Carnet de bord de l’ouverture des données de la Mayenne
par AASLI Jibran, ABOUBAKAR Nahia, KORCHANE Angla, MADRELLE Lucas, VASQUEZ Elena, DUBIEF Louis, DOSIMONT Claire

INTRODUCTION

Le lundi 21 novembre à 8h45, c’était le coup d’envoi de la 5ème édition du #ChallengeData animée par Datactivist, pour lequel nous avons créé des groupes mixtes qui seraient nos groupes de travail pendant la semaine. Notre groupe regroupe 7 personnes, 4 filles et 3 garçons dispersés dans les quatre blocs de spécialisation de M1 de notre école, dans l’ordre alphabétique il y a : Jibran, Nahia, Claire, Louis, Dounia, Lucas et Elena. Nous avions quelques appréhensions avant cette semaine, parce que le monde des Data nous paraissait flou, malgré la journée Data et territoire que nous avons eue en 2ème année, animée par Datactivist déjà. Celle-ci remontait à il y a deux ans et sa courte durée n’a pas aidé. Nous avions aussi eu des échos et souvenirs des promotions précédentes dont certains groupes avaient grandement été mis en difficulté par la collecte de données dans leur commune. Ce qui nous ravissait par avance en revanche, c’est de se retrouver sur la plateforme Gather!, un hybride de Habbo et Zoom, plus professionnel que Habbo et moins formel que Zoom. La première réunion sur Gather nous a rassurés sur la semaine à venir, éclaircissant la nature du travail que nous allions fournir. Le grand soulagement, cela a été la découverte de la collectivité sur laquelle nous allions travailler : le Conseil Départemental de la Mayenne. Une grande collectivité dont l’assise est déjà large, c’était sans doute pour nous une collecte des données plus facile car déjà existantes. Avant cette semaine de #ChallengeData, nous avions donc quelques doutes sur le déroulement serein de ces cinq jours mais par chance, les quelques jours précédent le lancement nous ont rassuré et mis dans un bon état d’esprit …!

JOUR 1 – DIAGNOSTIC
Nous avons premièrement pris connaissance de la collectivité qui nous avait été attribuée. Il s’agit du Conseil Départemental de la Mayenne. Nous nous sommes ensuite installés dans notre salle de travail et avons commencé à rédiger ces quelques lignes sur le carnet de bord qui nous a notamment aidé à organiser nos journées.
Nous avons par la suite procédé à quelques tâtonnements sur le site opendatacanvas et avons entamé la lecture de la méthodologie. En attendant le rendez-vous avec notre interlocutrice qui était déjà planifié afin de compléter le questionnaire avec la collectivité pour établir le diagnostic, nous avons pris les informations générales sur la collectivité. Nous avons entamé des recherches de renseignements sur les élus, la sociologie du vote, des transports publics, sur l’emploi et aussi un organigramme de la collectivité. Nous avons rapidement remarqué que pas mal de données sont disponibles.
Dans une bonne ambiance, nous nous sommes ensuite réparti le travail en consultant le questionnaire afin de pouvoir adapter nos questions à notre interlocutrice. Nous avons ensuite trouvé un lieu calme dans l’IEP afin de pouvoir nous entretenir avec notre interlocutrice dans les meilleures conditions possibles. Le rendez-vous à 14h avec notre interlocutrice a été très fluide, nous avions beaucoup de questions à lui poser et elle a pu répondre à toutes nos questions, en nous décrivant de plus la situation de l’open data au sein de la collectivité. En effet, l’intervenante a une très large connaissance sur l’open data, chaque réponse a été développée de manière très claire. Nous comprenons rapidement les intentions concernant l’ouverture des données et les enjeux de la transition écologique qui sont centraux, qui vont donc être notre source de travail. De plus, nous avons durant cet entretien fixé les rendez-vous quotidiens pour le reste de la semaine (14h tous les jours).
