Carnet de bord de l’ouverture des données de Tarentaise Vanoise - groupe 1
par MARTINEZ Maëlys, SALIBA Lilou, CLAIRE Manon, HINNEH Anita, FONTCUBERTA Elise, PERRAULT Alexandre, ADOUKI Wendy
INTRODUCTION
Dans le cadre de notre cursus, nous avons formé une équipe de sept étudiants provenant des masters de Droit/Action Publique et de Relations Internationales pour participer au challenge data. Ainsi, nous nous sommes vus attribuer l’Assemblée du Pays de Tarentaise Vanoise, en collaboration avec un autre groupe de sept étudiants. L’objectif est de travailler sur les données de transports publics pour rendre plus accessible ces informations pour les usagers.
Le Pays de Tarentaise Vanoise s’étend sur une superficie de 1700km2 et comporte environ 50 000 habitants, chiffre multiplié par 7 en hiver en raison du tourisme lié aux sports d’hiver. Il s’agit d’une grande vallée des Alpes se situant à l’est de la Savoie et à proximité de la vallée des Dorons. Plus de 25% du territoire est protégé au titre du Parc national de la Vanoise. Il est nécessaire de protéger ce territoire, riche en biodiversité, néanmoins, le tourisme représente un danger pour l’environnement notamment à cause de la pollution de l’air. La vallée subit des pics de pollution atmosphérique à cause de l’utilisation de la voiture et il est nécessaire d’encourager un report des usagers vers le transport public.
L’objectif final est de publier les données collectées sur le site internet data.gouv.fr en répondant aux demandes de notre interlocutrice, représentant l’Assemblée du Pays de la Tarentaise Vanoise. Pour ce faire, nous devons contacter les différentes mairies ainsi que leurs transporteurs afin de, si possible, collecter des données au format GTFS. De cette façon, nos interlocuteurs principaux sont : Les Avanchers Valmorel, La Léchère, la communauté de communes de Cœur de Tarentaise, de Brides-les-Bains ainsi que Courchevel.
Cette collecte de données est réalisée dans l’objectif de faire paraître sur les applications et sites de navigation les différents trajets et horaires des lignes de bus de la vallée. Ce projet a donc un aspect purement pratique pour les usagers, mais agit également en faveur d’une écomobilité pour la préservation de l’environnement.
JOUR 1 – DIAGNOSTIC
Résumé
Notre groupe travaille sur les communes de l’Assemblée du Pays de Tarentaise Vanoise. En raison de sa situation géographique, de ses vallées et de l’importance du tourisme lié aux sports d’hiver, cette région développe un important réseau de transport pour répondre aux pics de pollution atmosphérique. Néanmoins, les données sont difficilement accessibles pour les usagers de ces réseaux (horaires, arrêts, lignes…) et l’ouverture des données permettrait le report modal des usagers.

Nous découvrons que nous travaillons avec le groupe 8 sur le même sujet. Dans la perspective de la réunion de l’après-midi, nous faisons des recherches sur internet (site internet de la communauté, réseaux sociaux…) et nous préparons ensemble la réunion et nous nous répartissons les tâches de façon efficace. Au sein du groupe 1, l’ambiance est tout aussi bonne. Nous ne nous connaissions pas toutes et tous en amont mais nous arrivons à travailler ensemble de manière à avancer rapidement en nous répartissant les tâches.
A 15h, nous appelons notre interlocutrice, Cheffe de projet Avenir Montagne en Transition des mobilités, l’enjeu nous paraît beaucoup plus clair et son enthousiasme nous motive. Elle a présenté l’ouverture des data sous l’angle de l’importance de la transition écologique. En effet, les stations de ski connaissent d’importants pics de pollution atmosphérique, notamment les weekends, à cause de l’usage des voitures par les touristes. L’usage des transports publics semble être une solution, ils sont déjà en place, mais les données sont difficilement accessibles. On comprend l’objectif : les données doivent être référencées sur data.gouv.fr pour ensuite être disponibles sur internet via les applications mobiles par exemple. Nous saisissons l’enjeu de communication et l’importance de mettre en avant ces données pour s’assurer que les usagers délaissent la voiture pour les transports public. Les informations doivent être claires pour les touristes et les saisonniers. Après avoir échangé avec notre interlocutrice, nous avons déterminé ensemble les principaux objectifs de la semaine. Nous devons d’abord effectuer une collecte de données relatives aux itinéraires et horaires des bus auprès des différentes communes de l’APTV.
À la suite de l’appel, nous nous répartissons les tâches pour préparer le compte-rendu, prendre de l’avance en contactant les communes et préparer la wishlist. Nous nous accordons pour déterminer une wishlist assez courte du fait de la volonté du client. Finalement, la wishlist se résume en une ligne : nous avons besoin des jeux de données sur les équipements collectifs publics. Pour ce projet de recensement de données, nous nous concentrons ainsi sur les lignes, les horaires des transferts, ainsi que la cartographie des lignes.

JOUR 2 – IDENTIFICATION
Nous avons commencé la journée avec le briefing en salle médiane. Après cette mise au point sur le travail à effectuer en cette deuxième journée, nous nous sommes réunis en D03 autour d’un bon petit déjeuner (merci à Élise pour les viennoiseries).

