Carnet de bord de l’ouverture des données de Rosny-sur-Seine
par Orphée Silard, Yasmine E., Mélanie E Silva, Inès Mahiou, Bertrand Benoit, Clémence Vigneau et Claire Houzé
INTRODUCTION
L’ère du numérique a bouleversé nos habitudes et notre société dans sa globalité. Il nous incombe de faire de ces nouvelles technologies le meilleur ou le pire des usages. L’open-data, à n’en pas douter, prouve que l’Homme peut utiliser ces nouvelles données produites massivement pour servir l’intérêt général.
Avant de commencer, explicitons certains termes. Le big data ou “mégadonnées”, désigne l’ensemble volumineux de données produit chaque jour sur un territoire. Ces big datas se définissent par les 3V: vitesse, volume et vélocité. L’open data, ou “la donnée ouverte” est une information publique brute publiée, librement accessible et réutilisable par tous sans restriction. La data est devenue un enjeu clef de notre monde interconnecté. Le challenge data prouve la nouvelle importance de ces données dans nos sociétés.
Le challenge data est issu du partenariat entre la société coopérative Datactivist et Sciences Po Saint Germain-en-Laye. Le 15 février 2021 ouvre ainsi la troisième édition de ce challenge.
La visée de ce projet est double:
-
Premièrement, pour les communes participant au projet, l’objectif est de se mettre en phase avec la législation française. La loi pour une République numérique votée en 2016, entrée en vigueur en 2018, a affirmé le principe de l’open data. Cette loi instaure l’obligation pour les collectivités de plus de 3 500 habitants et les administrations de plus de 50 agents, de publier en ligne leurs bases de données et les données dont la publication présente un intérêt économique, social, sanitaire ou environnemental. L’open data se développe dans un souci d’information, de transparence des politiques publiques et est un support d’aide pour une bonne gouvernance. L’open data est d’intérêt public.
-
En second lieu, ce challenge permet aux étudiants de Saint-Germain-en-Laye d’obtenir une expérience professionnelle tout en aidant la collectivité. Cette expérience se révèle riche de sens dans cette société interconnectée où les big-data ont désormais une place prépondérante. C’est la raison pour laquelle, chaque groupe, composé de 6 à 7 étudiants, a pour objectif d’aider une collectivité territoriale plus ou moins avancée sur la question des data et plus ou moins grande (communes, communautés de communes, métropoles).
Notre groupe de 7 étudiants, Claire Houzé, Mélanie E-Silva, Clémence Vigneau, Yasmine E., Inès Mahiou, Orphée Silard et Bertrand Benoit, est bien déterminé à aider de son mieux la Commune de Rosny-sur-Seine.
Cette commune des Yvelines, d’environ 6 100 habitants, est en pleine expansion démographique depuis 50 ans. Située au nord de Mantes-la-Jolie, elle fait partie de la Communauté urbaine Grand Paris Seine et Oise, laquelle est composée de 73 communes. La ville jouit notamment d’une connexion à Paris avec le train et avec l’autoroute A13.
La commune de Rosny-sur-Seine, qui se définit comme une mauvaise élève concernant l’open data, s’est inscrite au challenge grâce à l’alerte du maire de Carrière-sous-Poissy. En effet, le travail semble assez conséquent. La commune n’a encore publié aucun jeu de données et possède peu de ressources en data (peu de fichiers Excel avec des informations communales). Notre groupe aura 5 jours afin de publier le premier jeu de données de la ville en open source sur la page open data de GPS&O (Grand Paris Seine et Oise: https://gpseo.opendatasoft.com/pages/accueil/).
5 jours, 5 étapes:
- Le premier jour, il s’agira de réaliser un diagnostic sur d’avancement de la commune en termes de récolte et de publication de ses données. Puis nous réaliserons une wish list afin de déterminer quels jeux de données la commune souhaite potentiellement publier.
- Le second jour, nous nous attacherons à récupérer les différents jeux de données déjà produits par la commune afin de déterminer lesquels sont en pratique publiables. Une fois que nous aurons évalué la charge de travail à réaliser pour harmoniser les data, nous remplirons une wanted data list: les données que nous publierons effectivement en fin de semaine.
- Le troisième jour sera le plus ardu. Nous devrons nettoyer, compiler puis standardiser nos données. Elles seront prêtes à être publiées.
- Le jeudi nous devrons publier les données sur la page open data de GPS&O. Puis nous construirons avec la commune un premier plan de communication sur l’ouverture des données.
- Enfin, le dernier jour, nous valoriserons les données. Nous construirons des outils, comme des cartes, des diagrammes, afin de permettre aux utilisateurs de mieux appréhender les données publiées.
Nous sommes accompagné.e.s dans notre démarche par notre référente, responsable de la communication de la commune de Rosny-sur-Seine. De plus, nous sommes encadré.e.s par Arthur, membre de Datactivist, une société coopérative et participative qui se donne pour mission d’ouvrir les données et de les rendre utiles et utilisées.
JOUR 1 – DIAGNOSTIC
Notre journée a commencé avec une réunion de présentation, durant laquelle nous avons reçu des informations importantes sur le déroulement de la semaine. L’humeur générale est plutôt fatiguée et peu dynamique au sein de la promotion. Dans notre groupe, nous sommes déjà plus chanceux et profitons d’une sympathique ambiance de travail.
Ensuite, après nous être repérés sur gather town, nous avons procédé à la prise d’information sur les tâches et objectifs du jour grâce au site Bienvenue dans le Challenge Data. Après intégration des exigences des étapes 1.1, 1.2 et 1.3, ainsi que du carnet de bord, nous avons partagé le travail pour la semaine.
Notons également qu’avant même de découvrir le carnet de bord du challenge, nous avions créé deux documents communs au groupe sur drive:
- un carnet de bord (brouillon)
- un document de travail pour centraliser les informations
1.1 : Évaluer la maturité open data et comprendre les besoins
Sans plus attendre, nous avons appelé notre interlocutrice de la commune de Rosny. Nous avons convenu d’un rendez-vous pour 14h. En attendant ce rendez-vous, nous avons analysé le catalogue des jeux de données, et avons tenté de nous informer au mieux sur la commune avec laquelle nous travaillons.
A 14h, nous retrouvons notre interlocutrice sur gather town. Nous discutons avec elle brièvement, faisons un tour de table pour présenter l’équipe au complet. Nous lui posons ensuite les questions du questionnaire de maturité sur l’open data. Lors de notre conversation préalable, nous avions cru comprendre que la ville est néophyte en termes de données ouvertes. C’est ce que le questionnaire a confirmé.
→ La commune de Rosny-sur-Seine compte soixante-dix agents, et n’a pas de service consacré à l’open data, ni (à la connaissance de notre référente) un fonctionnaire en capacité d’en produire. Rien que pour les besoins informatiques, la mairie fait appel à un informaticien extérieur.
