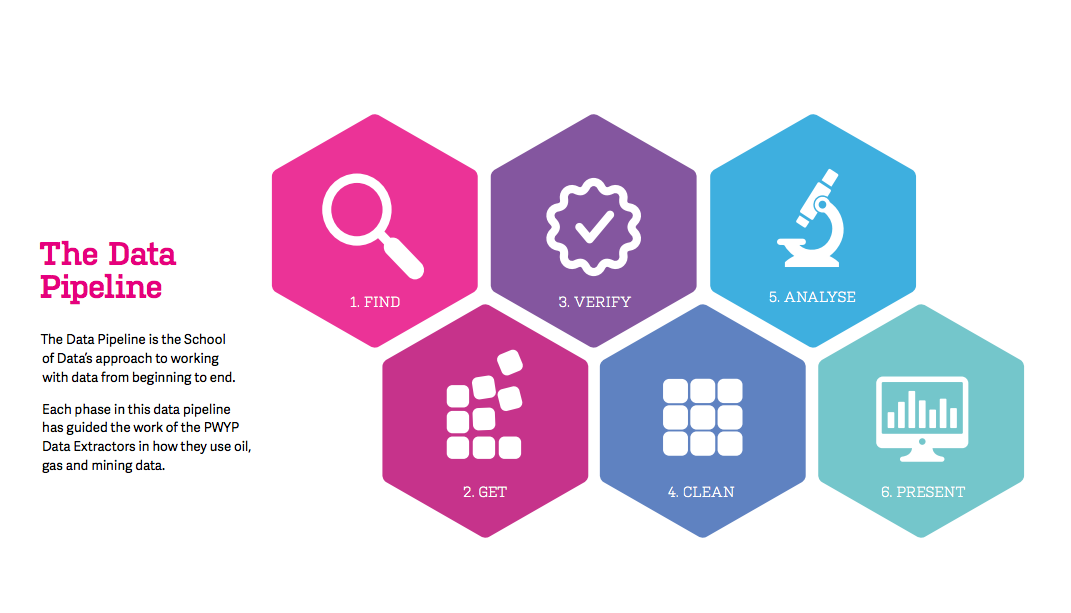
Trouver les données
- Comment faites-vous ?
- Dépôts internes
- CDO
- Dépôts externes (ex. www.data.gouv.fr)
Acquérir les données
- format des données
- qualité des données
- documentation des données / métadonnées
- ETL / connecteurs
- données “chaudes” / données “froides” (stock/flux)
Nettoyer les données
“Happy families are all alike; every unhappy family is unhappy in its own way.” – Leon Tolstoï
“Tidy datasets are all alike, but every messy dataset is messy in its own way.” – Hadley Wickham
Nettoyer les données
- paradigme du tidy data (Hadley Wickham)
- chaque variable correspond à une colonne
- chaque observation/individu correspond à une ligne
- chaque type d’unité d’observation correspond à une table
- chaque cellule comporte une donnée
Nettoyer les données
5 problèmes fréquents :
- les noms des colonnes sont des valeurs, pas des variables
Nettoyer les données
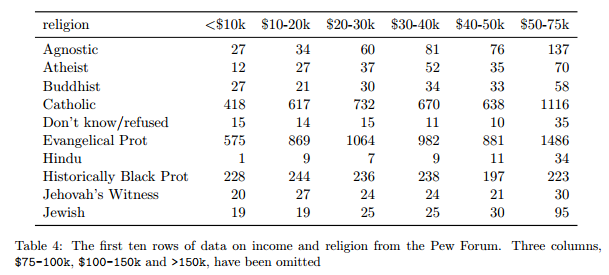
Nettoyer les données
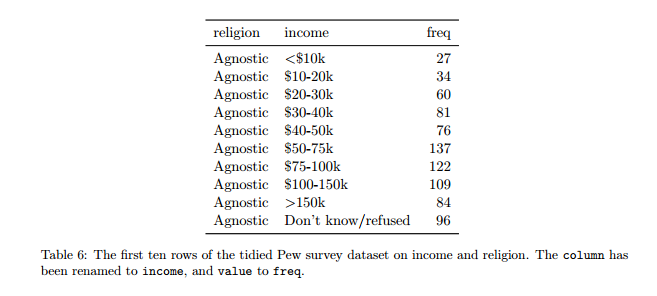
Nettoyer les données
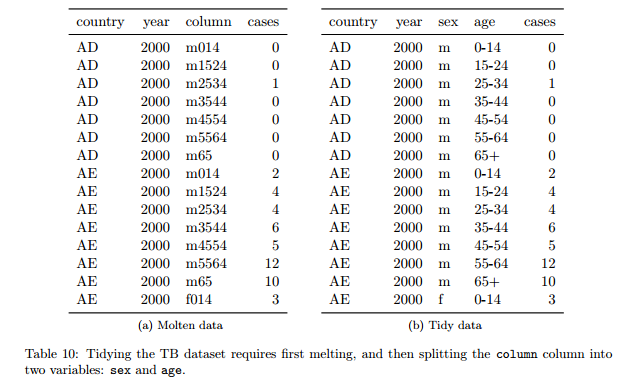
5 problèmes fréquents :
- les noms des colonnes sont des valeurs, pas des variables
- plusieurs variables dans une colonne
Nettoyer les données
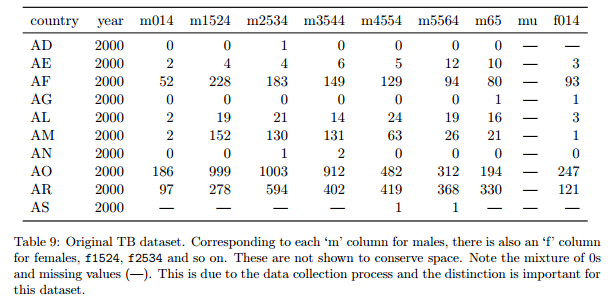
Nettoyer les données
Nettoyer les données
5 problèmes fréquents :
- les noms des colonnes sont des valeurs, pas des variables
- plusieurs variables dans une colonne
- les variables sont stockées à la fois dans les lignes et les colonnes
Nettoyer les données
Nettoyer les données
Nettoyer les données
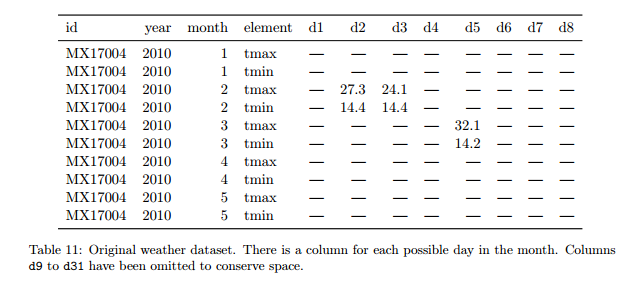
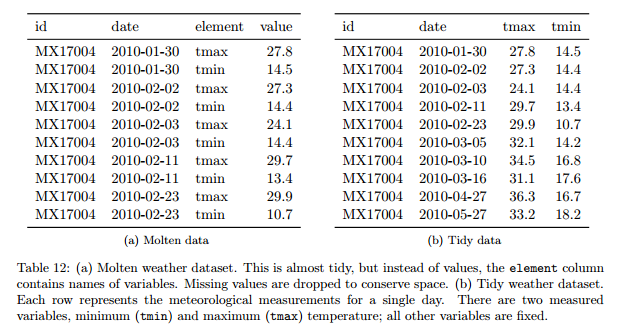
5 problèmes fréquents :
- les noms des colonnes sont des valeurs, pas des variables
- plusieurs variables dans une colonne
- les variables sont stockées à la fois dans les lignes et les colonnes