Nous nous sommes ensuite répartis les tâches de la checklist et avons commencé à travailler chacun de notre côté.
Wendy a mené quelques recherches sur la conversion de données Excel vers Google Sheet, mais s’est rendue compte que cette étape n’était pas utile, car peu importe le format des documents reçus, nous les convertirons directement au format GTFS. Martin, membre du deuxième groupe, s’est occupé de rechercher la manière de convertir nos données en GTFS directement.
Anita a regardé des vidéos pour comprendre les formats GTFS et le format CSV (même si ce dernier ne s’est pas avéré utile pour notre projet).
De son côté, Maëlys a lu et pris des notes sur la documentation du jour, pour savoir comment mener le travail de mise en qualité et pouvoir nous l’expliquer.
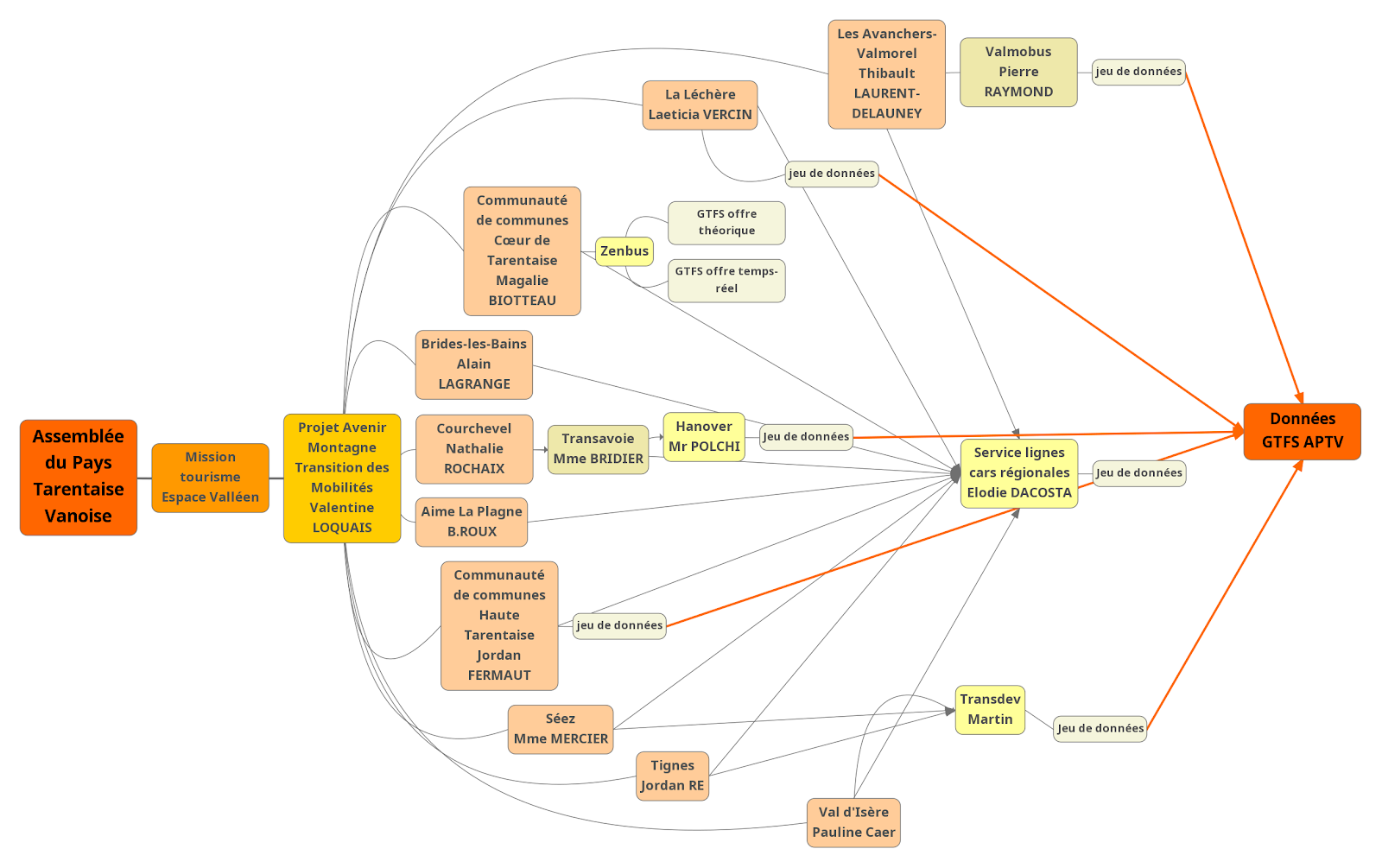
Alexandre s’est occupé une bonne partie de la journée de l’organigramme, puis l’a envoyé à l’autre groupe pour qu’ils complètent avec leurs données. En effet, comme nous travaillons pour la même cliente, il nous a semblé plus approprié de tout réunir sur un même document. Voici donc l’organigramme obtenu à la fin de cette journée :
Lilou et Manon se sont occupées de prendre (voire reprendre) contact avec les communes. Nous avons insisté sur l’urgence de notre demande, et demandé les contacts des transporteurs aux communes que nous avions déjà contactées la veille.
Nous avons plutôt eu du mal à obtenir des informations pour deux raisons majeures. La première est que, bien souvent, nos interlocuteurs confondaient “information” et “donnée”. Nous avons par exemple reçu un mail de notre contact à Brides-les-Bains, qui ne nous a donné que des informations manuscrites quant aux transports de sa ville, mais aucun document PDF. Cela reste donc assez difficile voire impossible à traiter. La deuxième est que nous avons souvent été renvoyées de service en service : chacun se renvoyait un peu la responsabilité et notre quête de données a donc été assez fastidieuse.
Après chaque “session” d’entretiens téléphoniques, Lilou a remis au propre les notes qu’elle avait prises pendant les appels menés par Manon. Cela nous a permis de suivre nos prises de contact avec les communes et de savoir où nous en étions, ce qui nous manquait, et ce qu’il nous restait à faire.

Pendant ce temps, Élise a recherché les lignes de transport sur internet, et transformé les PDF en fichiers Excel. Elle a aussi recherché les données GPS des arrêts.
À 11h30, nos deux groupes se sont réunis pour une réunion avec Étienne, datactiviste. Il a pris le temps de nous dispenser une formation accélérée aux fichiers GTFS : cela nous a été très utile et nous le remercions pour son temps !

Nous sommes ensuite partis déjeuner, et nous avons profité de ce moment pour célébrer les 21 ans d’Anita: un bon moment de partage entre étudiants et tuteurs du Challenge Data qui l’a beaucoup émue.