Après l’entrevue, nous avons organisé nos réponses afin de répondre au questionnaire. Ce dernier a permis de jauger la maturité de notre collectivité qui est actuellement située au niveau 3, ce qui nous a paru cohérent avec nos premières impressions.
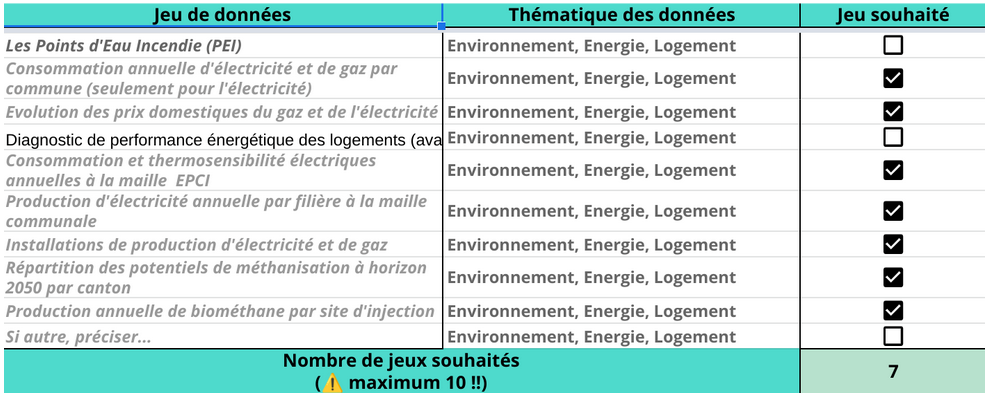
Par la suite, nous avons consulté les jeux de données que notre interlocutrice nous a fait parvenir via e-mail et nous avons pré-sélectionné les catégories qui nous semblaient être pertinentes au regard de l’objectif. Nous en avons sélectionné cinq, soit : 1.Consommation annuelle d’électricité et de gaz par commune (seulement pour l’électricité), 2.Consommation et thermosensibilité électriques annuelles à la maille EPCI, 3.Production d’électricité annuelle par filière à la maille communale, 4.Installations de production d’électricité et de gaz, 5.Répartition des potentiels de méthanisation à horizon 2050 par canton.
Enfin, nous avons fait parvenir ces choix à Madame X qui les a validés. Nous sommes rentrés chez nous avec une attitude optimiste aux vues des tâches qui allaient nous être confiées.
Wishlist, groupe 19. Conseil Départemental de la Mayenne.
JOUR 2 – IDENTIFICATION
Après une brève présentation des attendus de la journée par l’équipe de DatActivist, nous nous sommes mis au travail - avec un café bien mérité. La première chose à faire étant de répondre à notre interlocutrice au sein du département de la Mayenne chargée de la gouvernance de la donnée. La journée d’aujourd’hui était dédiée à l’identification. Cette première partie est essentielle dans le processus menant à l’ouverture des données puisqu’elle prend en compte la recherche de données et leur pertinence. En ce qui nous concerne, nous avons été plutôt chanceux car Madame X avait d’abord des besoins précis qui s’incarnent dans la mise en qualité, la publication et la valorisation des données relatives à la transition écologique. Mais également car les données ouvertes sont déjà à l’œuvre au sein du département et ce grâce au travail de Madame X et plus largement de la Direction de la Transformation et de l’Innovation.