→ La commune a été alertée par le vice président de l’intercommunalité GPSO de l’opportunité de participer au programme open data, et l’offre était une occasion pour celle-ci de rattraper son retard dans le domaine, retard qui n’était dû qu’à un manque de moyens et à un contexte priorisant d’autres domaines plus urgents. Notre référente précise également que le format du challenge les a séduit, au vu en particulier de la collaboration avec des étudiants.
Le questionnaire donne un résultat de maturité niveau 2. Nous avons été surpris par ce résultat car la commune n’a réellement pas d’avancement dans le domaine de l’open data. Cependant, ce chiffre s’explique par le point fort de la ville car le questionnaire prenait aussi en compte les plateformes de communication et la fréquence de posts sur ceux-ci.
Cette constatation de maturité open data relativement basse nous permet de proposer à notre interlocutrice plusieurs jeux de données, afin de déterminer sa wishlist.
1.2 : Recueillir les besoins de la collectivité
La constitution de la wishlist fut un peu rude, car sur le niveau 1 et 2, la plupart des domaines proposés ne relèvent pas de la compétence de la commune. Cependant, nous avons écouté les intérêts manifestés par notre interlocutrice qui étaient au sujet de:
- Transports et ce qui s’y rattache (notamment vélos)
- Petite enfance (établissements d’accueil)
- Etat civil
- Budget primitif
Après cette concertation, notre référente nous a proposé de reprendre un rendez-vous en fin de journée pour qu’elle confirme entre-temps ces informations avec ses collègues et s’assure que leurs jeux de données sont bien en la possession des services communaux.
En fin de journée, nous recevons une fois de plus notre interlocutrice sur gather town. Elle nous informe que certaines catégories ne pourront pas être exploitables. Par exemple, les jeux de données sur l’état civil relèvent de la préfecture, et ne sont donc pas à notre portée. Également, la catégorie des modes de transports est trop large et certaines informations sur le sujet sont déjà publiées au niveau national (plutôt que communal). Nous nous mettons alors d’accord pour proposer d’autres possibilités.
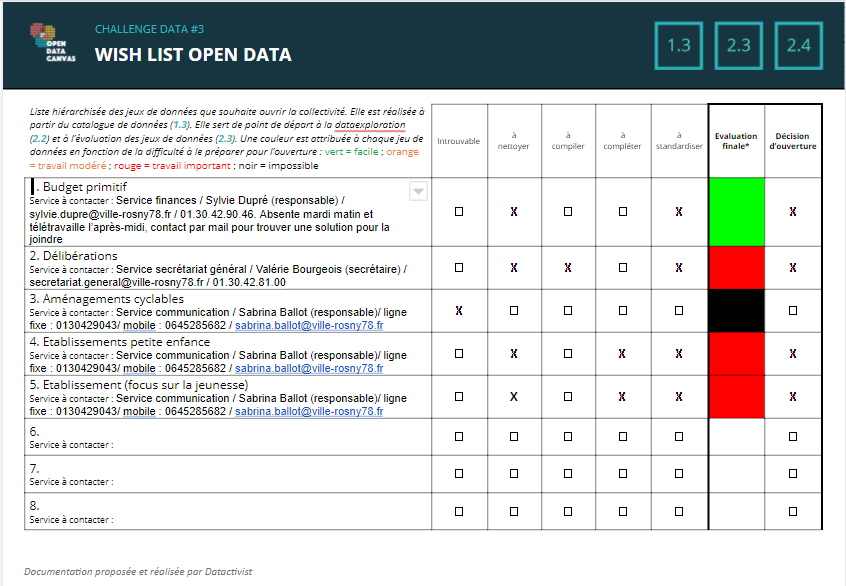
1.3 : Rédiger une liste de souhaits de la collectivité
Au final, se construit une petite wishlist composée de jeux de données sur:
- le budget primitif
- les délibérations
- les établissements d’accueil petite enfance
- l’aménagement cyclable
Notre interlocutrice nous envoie suite à cet entretien un mail avec tous les services possédant les données en question. Nous émettons des réserves sur la possibilité de trouver des jeux de données utiles sur les 4 catégories, et suggérons que dans les jours qui viennent nous serons plutôt concentrés sur 2 voire 3 catégories.
La wishlist remplie (disponible ici), notre journée est terminée. Nous notons tous nos ressentis de la journée sur le carnet de bord brouillon, et la personne responsable procède à l’écriture du compte-rendu du jour.
JOUR 2 – IDENTIFICATION
Notre journée a débuté par un brief donné par notre coach open data, Arthur, au cours duquel il a présenté les grandes lignes directrices de l’identification des données. Afin de récolter au mieux les données, Arthur conseille aux datactivists que nous sommes de prendre connaissance des différentes vidéos, mises à disposition dans les rubriques 1.1, 1.2 et 1.3 du site Bienvenue dans le Challenge Data.
Et c’est ce que notre groupe s’est empressé de faire afin de se familiariser avec les nouveaux logiciels de la journée, à savoir Workbench du Challenge Data et Mindmup.
2.1 Exploration à la recherche de données
La première mission du jour a été de préparer le matériel nécessaire à la collecte des données. Dans le Workbench du Challenge Data, nous avons dupliqué puis renommé les jeux de données correspondant à notre collectivité. Pour rappel, notre « wishlist » se constitue de cinq jeux de données :
- « Budget primitif »
- « Délibérations »
- « Aménagements cyclables »
- « Etablissements petite enfance »
- « Etablissements jeunesse »
Afin de rendre efficient la collecte des données, notre groupe s’est réparti les tâches de la journée. Tout d’abord, un étudiant a eu pour objectif de récupérer les données des « Budgets primitifs » en envoyant un mail au service des finances. Ensuite, deux autres étudiants ont eu pour mission d’appeler le service de secrétariat général de la commune de Rosny-sur-Seine afin d’obtenir les données concernant les « Délibérations ». Enfin, trois étudiants se sont occupés de la récolte des bases de données suivantes, « Aménagements cyclables », « Établissements petite enfance » et « Établissements jeunesse », en appelant directement notre contact collectivité.
Quelques difficultés sont alors apparues, mais ont été rapidement surmontées par la disponibilité des différents responsables de service. La prise de contact par téléphone ou par mail a été très facile, même si l’obtention des données a demandé un peu plus de patience.