Ce moment nous a bien motivés pour la deuxième partie de la journée.
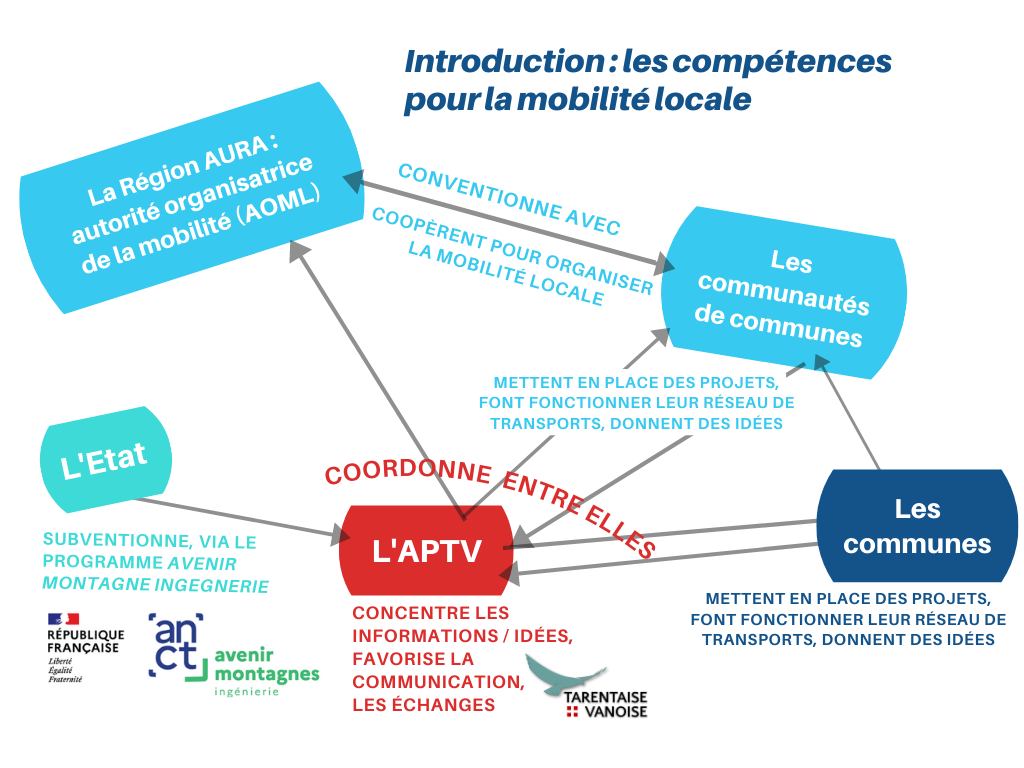
À 14h, nous avons appelé notre interlocutrice pour notre point quotidien. Nous lui avons fait part de nos recherches et de nos difficultés à obtenir des données auprès des contacts qu’elle nous avait transmis. Nous avons pu échanger avec elle, et nous nous sommes rassurés mutuellement sur le fait que toute avancée lui serait utile, et que nous ferons notre maximum pour l’aider le plus possible. Nous avons également profité de cet échange pour lui parler de l’organigramme, et lui demander sa relation avec les communes, car nous ne l’avions pas bien compris. Elle nous a envoyé ce schéma pour nous éclairer, et cela nous a été très bénéfique :
À 14h30, Lilou et Manon ont relancé un appel avec la commune de La Léchère. Nous avons obtenu le contact du transporteur, ABD Voyage, mais cet échange s’est avéré infructueux car le contrat avec la mairie n’avait pas été réitéré pour le moment. Il nous a tout de même donné un autre contact, la Maison de la montagne, et cet appel nous a enfin permis d’obtenir des informations sur les lignes et horaires de La Léchère, qui partent notamment sur d’autres communes alentour.
Élise, Wendy et Anita ont mis en parallèle les données des arrêts récoltés sur internet sur OpenStreetMap. L’idée première était de retranscrire manuellement les latitudes et longitudes de chaque arrêt, mais finalement, ce travail s’est révélé trop long et laborieux, car des arrêts ne sont pas sur la carte ou sont face à face. Pour être plus efficaces, il a donc été décidé avec Clément qu’il retranscrira automatiquement les informations via un logiciel.
Maëlys a importé le jeu de données de la Communauté de Commune Cœur de Tarentaise sur la plateforme Static GTFS Manager.
En fin de journée, voici le point que nous pouvons établir sur les mails reçus au fur et à mesure de la journée:
- Interlocutrice de Courchevel : envoie uniquement des PDF sur les transports et doit envoyer pour les remontées mécaniques, des fichiers GTFS
- Possibilité d’obtenir d’autres données via Hanover mais le contact n’est pas disponible avant mercredi après-midi. Il se pourrait néanmoins que les données nous soient directement envoyées en GTFS.
- Valmobus : nous recevons les PDF des horaires et arrêts
- Brides-les-Bains : aucune donnée, aucun PDF
- La Léchère : aucune information venant de la mairie
- Liste des arrêts et horaires obtenus grâce à la Maison de la montagne
-
Communauté de commune Coeur de Tarentaise : envoi des documents qui étaient déjà sur internet
Élise a élaboré la “wanted data list” :
➤ Agency
➤ Calendar
➤ Routes
➤ Stops
➤ Stops Times
➤ Trips
En fin de journée, nous avons pris de l’avance pour le lendemain. Le deuxième groupe nous a transféré une liste de données d’arrêts (latitudes et longitudes), afin de les référencer et de trouver leurs noms, s’il y en avait. Parmi les 14 membres, nous nous sommes répartis le travail, puis mis les données sur Google Maps et trouvé le nom des arrêts en explorant Google Maps Street View.
Nous avons terminé cette journée par une session “team building” avec Clément, avec un jeu de société : ce moment nous a bien détendus de notre journée!

JOUR 3 – MISE EN QUALITÉ
Nous avons commencé par le briefing en salle médiane à 9h. Après cette mise au point avec tous les référents et étudiants, nous nous sommes retrouvés en salle D03 pour commencer la journée. Pour la débuter de manière convenable, Manon a décidé de nous régaler avec un petit déjeuner et des boissons qui nous ont aidés tout au long de la journée.
À 9h15 avec toute l’équipe nous avons décidé de faire un point sur les documents en notre possession et sur nos documents manquants afin d’avancer de manière efficace en début de matinée.

Alexandre a pris l’initiative de prendre les directives pour ce check up et Anita s’est occupée de noter les personnes qu’il fallait recontacter.
État des données
- Les Avanchers Valmorel : nous avons des données au format PDF
- La Léchère : il faut recontacter la maison de la montagne car nous n’avons toujours pas reçu les données
- Brides-les-bains : le contact ne nous a fourni aucune donnée, nous faisons une croix sur cette commune
- Courchevel : nous avons des données au format PDF (un contact doit nous les renvoyer au format GTFS dans la journée)
- Coeur de Tarentaise : les données sont au format GTFS et déjà traitées
Dès lors, nous nous répartissons les tâches.
Lilou a rappelé la maison de la montagne, pour les relancer, il y avait une erreur de saisie dans son mail, ils nous ont finalement envoyé les données.
Alexandre a rappelé le commercial de Zenbus à Valmorel qui pourrait nous fournir les données en GTFS de Valmorel et Brides-les-bains. Toutefois, cela reste des prospections.
Lilou et Manon ont contacté Altibus afin d’avoir leur directrice pour qu’elle puisse donner l’autorisation aux membres d’Altibus de nous donner les données. Toutefois nous n’avons pas reçu davantage de données.
Pendant ce temps, Anita et Maylis ont commencé à apprivoiser la wanted data list afin de savoir quelles informations étaient nécessaires. Elles se sont rendues compte qu’effectuer les trajets des lignes et retrouver les arrêts correspondants n’allait pas être chose aisée. Dès lors, elles ont fait appel à Clément afin de les éclairer. Il a alors proposé de leur faire une cartographie avec tous les arrêts renseignés la veille. Afin d’avoir un visuel ou les arrêts apparaissent. Pour se servir de ce document comme appui dans cette tâche.
La carte qui nous a servi de point d’appui :