Nous avons recueilli auprès de Madame X huit jeux de données relatifs à la consommation et production énergétique au sein du département . Ces jeux de données ont pour but de mettre en place une forme de transparence des données de la collectivité tout en pensant à des solutions plus durables et écologiques. Ayant présélectionné hier plusieurs jeux de données, nous avons poursuivi sur cette lancée. Nous avons donc procédé à une répartition des jeux de données en établissant un ciblage par pertinence sur la période. Partant de là, nous avons constaté quelles données étaient les plus complètes afin d’établir un ordre de priorité et de possibilités suivant le code couleur expliqué ce matin. Nous avons donc - avant le déjeuner - estimé que les données relatives à la consommation d’électricité par gaz et par commune ainsi que la production d’électricité annuelle par filière à la maille communale étaient à la fois les données les plus complètes et les plus pertinentes sur la thématique abordée. Aussi, Madame X nous a transmis un jeu de données relatif aux factures énergies/fluides en Mayenne de janvier 2015 à décembre 2022 sur les propriétés privées ainsi qu’un deuxième traitant du même sujet pour les collèges. Au vu de l’épaisseur du document ainsi que du nettoyage conséquent qu’il demanderait, nous avons décidé à la mi-journée d’écarter les données relatives au patrimoine. Cette pré décision se confirmera ou non en début d’après-midi après notre entrevue avec Madame X. En fin de matinée, nous avons également rempli les autorisations de publication CCBYSA dont le but est de permettre la mise en place de droits de propriété intellectuelles plus souples dès lors qu’il est question de l’intérêt général. Ces autorisations permettent de publier les données recueillies en licence libre, partie essentielle pour permettre une participation plus ou moins universelle à l’Open Data.
Enfin, nous avons établi l’organigramme des données transmises depuis hier par notre interlocutrice.
Cet après-midi, nous avons eu un entretien avec Madame X concernant les jeux de données sélectionnées. Nous avons donc pu évoquer le problème d’actualisation sur le site data.gouv du découpage cantonal. En effet, le site n’est plus à jour depuis le découpage de 2014, chose qui complique le filtrage optimal des cantons établi en 2015.
Madame X nous a confirmé le nombre d’établissements publics de coopération intercommunale (EPCI) ainsi que le nombre de communes présentes sur le département. Enfin, nous avons revu le nombre de jeux de données à la hausse pour traiter sept des huit jeux de données fournies par la chargée de la gouvernance de la donnée du département.
Avec ces informations, nous avons donc commencé à prendre de l’avance sur la séance de demain concernant le traitement des données. A la fin de la journée et grâce aux échanges menés avec notre interlocutrice, nous avons pu mettre à jour l’organigramme de nos données et établir notre wanted data list finale.
Organigramme des données, groupe 19. Département de la Mayenne
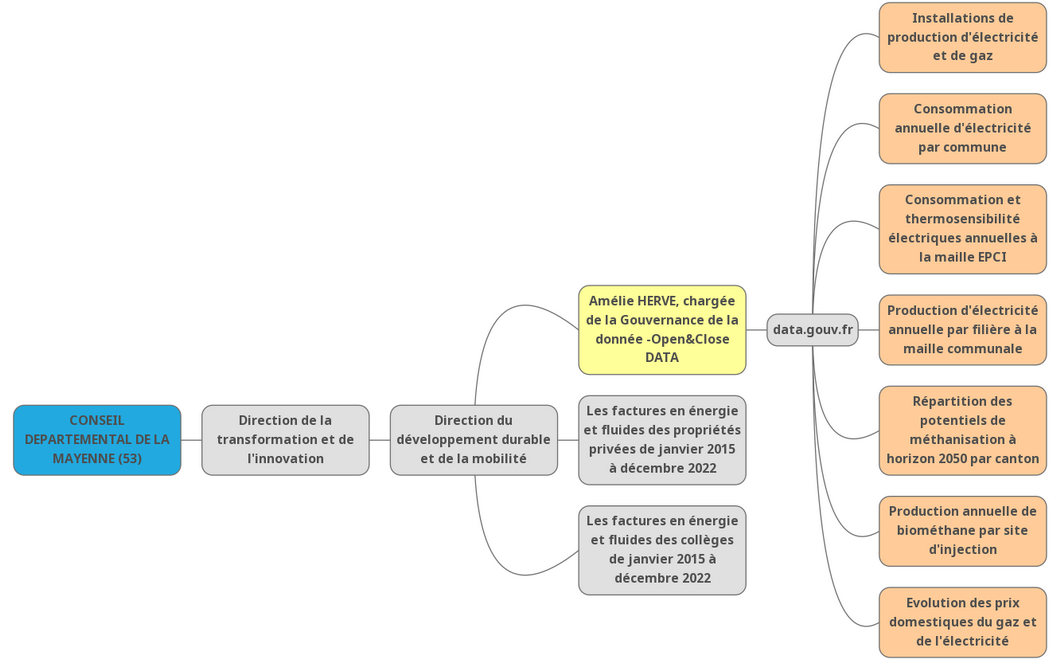
Évaluation des données et wanted data list, groupe 19. Département de la Mayenne

JOUR 3 – MISE EN QUALITE