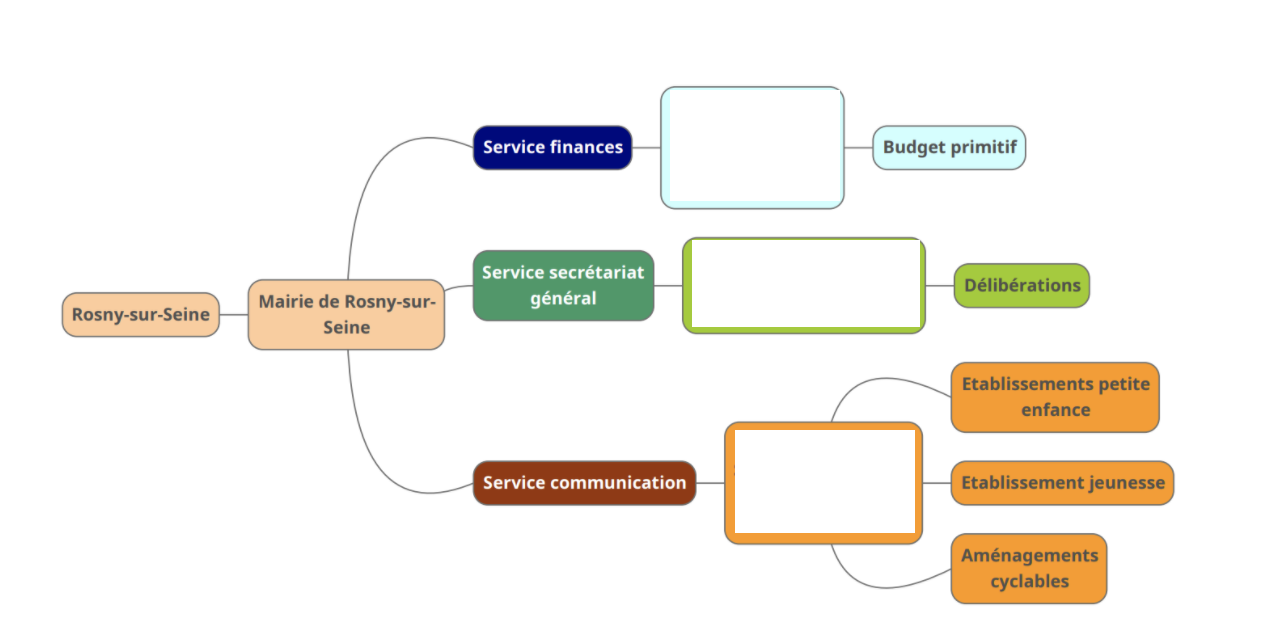
2.2 Compléter l’organigramme de la donnée
Nous avons profité de ce petit temps pour mettre en place notre organigramme à l’aide de l’outil le Mindmup. L’outil était assez simple à prendre en main, nous avons choisi un responsable dans le groupe qui était chargé de s’en occuper. Dans cette étape, nous n’avons pas rencontré de difficultés particulières.
2.3 Évaluer le travail de mise en qualité
En début d’après-midi, nous avons reçu les jeux de données concernant « Établissements petite enfance » et « Établissements jeunesse » sous un format Excel, mais sous un seul fichier. Sans plus attendre, nous avons uploadé ces données sur notre Workbench afin d’en évaluer la qualité en les comparant aux exemples type.
- Nettoyage. Les cellules vides étaient suffisamment nombreuses au regard du peu de données disponibles. Toutefois, comme le jeu de données récolté ne comportait qu’un nombre très limité d’informations, le nettoyage s’est fait de manière rapide.
- Compilation. Au lieu de compiler nos données, il nous est apparu plus pertinent de les « séparer » entre celles renvoyant aux « Établissements petite enfance » (établissements destinés aux enfants entre 0 et 6 ans) et celles renvoyant « Etablissements jeunesse » (établissements dédiés aux jeunes entre 6 et 25 ans).
- Complétion. Bien que peu nombreuses, les données récoltées nous semblent complètes.
- Standardisation. Il nous est apparu que les données n’étaient pas présentées de manière uniforme, ce qui est une grande entrave à la lecture et la compréhension de celles-ci. Un grand travail de standardisation sera attendu de ce côté.
Nous avons ensuite reçu les jeux de données « Délibérations » de 2015, 2016, 2018, 2019 sous format Excel mais sous plusieurs fichiers que nous avons répartis en différents onglets.
- Nettoyage. Beaucoup de cellules vides apparaissent.
- Compilation. Il nous apparaît essentiel de réunir les onglets par année. Car, actuellement, certaines délibérations d’une année apparaissent en plusieurs fichiers.
- Complétion. Le jeu de données nous semble complet.
- Standardisation. Les données sont présentées de manière non uniforme. La lecture de celles-ci paraît compliquée du fait du manque de classification et du grand nombre de données.
Les jeux de données « Budgets primitifs » des années 2018, 2019, 2020.
- Nettoyage. Beaucoup de lignes « blanches » apparaissent. Il est donc nécessaire d’apporter un nettoyage complet.
- Compilation. Les données sont déjà présentées selon un onglet différent pour chaque année, une synthèse et un récapitulatif. Le travail de compilation apparaît alors superflu.
- Complétion. Le jeu de données nous semble complet.
- Standardisation. Une mise en forme est ici essentielle (beaucoup de virgules, manque de 0…).
Malheureusement, nous n’avons pas reçu les jeux de données concernant les « Aménagements cyclables ».
2.4 S’engager sur un wanted list
Nous avons finalisé notre journée avec brief avec notre coach Arthur afin de montrer notre collecte de données et d’identifier les futures données à traiter.
Engagement sur la wanted list :
https://docs.google.com/document/d/1VE9XEJz3rkSghTDUxfY3Ohft3qrGs2rW/edit
Nous avons fait part de nos difficultés concernant l’utilisation de l’outil Workbench, mais Arthur nous a rapidement rassuré !
JOUR 3 – MISE EN QUALITÉ
Nous commençons cette journée à 9h par une réunion avec Arthur qui durera une petite vingtaine de minutes, avec les deux autres villes qu’il gère, pour faire un point sur nos difficultés ces deux derniers jours. Pour notre équipe, nous avons déjà eu à appréhender le logiciel dans la fin de la journée d’hier afin de pouvoir évaluer avec justesse la faisabilité de traitements de nos jeux de données.
Nous avons ensuite regardé les vidéos d’explication du logiciel Workbench. Pendant notre visionnage, Arthur est venu nous voir en nous voyant très concentrés. Nous avons expliqué les difficultés de prise en charge du logiciel que nous avons déjà rencontrées, par rapport au passage en majuscule de certaines données, de standardisation des horaires ou de complément, à la division des colonnes et à la suppression des lignes.
En effet, même après avoir regardé les vidéos hier pour certaines d’entre nous, nous ne pouvions pas faire ces manipulations. Il nous a aidés à simplifier notre démarche de mise en qualité des données qui comportaient trop d’étapes. Il est plus facile de passer par Excel (n’étant pas adepte du logiciel pour certains, cela a pris du temps) puis d’importer le document dans WorkBench. Nous sommes donc repartis de zéro. Quoi qu’il en soit, même Arthur a peiné pour certaines étapes, donc nous sommes « rassurés » sur notre capacité à prendre en charge le logiciel ! Cette étape de clarification a pris 45 minutes.