- plusieurs types dans une table
Nettoyer les données
Nettoyer les données
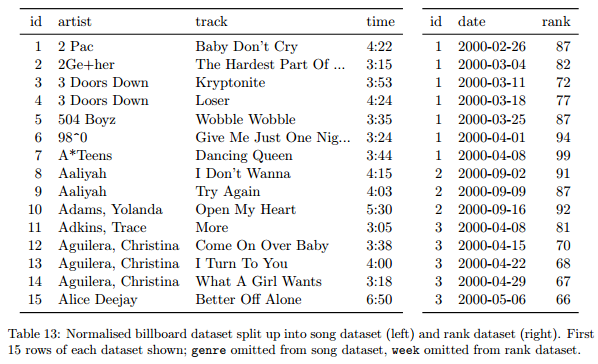
Nettoyer les données
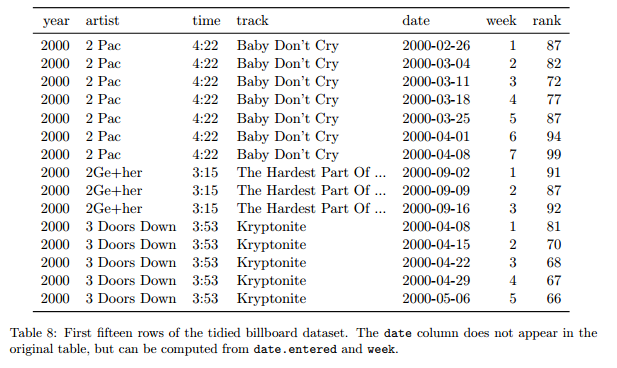
5 problèmes fréquents :
- les noms des colonnes sont des valeurs, pas des variables
- plusieurs variables dans une colonne
- les variables sont stockées à la fois dans les lignes et les colonnes
- plusieurs types dans une table
- un type dans plusieurs tables
Analyser les données
- indicateurs
- tabulations
- modèles
- machine learning
- simulation
- etc.
Présenter les résultats
- datavisualisation
- génération automatique de rapports
- application
- etc.
Open data, big data, linked data…
Open data
Justifications :
- transparence / accountability
- innovation / “pétrole”
- modernisation de l’administration
Open data
- données publiques, généralement de gestion
- librement utilisables (licences)
- pas de redevance
- Open definition
Big data
- émerge vers 2007/2008 (mais occurrences anciennes)
- trois V : “volume”, “velocity”, “variety”
- Kitchin ajoute exhaustivité, la résolution, la scalability
- NoSQL (terme apparaît en 2009)
- promesse d’efficience, de prédiction, de nouvelles formes de savoir
- données généralement fermées et privées
API
- Application programming interface => un programme vu de la surface
- les machines parlent aux machines
- donnée dynamique => partage partiel
- un exemple : overpass turbo
Cadre juridique et protection de la vie privée
Cadre juridique de l’open data
- circulaire et vade mecum de 2013
- lois NOTRE et Lemaire : principe de l’ouverture par défaut
- Licence ouverte : permet la réutilisation la plus large
- principes opposés : données nominatives, données personnelles, secrets prévus par la loi (défense, statistique, médical, commercial…)
Tout savoir sur l’open data au concret