Après une brève présentation des attendus de la journée par l’équipe de DatActivist, nous nous sommes mis au travail. Nous avons pris ensuite un café afin de nous booster durant la journée. Nous avons par la suite entamé la lecture de la documentation, analysé les tutoriels de présentation pour la journée. Nous nous sommes ensuite réparti les jeux de données. Chaque personne du groupe était chargée du nettoyage et de la mise en qualité des jeux de données. Pour la plupart, le nettoyage était assez rapide et nous n’avons pas rencontré de réelle difficulté dans la mise en qualité. Sauf pour un jeu de données, où nous avons rencontré une complication, les données de la répartition des potentiels de méthanisation à horizon 2050 par canton, nous a ralenti dans la réflexion de son nettoyage. En effet, ce jeu de données n’est pas propre, il prend en compte un découpage cantonal non-conforme à la réforme de 2014. Les cantons sont découpés en 32 au lieu de 17, et par manque d’informations, nous sommes restés bloqués dans l’attente d’une clarification de notre interlocutrice pour répondre à notre problème. Nous avons donc fixé avec elle, un rendez-vous sur Gather à 14h. Nous étions donc dans l’attente du rendez-vous avec notre interlocutrice après avoir fini le nettoyage des données. Nous en avons profité pour prendre une pause déjeuner.
Lors de notre entretien quotidien avec notre interlocutrice, nous avons pu lui faire un compte-rendu de notre avancée et aussi lui expliquer notre problème et elle s’est retrouvée face au même problème que nous, un manque d’information et de données pour pouvoir mettre en qualité ce jeu de données. La solution que nous avons eue est : d’utiliser les données qui sont disponibles en précisant qu’elles ne sont pas propres et pas à jour par rapport à la réforme du découpage cantonal de 2014.
A la suite de notre entrevue, nous avons vérifié la mise en qualité de nos jeux de données. Nous avons de plus, vérifié aussi notre avancée de la journée par rapport à la check list et nous nous sommes mis à remplir le Bilan de la mise en qualité afin de conclure notre journée.
Cette journée fut plutôt productive grâce à une bonne organisation du travail. Le groupe vit bien malgré quelques tensions (taquineries) cristallisées autour d’une personne : Louis. Le membre de ce groupe se retrouve au cœur des débats, notamment avec Jibran, Nahia et même Elena ce jour-ci. Cela n’entache pas le bon esprit du groupe et renforce même la cohésion et la bonne humeur.
Bilan de mise en qualité d’un jeu de données : Évolution des prix domestiques du gaz et de l’électricité de la Mayenne. Groupe 19

JOUR 4 – PUBLICATION
Après la petite réunion habituelle avec les datactivistes, nous avons directement assisté à une entrevue avec notre référente du département afin qu’elle nous explique les procédés nécessaires à la publication des données. Nous allons notamment utiliser le portail open data qui est une plateforme assez couramment utilisée par les collectivités. Notre interlocutrice récupérera nos données, notamment pour les présenter au président du Conseil départemental, ce qui devrait précéder l’ouverture d’un portail de data propre à la Mayenne en mars 2023. Il y a beaucoup d’informations avec lesquelles composer et nous sommes donc assez perplexes.