Pour ces étapes, nous avions déjà conclu que nous ne pouvions pas être plusieurs dans le logiciel en même temps, sous peine de supprimer ce que quelqu’un avait déjà supprimé. Nous avons donc décidé de nous disperser entre plusieurs jeux de données, à raison de 2 par jeux de données : le « cerveau », qui reste sur l’exemple et guide la « main », qui fait les manipulations sur le logiciel, à l’exception des petits jeux de données (enfance et jeunesse) et de celui sur les délibérations, que nous avions divisé par années.
3.1 Nettoyer les données
Pour ce qui est du nettoyage, nous avions seulement convenu de supprimer les cellules vides.
3.2,3,4 Compilation, standardisation et validation
- Budget primitif:
Le budget était plutôt complet et ordonné, il n’y avait plus qu’à faire la standardisation et un certain niveau de complétion. En effet, de nombreuses colonnes devaient être ajoutées par rapport à l’exemple. De plus, le renommage des colonnes a posé plus de difficultés que prévu car il y a eu une différence entre les tables chronologique et thématique. Enfin, les numéros associés au poste de dépense ne sont pas précisés, on ne sait donc pas si on doit créer des colonnes spécifiques pour les rentrer ou pas et à quoi ils correspondent. Après avoir résolu ces problèmes avec l’aide d’Arthur, il manquait le numéro de SIRET pour chaque ligne du budget pour pouvoir valider définitivement le jeu de données sur le logiciel. Mais le budget contient plus de 3000 lignes et nous nous posions donc la question de la façon de copier/coller un numéro de SIRET dans une nouvelle colonne, car nous n’avons pas trouvé la fonction copier/coller. Il fallait donc le faire sur Excel. Après la validation, de nombreuses erreurs sont apparues qui ont dû être corrigées une bonne partie de l’après-midi avec l’outil “Search and Replace”, ce qui a permis d’atteindre des données valides à 99%.
Lien Workbench : https://app.workbenchdata.com/workflows/132496/
- Équipements jeunesse / Petite enfance
Pour les équipements jeunesse, tout était plutôt propre car l’une de nous l’avait presque achevé hier. Au départ, nous n’avions pas compris à quoi correspondait l’ID et passé plusieurs minutes à chercher les différents numéros d’identification qui existaient pour les entreprises, avant de comprendre que cet identifiant correspondant au code postal INSEE de la ville que l’on traitait, aux initiales EAJE (Etablissement d’accueil de la petite enfance). Je n’ai pas trouvé à quoi correspondaient les deux derniers chiffres donc j’ai abandonné le remplissage de cette colonne. Le logiciel nous a empêché de créer une nouvelle colonne pour ajouter les ID. Le seul moyen trouvé pour créer de nouvelles colonnes était la fonction « Dupliquer ». La page remonte sans arrêt vers le haut ce qui est complexe lorsque l’on veut supprimer du contenu dans les cellules. Pour le trier et le séparer de la jeunesse, nous avons supprimé toutes les lignes en rapport avec l’enfance (de 0 à 6 ans). Pour la petite enfance, les horaires ont été standardisés selon YoHours. La question se posait de garder les mails : en effet, si certains correspondaient à des données personnelles, cela poserait un problème légal. Nous les avons gardés car aucun ne contenait des données personnelles. Il ne manquait plus que la géolocalisation des différents établissements que nous avons trouvée grâce à Arthur et la suppression des données concernant la jeunesse (6 et plus).
ien Workbench Equipement jeunesse : https://app.workbenchdata.com/workflows/132507/
Lien Workbench Etablissement Petite enfance : https://app.workbenchdata.com/workflows/132502/
- Délibérations:
Pour les délibérations, dont au moins 70% des données sont manquantes, le travail de complétion était trop massif pour que nous puissions possiblement le prendre en charge. Ainsi, à l’exception des informations aisément trouvables sur Internet, comme le numéro de SIRET, nous avons complété que 4 colonnes sur la douzaine que comprend l’exemple. Nous n’avions pas compris comment lire les données et nous avions besoin d’aide. En effet, la mairie nous a envoyé des tables chronologiques et thématiques sans que l’Excel soit réellement traitable en l’état, mais également de télécharger Office pour éviter les problèmes de conversion WorkBench à Excel.
Dès lors, Arthur nous a aidés à faire l’année 2015 en choisissant la table chronologique pour que nous puissions avoir un modèle à suivre. Nous avons par son biais découvert une fonction sur Excel pour coller une cellule chiffré en continu (en l’occurrence, une date) sans qu’un chiffre s’ajoute ($D$). La présence ou non de virgules ou d’apostrophes ont aussi bloqué notre progression car nous ne savions pas leur importance.
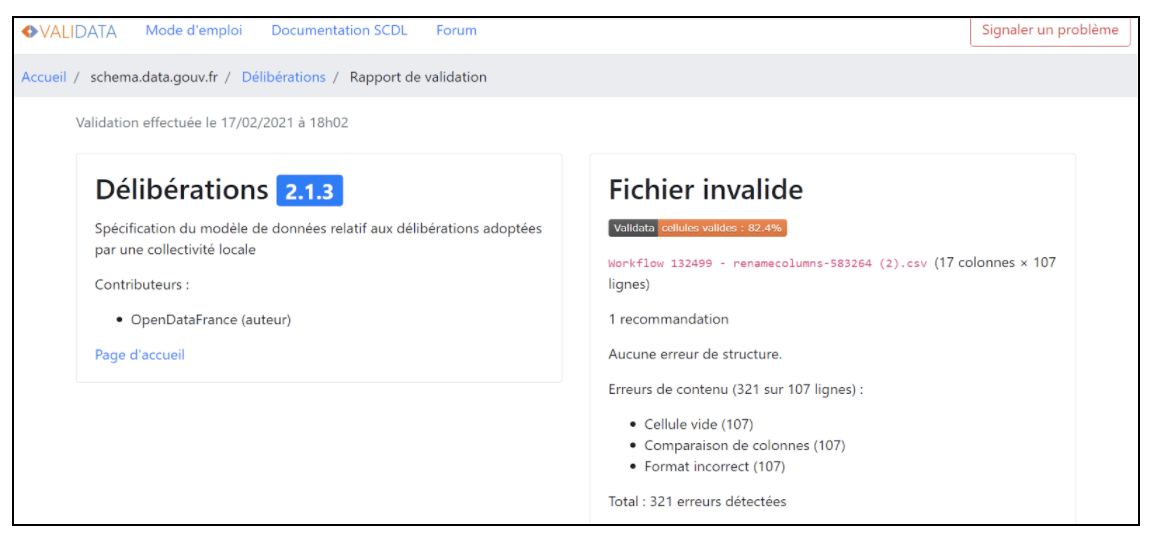
Après avoir terminé la standardisation, nous avons un problème insoluble quant au format des dates. En effet, nous avons beau importer des Excel au format européen de date (DD/MM/AAAA), Workbench les fait apparaître au format américain (AAAA/MM/DD). Après avoir essayé de résoudre le problème pendant 3h, et avoir abandonné, nous avons appelé Arthur qui n’a pas non plus réussi. Nous avons décidé de soumettre les dates au format non standardisé. Pour l’étape de validation, nous avions besoin du numéro de SIRET de la commune et nous l’avons trouvé sur Google.