Ensuite nous avons refait un point aux alentours de 10h30 pour faire état des lieux. Puis nous nous sommes organisés pour rentrer les données dans la wanted data list.
Tout d’abord nous avons rempli le fichier agency.txt pour mettre les informations au même format que l’autre équipe avec laquelle nous collaborons. En termes d’organisation, Clément nous a expliqué ce qu’il était plus logique de faire.
Organisation
- Une personne remplit le fichier route.txt : chacune des lignes de bus qui nous intéressent
- On se répartit chacun une ligne de bus (fichier route.txt) : ex b51
- On remplit le fichier trips.txt id aller à quelle heure (dire quelle ligne par quel jour) : ex B51 lundi mardi mercredi..
- On remplit les arrêts (la partie la plus longue lorsqu’il y a beaucoup d’arrêts)
Toutefois nous avions un dilemme face à nous : quelles données traiter ? En effet nous avions l’espoir de recevoir en début d’après-midi les données au format GTFS de deux des exploitants relatives à deux communes, dès lors pour optimiser notre temps nous avons décidé de nous concentrer sur les données relatives à La Léchère car c’était celles en PDF et nous étions sûrs de ne pas recevoir celles-ci en GTFS.
Pour nous acclimater à la saisie de données sous un format quelque peu étranger pour nous, Clément nous accompagne pour le premier exemple. Tous ensemble nous avons effectué un exemple sur une navette qui dessert la Léchère.
Les étapes
Le remplissage des données a pu se faire grâce au PDF introductif au format GTFS
- document agency.txt : pour commencer nous trouvons l’agence qui fournit cette navette, nous créons des identifiants courts et ajoutons le lien URL relatif à cette agence.
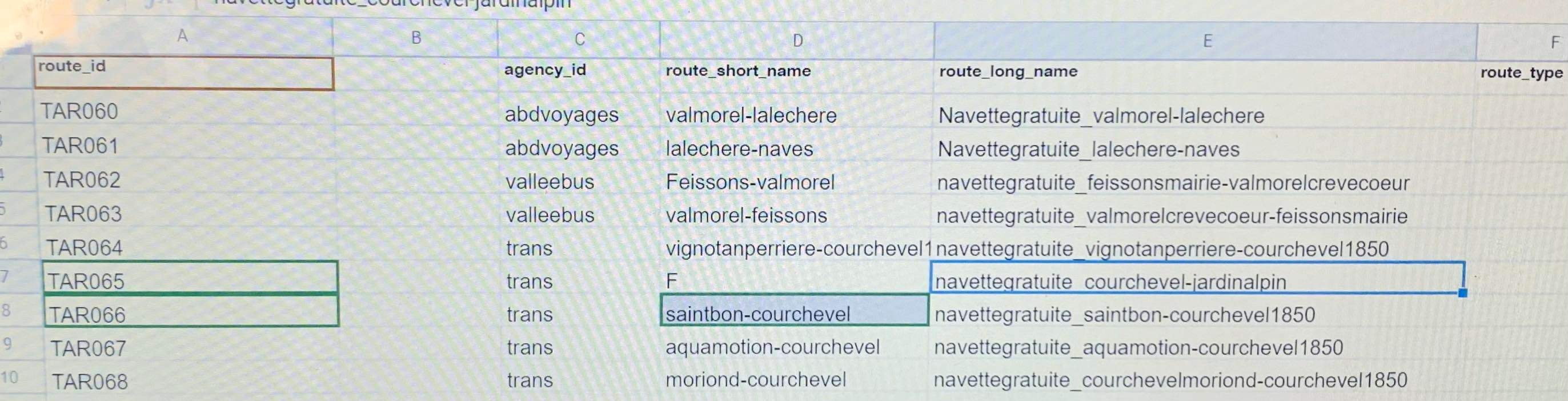
- document routes.txt : à l’aide du PDF nous évaluons combien de trajets identiques (aller ou retour) sont effectués, dès lors nous identifions 2 routes pour le cas de La Léchère, ainsi nous créons des identifiants de routes au format majuscule TAR60 par ex et nous prenons le soin de garder des formats identiques avec l’équipe avec laquelle nous travaillons de concert, pour trouver le type de route nous retrouvons sur le PDF -tuto envoyé la veille par notre interlocuteur qui nous a initié au format GTFS que l’identifiant des routes est le numéro 3.
- ensuite nous passons au fichier trips.txt : tout d’abord il faut mettre la route empruntée, mettre quel jour cette ligne de bus est disponible, pour finir pour trouver l’identifiant du trip il faut mettre le nom du terminus puis l’heure d’arrivée
- Pour finir nous passons au document stop_times.txt : il faut l’identifiant du trip, l’heure d’arrivée, l’heure de départ, l’identifiant de l’arrêt et numéroter l’arrêt en fonction de sa place dans le trajet.
Il a fallu comprendre le nombre de routes pour chaque trajet, à savoir que des trajets dans des directions inverses mais qui font les mêmes arrêts forment une même route. Par exemple pour La Léchère il y a avait 2 routes possibles. Pour remplir la wanted data list nous avons commencé par le fichier Excel sur les agences, puis les routes, puis les trips, puis les stoptimes.
Maëlys, Alexandre et Anita ont débuté la mise en forme des données relatives à La Léchère. Maëlys et Alexandre ont notamment retrouvé les noms des arrêts grâce à la carte réalisée par Clément avec les arrêts. Puis Anita et Wendy se sont occupées de remplir dans la wanted data list les 4 derniers trajets relatifs aux données de La Léchère. Elles ont entré les horaires d’arrivée, de départ, les jours où les bus circulent et référencé les arrêts.
Puis nous avons eu un débat sur le nombre de routes à entrer car selon le calendrier, les horaires ont changé, nous avons gardé une route pour les mêmes trajets car les nuances seront faites dans la wanted data list calendar.txt.
Ensuite à 12h30 nous avons contacté notre référente de la collectivité par téléphone pour faire un point sur la situation. Nous avons recensé avec elle les données que nous avons et celles qui nous manquent puis nous lui avons expliqué notre programme de la journée, à savoir répertorier chaque ligne de bus puis les mettre au format GTFS.
Nous avons ensuite poursuivi l’entrée des données dans la wanted data list.
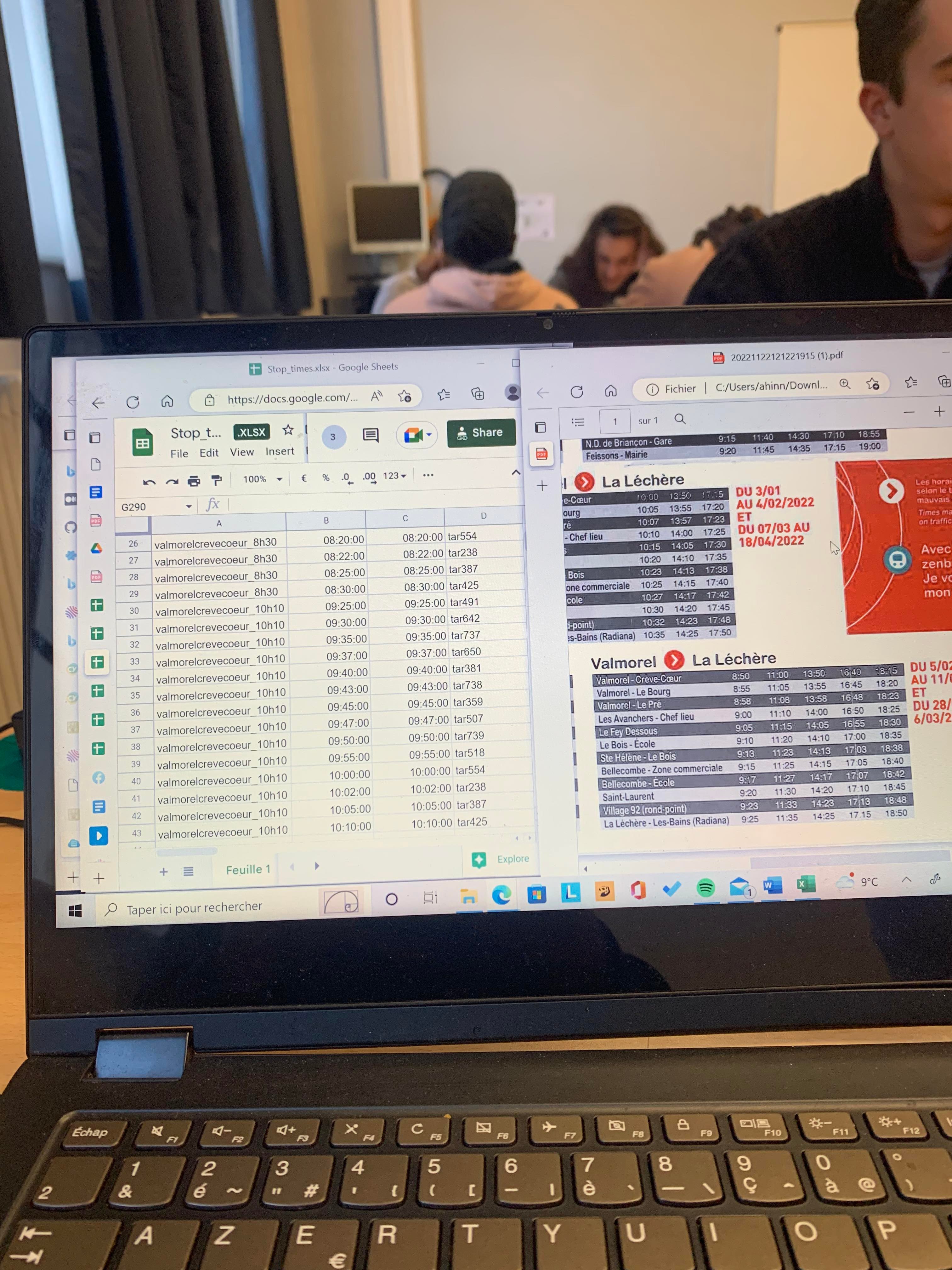
A 13h, Lilou et Manon ont contacté un membre de Hanover qui nous a renvoyé vers un autre interlocuteur qui nous a donné le numéro d’une dernière interlocutrice. Après des promesses de fichiers en GTFS nous avons finalement reçu des données en CSV pour Courchevel et pas de nouvelles données au format GTFS pour les Avanchers Valmorel. La sentence était irrévocable il fallait poursuivre la retranscription du document PDF pour Valmorel au moins. Alexandre s’est chargé de la première partie du document et Wendy et Anita ont fait la seconde. Il y a eu un débat sur le fait de mettre plusieurs nombres de routes lorsque les lignes ne circulent pas à la même période mais après mûre réflexion, nous avons compris qu’il fallait seulement mettre plusieurs routes lorsque le nombre d’arrêts étaient différents.
Sur la photo on peut voir la wanted data list (stop_times.txt) avec le document PDF de Valléebus qui permet d’avoir les données.
Si nous n’avons reçu aucune donnée au format GTFS, Manon a finalement eu des membres de la compagnie Transdev qui nous ont envoyé des données au format CSV relatives à Courchevel. Pour réussir à faire les liens et clarifier le tout sur la wanted data list, Clément nous a aidé à trier les documents reçus en CSV. Ensuite, nous avons continué de traiter les données des Avanchers Valmorel. Toutefois nous avons été face à un dilemme. Poursuivre la saisie manuellement des données pour Courchevel (sachant que celles-ci étaient à jour) et que nous maîtrisons désormais la saisie de données ou utiliser les données datant de l’année dernière au format CSV sans notion sur ce dernier (et il fallait aussi faire correspondre les noms d’arrêts donnés avec les noms des arrêts sur les fichiers). Après une réflexion collective nous avons décidé de poursuivre la saisie manuellement car avec de l’organisation et des membres efficaces nous étions optimistes.
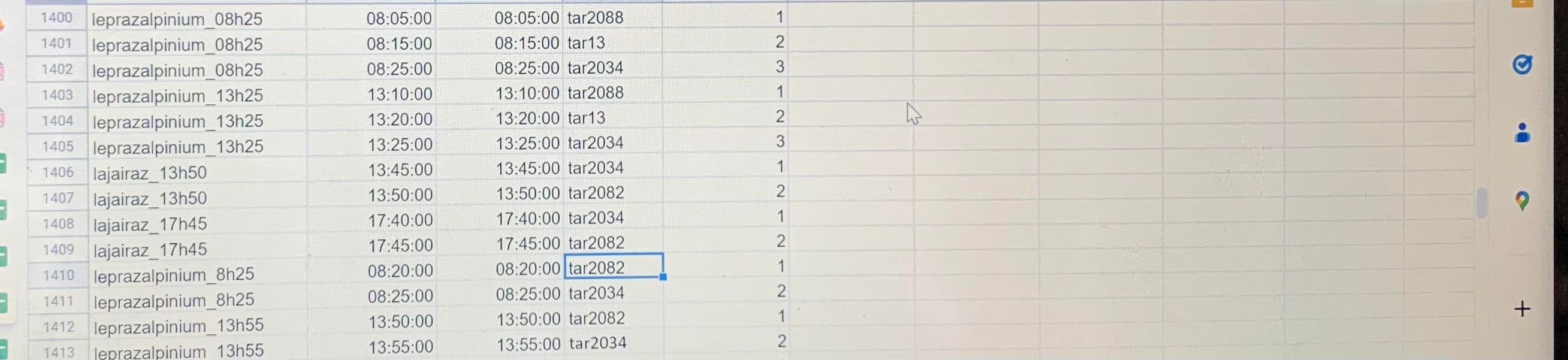
A 16h il nous reste à exploiter les données de bus de Courchevel au format PDF donc nous nous répartissons les différentes routes à nouveau. Nous avons droit à une pause goûter en salle médiane, préparée par nos référents. Toute l’équipe est au complet pour parvenir à finir de rentrer toutes ces données avant la fin de la soirée. Nous nous divisons les 3 PDF de Courchevel avant-saison, moyenne saison et haute saison, toute l’équipe est au point et c’est 4 h de grande efficacité qui se poursuivent.
Elise explique à Anita et Lilou comment retrouver les arrêts “tar” lorsqu’elles ont fini de rentrer toutes les données dans le document stop_times.txt. Pendant que chaque membre participe au document stop_times.txt, Alexandre s’occupe de créer les routes et les trips de la wanted data list. Pour chaque PDF, il a regardé les terminus de chaque trajet pour savoir combien de routes il fallait créer. Il a ensuite créé le nombre de routes qu’il fallait dans le document routes en associant leurs identifiants et leurs noms. Ensuite dans le document trips.txt il a regroupé tous les trajets qui correspondaient aux mêmes routes en indiquant quels jours elles étaient disponibles. En tout 907 trips ont été créés.
JOUR 4 – PUBLICATION
La journée commence sur les chapeaux de roues. Nous avons beaucoup de travail devant nous pour finir la traduction des horaires des PDF sur Excel, dans l’optique de les transférer - enfin - au format GTFS. Certains d’entre nous ont dû travailler la nuit dernière pour avancer sur le travail. Dans la matinée, les objectifs normaux du “jour 4” (communication, création du compte pour data.gouv.fr,…) nous paraissent lointains : nous avançons efficacement malgré tout. Le fait qu’Allyson ait reconnu devant l’ensemble des groupes la nouveauté et la difficulté de l’exercice auquel nous sommes confrontés avec le groupe 8 a probablement contribué à nous booster pour la journée !