Nous avons alors commencé par remplir les fiches descriptives, ce qui nous a pris une petite dizaine de minutes.
Après avoir déjeuné, nous nous sommes directement attelés à la publication des données sur le portail DATA de la Mayenne. Nous fûmes rassurés par la facilité de cette entreprise qui nous prit seulement quelques dizaines de minutes.
Ensuite, Elena et Lucas se sont occupés de la partie communication de la publication des données. Ils ont repris les éléments de la charte graphique envoyée par notre interlocutrice afin de créer un élément de communication, sûrement une newsletter, à visée interne. De même, nous allons créer un compte Twitter qui viserait à promouvoir un hashtag afférent à notre travail.
Pendant ce temps-là, nous faisons des recherches qui nous permettraient d’agrémenter d’informations pertinentes le volet communication de notre future publication.
La partie communication s’avère être finalement la plus ardue, surtout car nous n’arrivons pas à trouver un titre suffisamment concis et accrocheur. Globalement, entre la mise en forme de la charte graphique, la rédaction de la newsletter ou encore la promotion sur les réseaux sociaux, il nous aura fallu près de deux heures, notamment car nous avons pris beaucoup de temps pour peaufiner des petits détails de mise en forme, ce qui s’est finalement avéré assez fastidieux.
Elena et Lucas s’attèlent à la conception de la charte graphique.
Url des jeux de données publiés :
- https://data.lamayenne.fr/backoffice/catalog/datasets/225300011repartition_des-potentiels_de_methanisation_a_horizon_2050_par_canton/#sources
- https://data.lamayenne.fr/backoffice/catalog/datasets/225300011_e-volution-des-prix-domestiques-du-gaz-et-de-l-e-lectricite/#sources
- https://data.lamayenne.fr/backoffice/catalog/datasets/225300011_production_electrique_par_filiere_a_la_maille_par_commune/#sources
- https://data.lamayenne.fr/backoffice/catalog/datasets/225300011_capacite-et-quantite-d-injection-de-biomethane/#sources
- https://data.lamayenne.fr/backoffice/catalog/datasets/consommation-et-thermosensibilite-electriques-annuelles-a-la-maille-epci/#sources
- https://data.lamayenne.fr/backoffice/catalog/datasets/225300011_consommation_electricite_communes_et_secteurs_2019/#sources
- https://data.lamayenne.fr/backoffice/catalog/datasets/installations-de-production-d-electricite-et-de-gaz/#sources
Plan de communication sur les données ouvertes :
- Sensibilisation en interne ( communication, dans un format « article » ou « newsletter » qui illustrerait le « à quoi ça sert d’ouvrir ses données » ? ) : Ouvrons les données !
- Création d’un compte Twitter et utilisation du hashtag #mayDATA
- Communication Linkedin, notre interlocutrice publiera.
Newsletter Ouvrons les données !, Groupe 19, Conseil Départemental de la Mayenne

JOUR 5 – VALORISATION
Notre cinquième jour a débuté par le passage en revue du carnet de bord des jours précédents. Nous avons retravaillé certaines parties, notamment le résumé du premier jour, pour uniformiser le carnet de bord. Par la suite, nous avons convenu d’une répartition de l’introduction, de la conclusion et du résumé du cinquième jour, parmi ceux qui n’avaient pas encore pu rédiger leur part. Ce remplissage s’est fait dans la coopération.
Ensuite, nous avons retravaillé les jeux de données, notamment les graphiques et tableaux, en vue d’en faire une datavisualisation. Dans un cas, nous avons établi qu’il était impossible de proposer le graphique d’un jeu de données, certainement en raison d’un trop grand nombre de données. Par ailleurs, à l’occasion de ce retour au travail sur les jeux de données nous avons effectué une vérification de la corrélation entre les données publiées sur le portail et les données de la source. Cependant, nous avons été confrontés à un obstacle. En effet, l’établissement de cette corrélation est parfois difficile. Par exemple, dans le jeu de données “thermosensibilité à la maille en EPCI”, on a pu s’apercevoir que c’était impossible. Nous avons donc choisi de ne présenter que la thermosensibilité en fonction de l’EPCI.