Mais nous devons donc créer une V3 de notre travail pour insérer sur Excel le numéro de SIRET puis réimporter la nouvelle version sur WorkBench. Un autre problème important est survenu ensuite : la validation par rapport aux données disponibles. Nous n’avons pas toutes les données sur les délibérations et donc notre score de données valides sur Validata est plus bas que nous le voudrions. Nous avons dû ajouter des colonnes même vides pour que le logiciel traite nos données. Certaines données étaient même dans le mauvais ordre dans nos Excel et ce n’est qu’en entrant le document dans Workbench, l’ayant corrigé puis envoyé en vérification que Validata montré le problème. Le corriger a été fastidieux.
Finalement, les tâches ont été si longues et les rebondissements nombreux qu’on en arrive à 4 versions par année de délibération et nous avons fini après 19h.
Lien Workbench : https://app.workbenchdata.com/workflows/132499/
3.4 Validation

JOUR 4 – PUBLICATION
Nous entamons cette journée par une réunion avec notre coach Arthur, qui nous présente la journée. Pour la publication des jeux de données, nous devons utiliser non pas le portail data.gouv mais celui de GPS&O (Opendatasoft). Il nous faut donc attendre un responsable de GPS&O. La réunion est fixée à 14h.
Nous découvrons le déroulé des étapes du jour : compléter la fiche descriptive, publier les données et préparer le plan de communication sur les données ouvertes.
4.1. Compléter la fiche descriptive des jeux de données
- Fiche descriptive
Pour cette première étape, après le visionnage individuel des vidéos supports, nous nous sommes répartis le travail. Pour avoir l’intégralité des informations, nous devons appeler les agents à la mairie de Rosny-sur-Seine ayant produit les données. Nous avons pris la décision de pré remplir les fiches, pour gagner du temps, en émettant des hypothèses: par exemple, sur l’usage potentiel de ces jeux de données (transparence, informations à destination des citoyens), la fréquence de mise à jour (budgets primitifs annuels)
Puis nous avons appelé chacun notre référent, suivant notre organigramme de la donnée. Pour cela, nous avons constitué des groupes de 2-3, en fonction du jeu de données sur lequel nous avions travaillé la veille et des contacts que nous avions eu avec cette personne au préalable.
Pour ma part, avec ma camarade nous n’avons eu aucun problème à joindre la responsable en charge des budgets. Nous avons pu remplir la quasi-totalité des métadonnées, sauf la case « Licence » qui est restée en suspens. La personne ne disposait pas de cette information, et nous, malgré une rapide recherche en amont, nous n’avions pas les connaissances pour l’aider. On demandera à Arthur plus tard. Nous avons ensuite fait un bilan collectif, qui est globalement positif :
→ Pour les délibérations et les budgets = « obligation légale », « enjeu de transparence » confirmés du fait du cadre juridique. Pour les délibérations, on leur a indiqué qu’il s’agissait d’une « licence ouverte », dans la quasi-totalité des cas traités par la mairie.
Difficultés :
→ Pour les équipements (jeunesse, petite enfance) = mes camarades ont pu joindre la chargée de communication qui nous avait envoyé les données mais, elle est restée assez très vague dans ses réponses quant aux conditions de production de la donnée. Cela s’explique par le fait que les établissements jeunesse sont pour la plupart publics et dépendent des décisions de la mairie (ex création d’un nouvel établissement, structure). Il n’y a donc pas de régularité à proprement parler, dans la mise à jour et la production de données à ce sujet.
→ Concernant la distinction jeunesse/ petite enfance = C’est lié à notre décision initiale de diviser les équipements de la communes en deux fichiers, selon le public visé : petite enfance (0 à 6 ans) et jeunesse (de 7 à 25 ans). De ce fait, nous avions constitué deux jeux de données, en retirant des éléments dans chacune. Cependant on nous a indiqué que Rosny-sur-Seine considérait que la catégorie « jeunesse » allait de 0 à 17 ans. S’est alors posé la question de l’exploitation des données par la commune si les catégories différaient, si des informations manquaient.
Nous avons finalement choisi de rester sur notre distinction initiale. Cela nous paraissait plus pertinent, au vu de notre travail et de ce que nous avait conseillé Arthur le premier jour.
4.3. Préparation de la communication de la commune autour de l’ouverture des données
- Plan de communication:
Puisque notre référente à Rosny-sur-Seine est aussi chargée de communication, nous avions pris la décision de nous avancer et de directement préparer le plan de communication sur les données ouvertes avec elle. Nous lui avons présenté le modèle de plan de communication donc nous disposions (pré lancement, publication, post…) et les différentes options pour voir ce qui était le mieux adapté selon elle.
Cependant, il apparaît que Rosny-sur-Seine n’a pas prévu de stratégie de communication particulière concernant les résultats du Challenge data. La communication se fait principalement « à chaud », selon ce qui se passe sur le territoire, ce qui est utile pour les citoyens au quotidien. Le timing est donc important et semble donc varier, ne pas être précisément défini.
=> Cependant, nous notons l’activité importante de la commune sur leur page Facebook ce qui est un atout. En outre, la ville peut aussi communiquer via le portail Famille, leur site, des flyers et leur application.
Principale difficulté = remplir le template du plan de communication, qui ne semble pas adapté pour notre commune, qui semble « fusionner » toutes les étapes. La rigidité du template ici ne correspond pas à la stratégie de communication de la commune. Nous avons eu un peu de mal à saisir les attentes de ce plan de communication. Nous avons donc tenté de reprendre certains éléments, en les adaptant:
- Pré-lancement: réunion interne d’information à destination des agents de la mairie pour les sensibiliser à l’open data, puis des post Facebook avec des supports numériques (flyer, vidéo) explicatifs. Utilisation de l’application de la commune « Rosny-sur-Seine, ma ville » pour diffuser des articles plus détaillés.