Le groupe vit très bien malgré ce flot ininterrompu d’horaires de bus à traiter, les tâches se répartissent équitablement et chacun trouve sa place. Pendant qu’Alexandre, Elise, Manon et Wendy terminent de remplir les fichiers des horaires, Maelys, Lilou et Anita réfléchissent au plan de communication. Aux alentours de 12h30, les 7 Excels de notre wanted data list sont enfin complétés et transmis à Clément dans l’espoir qu’ils soient exploitables ! Dans la foulée, nous avons repris contact avec notre interlocutrice pour qu’elle nous explique plus précisément ses attentes en matière de communication. Elle nous a demandé de réaliser des cartes interactives avec arrêts et horaires, par ville et par ligne. Elle souhaite aussi un document encourageant à utiliser le bus, doté d’un lien renvoyant aux cartes interactives. Avant la pause déjeuner, Clément nous a annoncé que nos jeux de données étaient passés sur le format GTFS, mais avec un grand nombre d’erreurs qu’il va falloir résoudre rapidement pour tenir les délais.
Elise a commencé à remplir les fiches descriptives des jeux de données, mais face à la complexité des erreurs que nous avons à traiter nous nous sommes rapidement rendus compte qu’il était inutile de le faire pour l’instant. Le résultat du premier filtre avant que nos données ne soient acceptées au format GTFS donne à voir un grand nombre de corrections à effectuer, et nous décidons donc de tous nous pencher sur le sujet pour être efficaces.