Une fois ces vérifications et consolidations achevées, nous nous sommes occupés de la publication des jeux de données sur Airtable.
Comme à l’accoutumée, nous avons ensuite rejoint notre interlocutrice mayennaise dans une réunion en ligne. A la suite de cela, nous avons corrigé les textes destinés à la communication rédigés la veille (post Linkedin et document de communication interne), après quoi nous nous sommes attelés à remplir les fiches “contexte de datavisualisation”. Cette étape s’est révélée pour le moins fastidieuse, au regard des répétitions dans nos réponses aux questions, notamment en ce qui concerne l’utilité des données.
La tâche suivante nous a rapproché de la fin, puisqu’elle a consisté à travailler l’oral de présentation de notre travail. Pour être efficaces, nous avons créé un drive dédié à cette restitution. La préparation de cet oral s’est faite par la relecture de nos différentes fiches et des résumés du carnet de bord. Nous avons choisi d’accompagner notre restitution par un diaporama, afin de défendre notre projet par l’apport d’un support visuel.
CONCLUSION
Nous tirons donc de cette semaine de Data Challenge un bilan très positif, en tout point. Tout d’abord d’un point de vue du groupe, dans la mesure où nous avons pu travailler ensemble avec une bonne cohésion, ce qui nous a permis d’avancer rapidement, efficacement et de façon fluide dans nos différentes tâches. Ce bilan positif est également, nous l’espérons, celui du Conseil Départemental de la Mayenne, dans la mesure où nous avons publié 7 nouveaux jeux de données sur leur portail et permis une communication autour de cela.
Si nous avons pu rencontrer quelques difficultés durant cette semaine, ces dernières restent minimes et uniquement relatives à des jeux de données parfois difficiles à traiter et nettoyer, ou à des données qui n’étaient pas à jour. En revanche, notre travail a grandement été facilité par notre interlocutrice au sein de la collectivité, extrêmement au fait de l’open data et qui porte ce projet d’ouverture des donnés au sein du département mayennais. Ses explications ont toujours été détaillées, claires et son accompagnement régulier, à raison d’une à deux réunions par jour. De plus, elle a toujours été réactive, nous pouvions réellement compter sur elle pour nous accompagner tout au long de ce Challenge. Un autre levier qui nous a permis d’avancer de façon aussi efficace fut la disponibilité des données sur les différents portails, accessibles et téléchargeables sans difficultés.
En tant qu’étudiantes et étudiants à Sciences Po Saint-Germain en Laye, nous ressortons enrichis de cette expérience, avec de nouvelles connaissances sur l’Open Data, qu’elles soient par rapport au processus d’extraction des données ou par rapport à l’utilisation de ces dernières dans le cadre de politiques publiques (de l’élaboration à l’évaluation de ces dernières). Nous avons pu nous familiariser à cet outil porteur d’opportunités pour chaque individu , disponible pour chacun en quelques clics. Si nous n’avons travaillé que sur le département mayennais, nous prenons conscience de l’ampleur des possibilités liées à ces données, ainsi que leur rôle d’inclusion et de mobilisation des citoyens du fait de leur transparence et accessibilité mais également du fait de leur variété, l’open data s’appliquant à tous les champs de la vie politique et publique.
Nous ressortons également avec de nouvelles compétences relatives au traitement et à la valorisation de données, domaines dans lesquels aucun d’entre nous n’avait auparavant d’expérience.
Pour conclure, nous pensons avoir relevé ce Challenge Data, ayant rempli nos objectifs de publication avec 7 jeux de données publiés sur le portail mayennais sur les 8 suggérés par notre interlocutrice.