- Le lancement de la stratégie Open data: Post Facebook / Articles sur les enjeux data sur le site web de Rosny-sur-Seine (https://www.ville-rosny78.fr/) / Application « Rosny-sur-Seine, ma ville » / Portail Famille (https://www.espace-citoyens.net/rosnysurseine/espace-citoyens/) pour les jeux de données établissement petite enfance et équipement jeunesse / Un communiqué de presse de la Mairie que nous avons rédigé (Nous avons mis en valeur l’enjeu de transparence + dynamisme de la commune) et de GPS&O (en complément, pour insister sur la démarche collective)
- Post lancement : Facebook / Site web /Application + Possible article plus détaillé dans le magazine municipal « Rosny le mag » (publication trimestrielle) https://fr.calameo.com/accounts/3254072
4.2. Publication des données et de la fiche descriptive sur un portail open data
- Publication:
Il ne nous restait plus qu’à publier les données sur Opendatasoft, le portail de GPS&O
Mais la réunion de 14h avec tous les groupes pour publier les données n’a pas eu lieu, cela s’est fait individuellement avec chaque groupe. Nous avons donc été bloqués à cette étape un petit moment. Finalement, Arthur est venu nous donner le site, les codes pour y accéder et nous montrer la procédure détaillée pour publier les données:
Télécharger depuis workbench → nouveau jeu de données → ajouter sources → remplir les informations → joindre la fiche descriptive en pièce jointe → publier
Prenant en main l’outil nous avons rencontré deux difficultés principales :
- Géolocalisation : Pour les données où il manquait la géolocalisation (équipements jeunesse), il nous a semblé pertinent de pouvoir avoir une carte, puisque nous avions les adresses. Cela rend plus l’information plus concrète. C’est finalement Arthur qui a intégré la géolocalisation, la manipulation étant plus complexe que prévu.
- Mettre plusieurs jeux de données dans une même source ? : Pour les délibérations et le budget, nous avions un jeu de données par année (délib 2015, 2016 etc..). Sur Opendatasoft, nous avons donc essayé de tout rassembler, en 1 fichier couvrant la période, et de l’uploader en 1 fois. Problème: lors de la prévisualisation, un seul tableau apparaît. → Nous avons donc fait un fichier pour chaque.
Dans le cas des budgets, du fait qu’il nous fallait publier un par un, Arthur nous a conseillé de publier seulement les budgets annuels et de laisser de côté la synthèse et le récap. (9 jeux en tout sinon)
Finalement, grâce à la documentation et à Arthur, la publication s’est faite rapidement. Nous avons essayé d’harmoniser la façon de remplir les métadonnées, les champs à remplir, pour retrouver plus facilement les documents. Ci joint les url des jeux de données publiés sur data.gouv :
Budgets:
2018: https://www.data.gouv.fr/fr/datasets/rosny-sur-seine-budget-primitif-2018/
2019: https://www.data.gouv.fr/fr/datasets/rosny-sur-seine-budget-primitif-2019/
2020: https://www.data.gouv.fr/fr/datasets/rosny-sur-seine-budget-primitif-2020/
Etablissement accueil petite enfance: :https://www.data.gouv.fr/fr/datasets/rosny-sur-seine-etablissements-daccueil-petite-enfance/
Pour finir, en fin de journée, nous avons reçu un retour de la chargée de communication de Rosny-sur-Seine qui nous a fait un premier retour sur notre plan de communication. Cela a surtout été des corrections quant à la rédaction et des erreurs d’inattention.
Cette journée fut moins intense que la précédente, nous permettant de reprendre nos forces en cette fin de Challenge data. Les seules difficultés furent en somme, de remplir certains champs des fiches descriptives avec les agents de la mairie (vocabulaire technique : ex Licence ODBL) mais aussi d’adapter le template du plan de communication à notre commune.
Mais cela s’explique sûrement par la maturité open data assez faible de la commune, qui débute sur ce sujet. Nous avons donc essayé de faire de notre mieux, s’appuyant sur les outils de communication de la commune et respectant la volonté de la chargée de communication.
Les autres difficultés furent d’ordre technique, sur des manipulations à faire sur opendatasoft: en cela Arthur nous a bien aidé.
JOUR 5 – VALORISATION
- Les datavisualisations réalisées
Dernière ligne droite dans ce challenge data: la valorisation des données. La journée a commencé comme d’habitude par une réunion dans la salle avec Arthur. Les objectifs de la journée étaient assez clairs: rendre les données visibles, parlantes. En effet, après avoir passé des heures sur ces grands tableaux Excel, il est désormais temps de rendre la donnée visible dans des graphiques ou visualisations.
Dans un premier temps, nous avons pris connaissance des vidéos du jour afin de comprendre le processus de datavisualisation. Nous avons ensuite partagé le travail entre les différents jeux de données afin d’être plus efficace dans la production de visuels.
Orphée et Clémence avaient pour mission de valoriser les jeux de données établissements petite enfance et équipements jeunesse. En effet, ces données étant liées par leur caractère et leur nature, nous avons trouvé cela intéressant de les croiser dans une même visualisation, et de faire simultanément une visualisation pour les établissements petite enfance.
Mélanie et Claire étaient en charge du budget primitif. Ce jeu de données, assez conséquent par sa taille, demandait un certain travail afin de pouvoir orienter l’interprétation que d’autres pourront en faire.
Bertrand, Yasmine et Inès, quant à eux, se sont préoccupés des délibérations. C’est ce même groupe qui s’était déjà deux jours auparavant chargé de la mise en qualité de ce jeu de données. Ainsi ils étaient assez familiers avec le contenu et avaient déjà des idées pour la réalisation des datavisuels. Cependant, la tâche était assez difficile du fait du manque flagrant de données dans ce fichier.
Une fois les répartitions faites, chacun s’est concentré sur la création des datavisualisations.
5.1 Réalisation de datavisualisation avec les données publiées
- Etablissements petite enfance / Équipement jeunesse
Le choix du visuel n’a pas été très compliqué ici. En effet, avec les informations dont nous disposions, nous nous sommes directement tournés vers une cartographie. Notre objectif était de rendre compte de la répartition géographique de ces établissements sur la commune de Rosny-sur-Seine. Nous avons donc croisé les deux jeux de données. La cartographie avec ping c’est alors tout de suite imposée dans nos esprits, permettant de rendre plus attractive notre visuel.
Au début, l’outil a été un petit peu difficile à prendre en main. Nous avons fait tous nos visuels sur opendatasoft. Et nous avons eu du mal à comprendre qu’il fallait aller dans explorer > puis > éditer en mode avancé. Une fois la manipulation comprise, l’outil était assez intuitif et nous avons pu choisir les couleurs, les tailles, personnaliser les icônes.
Nous avons effectué deux cartes en simultané: une première avec les établissements petite enfance seulement, une autre regroupant les établissements petite enfance et les équipements jeunesse. Le processus a été assez similaire sur les deux.
Les établissements de la petite enfance sont marqués par un ping rouge avec un icône de bébé. Les équipements jeunesse sont eux représentés par des ping bleus avec un icône représentant deux petits enfants en train de jouer. Ces icônes sont un peu plus grosses.
Quand un utilisateur clique sur l’icône d’un établissement, il va avoir un menu avec toutes les caractéristiques du lieu (localisation, horaires d’ouverture, contact, téléphone etc). Selon les données, ces informations sont plus ou moins précises.
Une des difficultés que nous avons rencontré était que certaines données revenaient dans les deux jeux de données. Nous avons pris un certain temps à comprendre qu’il était possible de les filtrer pour éviter tout doublon.