C’est à ce moment que nos camarades des autres groupes sont venus en nombre nous proposer leur aide, et même s’ils n’étaient pas en mesure de nous aider réellement, leur présence ainsi que celle d’Allyson et Clément nous a rassuré sur le fait que notre situation était bel et bien d’une complexité inédite.
Au final, la question se résout assez rapidement, et en l’attente d’une validation de l’entrée au format GTFS, Maëlys, Manon et Lilou se penchent sur la communication. Sauf que le résultat du GTFS aboutit à plusieurs centaines d’erreurs et de doublons supplémentaires à traiter, ils témoignent de deux choses :
- la difficulté de manœuvrer des données en grande quantité (d’une faible complexité prises individuellement)
- la difficulté de coordonner et d’homogénéiser les productions d’un groupe de 7 personnes
- le fait qu’en “codage”, la moindre erreur ou la moindre mauvaise habitude se paie de plusieurs heures de travail supplémentaires.
À 16h30, nous étions donc encore en train de rectifier les données corrompues, à l’exception de Maëlys partie prêter main forte au groupe 8. En effet, cette journée a aussi été marquée par une collaboration plus étroite avec ce groupe qui partage notre mission. Leur avance leur a permis de réaliser la création de compte data.gouv.fr et d’avancer sur la communication (avec l’appui de Maëlys) puisque ces tâches doivent être réalisées en commun. L’organigramme, commun lui aussi, est cependant à la charge d’Alexandre qui le met à jour régulièrement.

Vers 17h30, le fait d’avoir terminé les corrections, sans même savoir si elles permettraient un fonctionnement effectif sur GTFS, nous a bien remotivé au vu de l’heure avancée !
En fin de journée, nous avons bien avancé avec l’autre groupe sur les souhaits de notre interlocutrice en termes de communication. Son souhait d’affiche munie d’un QR code relié à une carte interactive (contenant itinéraires et arrêts de bus) est en travaux, la carte est le seul élément qui reste à faire. En termes de communication externe, nous souhaitons réaliser un communiqué de presse détaillant les causes et les enjeux de notre démarche dans le cadre du Challenge Data. De fait, le plan de communication et la fiche descriptive ont été remplis en collaboration avec le groupe 8. Nous tenons à saluer et à remercier chaleureusement nos camarades de ce groupe qui se sont montrés très compréhensifs et ont assumé la majorité des tâches communes à nos deux groupes (comme par exemple la création et le don du groupe data.gouv.fr), reconnaissant ainsi que notre cas nécessitait plus de travail que le leur déjà bien complexe.
A 18h50 Elise et Alexandre finissent enfin les dernières résolutions d’erreurs du jour pendant que Maelys termine le communiqué de presse ! L’équipe a hâte de voir quel sera le rendu concret d’autant de travail sur les données.
JOUR 5 – VALORISATION
Dans la matinée, l’équipe de communication composée de Maëlys, Lilou et Manon poursuivent la création d’affiches sur Canva afin de promouvoir une mobilité durable au sein de la région. Wendy poursuit le communiqué de presse pour le diffuser en interne aux autres communes de la région. Notre interlocutrice souhaite avoir des affiches pour pouvoir les diffuser au sein de l’espace public afin d’inciter les citoyens à utiliser les transports en commun au lieu de la voiture. Nous avons réfléchi à des slogans attractifs pour promouvoir la mobilité durable. On a également décidé d’effectuer 4 affiches déclinées selon le calendrier estival.