Enfin un expert datactivist est venu nous aider pour la publication et l’enregistrement de la carte. En effet, une fois le visuel fait sur opendatasoft dans le mode explorer, nous ne savions pas comment retrouver notre carte dans les jeux de données de la commune de Rosny-sur-Seine. Il nous a alors aidé à enregistrer la carte et a effectué en même temps la publication sur la page de la commune de Rosny-sur-Seine sur opendatasoft.
- Budget primitif
Au niveau du budget, il y a eu des gros problèmes de visualisation des données. Du fait du grand nombre de données, il a été décidé de faire un treemap. L’objectif était de créer des espèces de graphiques qui expliquaient pour chaque budget total la part attribuée à un ensemble. L’idée était de savoir où va le budget, pour quelles dépenses et de le matérialiser dans un graphique.
Une première version a été finalisée. Puis un expert data est venu nous aider, le groupe lui a montré le travail, mais il a souligné plusieurs erreurs. L’idée du treemap était bonne, cette visualisation paraissait complètement adaptée, mais le groupe n’avait pas forcément sélectionné les bonnes données, mis correctement l’unité de mesure, les bons filtres etc. Des petites coquilles parsemaient les graphiques. Il a fallu alors complètement refaire les visuels. La première erreur a été de ne pas avoir filtrer les données, de ne pas avoir envisagé de séparer les dépenses et les recettes. Ce point n’avait absolument pas été vu comme une problématique et il a fallu un certain temps pour comprendre comment faire la manipulation sur le logiciel. Ainsi après avoir réussi à filtrer les données, la seconde étape a été de comparer pour chaque part du budget primitif, le budget alloué pour les dépenses d’un côté et pour les recettes de l’autre. Ainsi grâce à cette fonctionnalité de tri, le groupe a pu sélectionner les dix parts les plus importantes du budget pour les mettre dans la visualisation. La sélection a été une étape nécessaire pour rendre le graphique bien plus lisible et attractif. Dans la première version, il y avait beaucoup trop de dépenses. L’autre point qu’il a fallu retravailler avec l’expert était de diversifier les graphiques. En effet, faire un treemap pour chaque année était un peu trop lourd au niveau visuel et répétitif. Le groupe a donc opté pour une autre stratégie et a choisi de faire un diagramme en colonnes afin de pouvoir comparer les années. Là encore, la prise en main du logiciel a été compliquée. La présence du datactivist était alors nécessaire.
La difficulté majeure fut donc le besoin d’accompagnement pour utiliser les graphiques. De plus, la visualisation était compliquée et l’ordinateur a eu beaucoup de mal à suivre. Il a donc fallu aller lentement et l’ordinateur a été finalement dompté.
Le succès: avoir trouvé l’idée du treemap, avoir réussi à faire la relecture avec un expert afin de retravailler les graphiques.
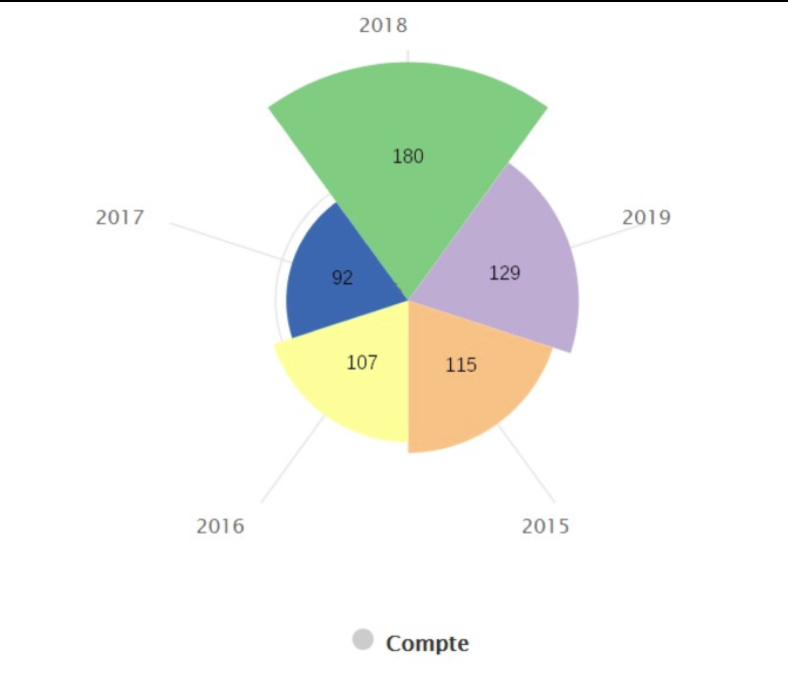
- Délibérations
La tâche était difficile car il manquait beaucoup de données. Le groupe a vu qu’il ne pouvait pas faire un visuel avec les infos dont ils disposaient. Ils ont alors choisi de compiler les données de 2015 à 2019 en un seul visuel. Sachant que les possibilités étaient limitées, le groupe a opté pour un diagramme d’évolution afin de montrer la répartition des délibérations par année. Mais même comme cela, les données n’étaient pas très pertinentes.
Ils ont donc essayé de faire un diagramme, mais le résultat n’étant pas assez pertinent, il a été décidé de ne pas le publier.
5.2 Contextualisation des datavisualisations réalisées
Une fois les datavisualisations réalisées, il a fallu contextualiser pour que chacun puisse comprendre et interpréter la visualisation de la bonne façon.
Pour cela on s’est servi de workbench et de l’onglet Report afin de pouvoir répondre aux questions.
On a ensuite rempli le template sur google avec toutes les informations pour chaque datavisualisation; https://docs.google.com/document/d/1Kaj5ADThtaAMhkYngFIZSDNHpebBeUJzRM4jcvd0uhA/edit
Cette étape n’a pas été très difficile, nous savions déjà pourquoi avoir choisi ce type de datavisualisation et comment la lire
5.3 Publication des datavisualisations
La publication a été aussi facile pour nous car nous étions accompagnés par un expert très sympa qui nous a aidé à tout publier sur la page opendatasoft de la commune de Rosny-sur-Seine.
Nous n’avons ainsi pas eu à faire les manipulations sur le site. Nous avons juste choisi la description. Par exemple, dans la datavisualisation petite enfance et équipement jeunesse nous avons trouvé cela pertinent de mettre en lien le portail famille de la ville.
Cette dernière journée se finit sur une réunion Zoom avec tout le monde afin de faire le bilan de ce challenge data. Puis de 17h à 18h s’est tenu un forum sur gathertown. Chaque commune avait un stand. Nous avons ainsi pu échanger avec d’autres groupes et des élus, leur montrer notre travail et discuter de ce que les autres avaient fait. C’était assez instructif. Nous avons pu tirer un bilan de cette semaine.
CONCLUSION
Cette semaine a été longue et intense, mais elle a surtout été riche en rencontres, en découvertes et en apprentissages. Nous avons pu ouvrir et mettre en valeur 4 jeux de données sur les 5 souhaités par la commune lors de nos premiers échanges. Parmi ces 4 jeux de données, ce sont 2 visualisations géographiques, 2 graphiques en colonnes, et un comparatif en bâtons qui ont pu être publiés sur la page Opendatasoft de la commune.
Les jeux de données concernant les équipements jeunesse et dédiés à la petite enfance, qui font l’objet des visualisations graphiques, étaient voulus par la commune pour faciliter l’accès des nouveaux arrivants à ces infrastructures. En effet, la population de Rosny-sur-Seine ne cesse d’augmenter depuis le début des années 2000. Ce sont principalement des familles avec des enfants qui ont besoin de ces informations pour répondre aux questions relatives à la garde de leur progéniture. Avoir des données géographiques et détaillées, incluant parfois la capacité totale de l’établissement, est donc un plus pour ces parents pour qui cette problématique est une priorité. En répondant à une attente réelle des habitants, cette publication correspond à la demande émise par la commune, que l’opération d’open data soit, avant tout, un service pratique rendu à la population de Rosny et de ses alentours. Dans la même optique, nous avons publié les budgets primitifs de la mairie depuis 2017 ainsi qu’une synthèse et un compte rendu sur la période. Comme nous l’a confié la cheffe du service des finances de la commune, la publication de ces informations répond à une nécessité de transparence quant à l’argent circulant dans la collectivité. Les données étaient particulièrement complètes, ce qui a été un atout majeur lors de la mise en qualité, mais rendait la compréhension peu aisée. Selon les conseils prodigués par Datactivist, nous avons donc réalisé une Treemap des dépenses pour 2020 ainsi qu’une autre pour les recettes. Cela a permis de rendre facilement lisible les principaux pôles de recettes et de dépenses de la collectivité, ainsi que leurs importances quantitatives. Nous avons aussi voulu mettre à profit la continuité des budgets sur plusieurs années et nous avons donc produit un graphique en barre décrivant les principales dépenses et leurs quantités pour les trois années qui étaient à notre disposition. Il fait apparaître des résultats très différents selon les années, des pôles de dépenses apparaissant et disparaissant, et leurs importances changeant grandement. Enfin, concernant les délibérations des conseils municipaux, la mise en qualité ainsi que la valorisation ont été plus complexes. Après avoir longtemps été mis en difficultés par des dates qui ne voulaient pas se conformer au modèle sur le logiciel workbench, la création de représentations graphiques s’est avérée très difficile. Nous avons essayé plusieurs solutions et cherché des conseils auprès des spécialistes de la plateforme opendatasoft, mais il a fallu nous rendre à l’évidence : nous ne pouvions pas publier un résultat qui serait lisible et représentatif. Le jeu de données est donc bien publié mais n’a pas pu être mis en valeur. La publication des délibérations reste une priorité de la commune pour des raisons de transparence et la publication du jeu y contribue tout de même.
Lors des différentes mises en qualité effectuées mercredi, nous avons tenté d’être le plus clair et efficace possible pour que les opérations puissent être reproduites facilement, surtout pour les données qui sont mises à jour régulièrement. Nous espérons que si la commune le souhaite, il sera plus aisé pour ses agents de reproduire ce qui a été fait pendant cette semaine et de façon la plus rapide possible. En effet, le retour le plus courant des agents était le manque de temps qu’ils pouvaient consacrer à la question des opendata. Rosny-sur-Seine est une commune dont le personnel est restreint et qui a pour but premier de se consacrer au service de ses administrés. Nous nous sommes donc attelés à faciliter à ses agents la tâche administrative que représente la publication de ses informations en opendata. Les agents municipaux n’ayant pas eu le temps de se pencher sur la question au préalable, il a premièrement fallu expliquer l’objet de notre mission et trouver les données qui nous étaient nécessaires. Cette recherche a été la partie la plus difficile pour nous, car il fallait à la fois savoir où elles se trouvaient, en cela notre référente a été d’une aide immense et a fait une grande partie du travail, mais il s’agissait avant tout d’obtenir des données exploitables. Beaucoup de documents disponibles étaient au format pdf et il a fallu décider lesquels valaient la peine d’être transformés en Excel. Nous avons donc discuté avec les différentes directions de service pour mieux cerner leurs besoins, et aussi profiter de leur expertise dans chaque domaine. Par la suite, ils ont eu l’immense gentillesse de consacrer de leur temps à produire puis à nous communiquer des documents que nous pourrions exploiter pendant la semaine qui nous été impartie. Il n’était pas facile d’arriver au sein de ces différents services et de leur demander un travail supplémentaire auquel ils n’étaient souvent pas préparés. Nous avons eu la chance d’avoir en face de nous des personnes qui ont compris l’importance de la démarche que nous effectuions et nous ont accordé du temps tout au long de la semaine. Nous sommes donc extrêmement fiers d’avoir pu produire un travail abouti pour remercier tous les acteurs de l’aide qui nous a été apportée.
En tant qu’étudiants de Sciences Po, notre plus grande crainte concerne le traitement des données. Ce n’est pas un exercice que nous connaissons ou maîtrisons. Il était donc difficile d’évaluer la quantité de travail qu’un ou plusieurs jeux de données pourrait nous demander. En cela, l’équipe de Datactivist et surtout notre coach Arthur, nous ont été d’une grande aide. Ils nous ont conseillés sur les jeux de données qui seraient intéressants ainsi que sur la quantité pour laquelle nous pouvions nous engager. Quand est arrivée la journée redoutée de la mise en qualité des données, nous avons été rassurés par la clarté des explications à notre disposition ainsi que la disponibilité des encadrants. Après quelques manqués à la découverte du logiciel, nous en avons compris la logique. Cela ne nous a pas empêché de faire face à des difficultés persistantes, comme le traitement des dates dans le fichier délibération et la nécessité de compléter les données des équipements de petite enfance et de jeunesse. Nous avons eu recours à l’aide de nos encadrants, et ce fut la journée la plus éprouvante de la semaine. Cependant, nous avons réussi en nous partageant le travail et en nous concentrant à plusieurs sur les différents problèmes rencontrés, à trouver des solutions dans la plupart des cas. Nous avons constaté de façon évidente les bienfaits d’une bonne répartition des tâches et de la capacité à savoir reconnaître qu’on a besoin d’aide pour ne pas perdre de temps inutilement. Nous avons aussi compris que ce n’est pas parce qu’un outil est inconnu que nous ne pouvons pas le maîtriser avec les bonnes indications et un encadrement adéquat. C’est une prise de conscience importante pour les étudiants à quelques jours du début de leur vie professionnelle. Être traité d’égal à égal par des interlocuteurs experts nous a aussi permis de prendre confiance dans nos capacités et notre travail. Ainsi, s’il nous fallait retenir une difficulté à laquelle nous n’avions pas été confronté auparavant, ce serait l’adaptation à nos interlocuteurs, et une réussite, ce serait notre capacité à dépasser ce que nous savons déjà pour s’approprier de nouvelles compétences.