Pendant ce temps, Alexandre, Anita et Elise continuent à corriger des erreurs sur le fichier Excel avec l’aide de Clément. La tâche est ardue mais les mots d’encouragements d’Allyson sur l’intérêt et la pertinence de l’ouverture de nos données pour la collectivité ont motivé nos troupes !
Après avoir passé la matinée à corriger les erreurs contenues dans les données excel, l’équipe avec le soutien de Clément parvient à les résoudre et à convertir le fichier Excel en GTFS. Nous sommes heureux d’enfin voir nos données en GTFS. La joie est à son comble !

Par la suite, Elise s’occupe de publier les jeux de données sur data.gouv.fr. Nous devons désormais nous atteler à réaliser des datavisualisations pour illustrer notre démarche tout au long de cette semaine.
D’un côté, Manon, Maëlys et Lilou effectuent une carte interactive avec l’assistance de Clément tandis que le reste de l’équipe répertorie les informations (villes concernées, lignes de bus, trajets, horaires, transporteurs, durée du trajet) et les formats (graphique, diagramme) sous lesquels on veut mettre en valeur nos données. Une fois la carte interactive réalisée, nous avons pu réaliser le QR code voulu par notre interlocutrice renvoyant à la carte. Nous avons par la suite introduit ce QR code sur chaque affiche de communication produite en amont. Ce QR code permettra à notre interlocutrice d’effectuer une communication interne c’est-à-dire aux autres communautés de commune afin qu’elles se rendent comptent concrètement de l’utilité de l’ouverture des données concernant les transports. Ce QR code permettra également une communication externe car la carte interactive peut éventuellement aider les usagers.
L’après-midi, nous débutons la partie valorisation de nos données. Anita, Alexandre et Wendy effectuent les différentes datavisualisations de nos données en coordination avec le groupe 8.
Elise et Maëlys se tâchent de remplir le contexte de datavisualization. Lilou et Manon préparent le diaporama en vue de la présentation orale que nous allons effectuer devant l’interlocutrice de notre région à 17h.
Alexandre a pu finaliser l’organigramme. Celui-ci sera transmis à notre interlocutrice.
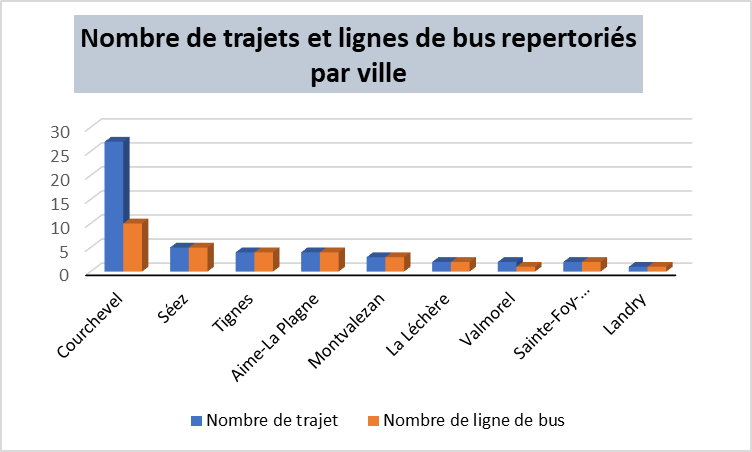
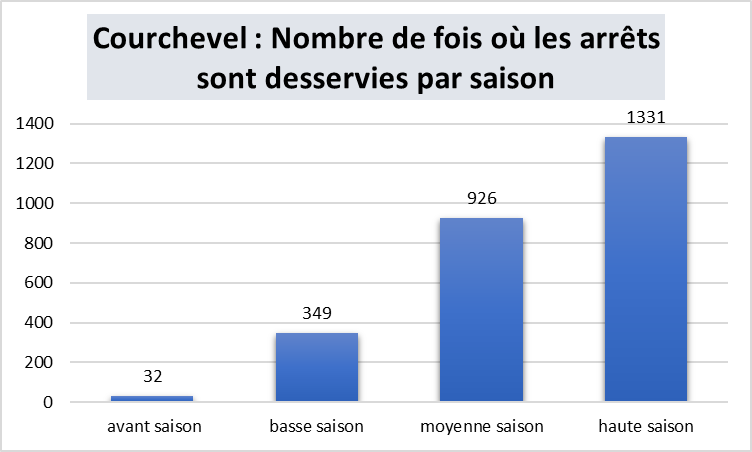
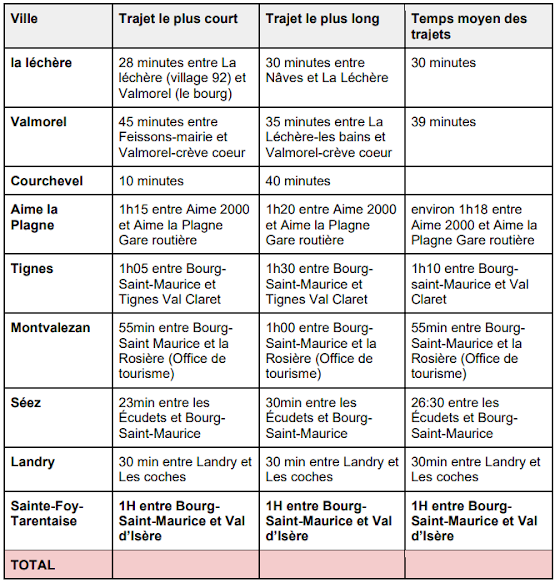
Nos datavisualisations
Scanner le QR code pour avoir accès à la carte interactive

Lien vers le contexte de la datavisualisation : https://docs.google.com/document/d/1gC7GhssuQ4YgyHUxAWdZP4eQaUhaLxDr/
https://docs.google.com/document/d/1zXRhwZsFYTZX_s6fRb5FeK5jgOEyHcUV/
En fin de journée, nous avons eu notre dernier appel avec notre interlocutrice. On a pu lui présenter l’ensemble de notre démarche sur toute la semaine. Ce récapitulatif en commun avec le groupe 8 nous a permis de reconstituer pas à pas chaque étape jusqu’à l’ouverture des données. Ci joint, vous pouvez retrouver le lien du diaporama réalisé qu’on a présenté à notre interlocutrice. https://docs.google.com/presentation/d/1TqS_l7STS1oRcJbjpClOLheZ_vOSU0WRtwOzo-_Vf3Q/ .
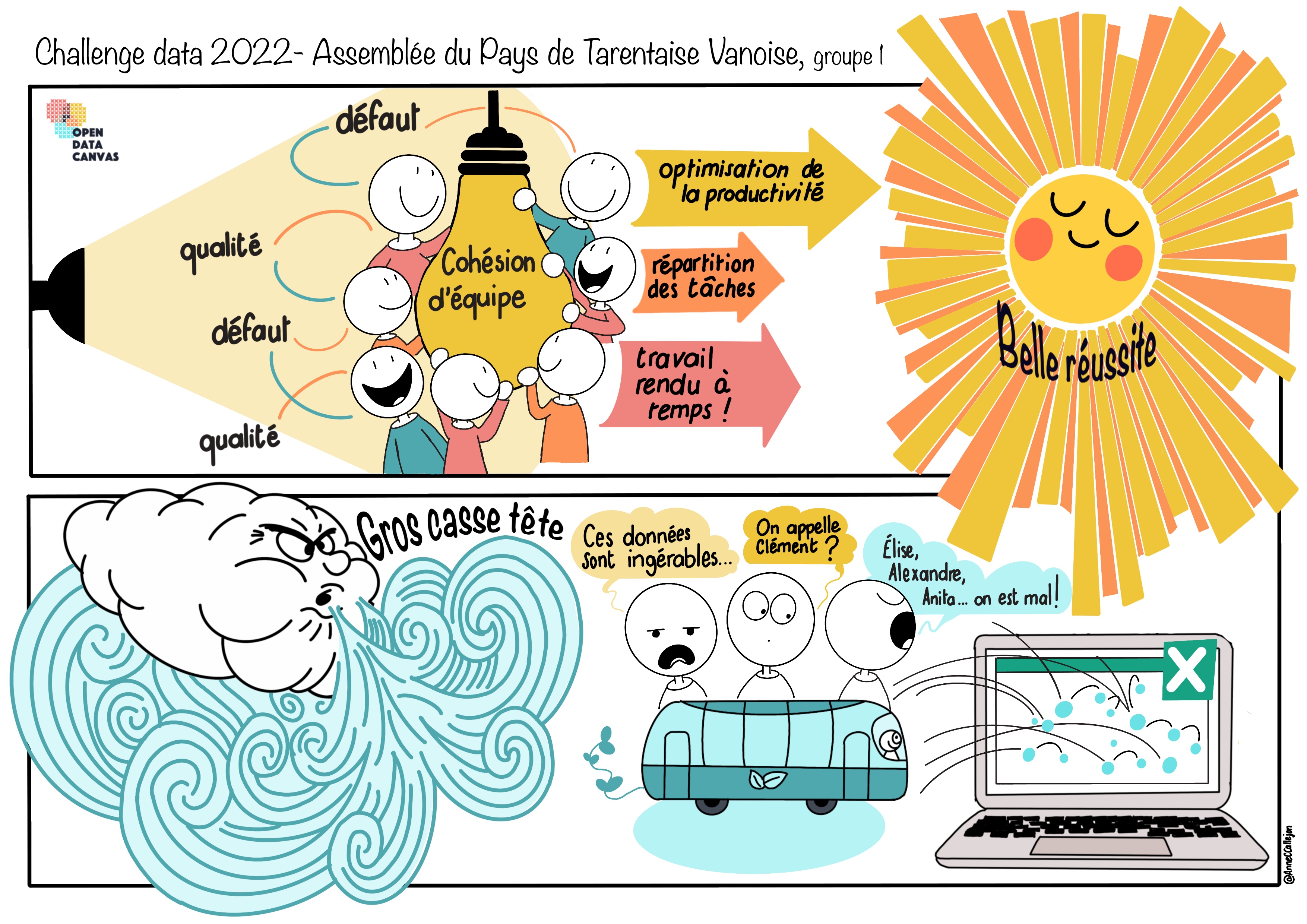
CONCLUSION
Pour conclure, cette semaine de challenge data fut riche en travail, mais resta dans l’ensemble très positive.
D’une part, nous avons été confrontés à l’utilisation de “jeux de données”. Nous n’en avons ouvert qu’un (équipements collectifs publics), mais celui-ci contenait énormément de données. Nous avons fait face à de nombreux freins et notamment en début de semaine où le contact avec les transporteurs, les sous-traitants ainsi que certains membres des collectivités fut un peu difficile pour différentes raisons telles que le manque de sensibilisation de ces acteurs à l’ouverture des données et la confusion entre “données” et “informations”. D’autre part, l’un des freins principaux que nous avons rencontré fut à partir du mercredi quand il fallut rentrer les data sur nos différents templates Excel, l’intégration de l’automatisme et l’adaptation face aux différenciations entre les lignes.
Ce qui nous a beaucoup aidé durant cette semaine était la présence et la motivation de notre interlocutrice qui dès le début a été très claire sur ses demandes et qui s’est rendue disponible tout au long de nos journées. Clément, notre encadrant, a également été d’un grand soutien en répondant à chacune de nos questions et en s’occupant de certaines tâches plus ardues. Le fait d’être deux groupes sur cette mission était également un avantage considérable.
En tant qu’étudiants en sciences politiques, cette expérience nous a appris le processus de l’ouverture et du traitement de données. L’importance des données dans la vie des citoyens et comment celles-ci peuvent être utilisées pour améliorer la qualité de vie de ceux-ci. Le travail d’équipe fut également un gros enjeu puisque malgré de nombreux travaux de groupes dispensés à l’école, il est rare que nous devions travailler de manière aussi intensive et condensée avec 7 personnes.
Notre plus gros frein fut la correction des erreurs sur les données Excel qui étaient extrêmement nombreuses, qui prit énormément de temps et dont nous n’aurions jamais pu arriver à bout sans l’aide de Clément mais également sans le dévouement d’Elise, Alexandre et Anita à régler ce problème.
Enfin, notre plus belle réussite fut certainement d’atteindre une belle cohésion d’équipe alors que nous ne nous connaissions pas forcément au préalable. Nous avons réussi à jouer des qualités et des défauts de chacun afin d’optimiser notre productivité et notre répartition des tâches et d’arriver au bout de cette semaine en rendant notre travail dans les temps.
