Carnet de bord de l’ouverture des données du Pré-saint-Gervais
par Emma Thuy jomary, Marie Lacourty, Arthur Maimbourg, Daniel Dobias, Clothilde Borel et Alix Cariou
JOUR 1 – DIAGNOSTIC
Notre équipe travaille sur la ville du Pré-Saint-Gervais située en Seine-Saint-Denis dans la région Ile-de-France. Cette petite commune, limitrophe de la capitale, comptait en 2017 17 950 habitants pour une superficie de 0,7 km2. La commune est caractérisée par sa faible superficie et sa proximité à Paris.
A la suite de la réunion de présentation du matin, notre équipe se retrouve sur Gather pour faire le point sur les tâches à effectuer et prendre connaissance des outils mis à notre disposition (questionnaire, catalogue de données etc). Nous contactons notre référent 1, notre principal interlocuteur, et fixons un rendez-vous à 13h30. Après quelques difficultés techniques, nous décidons de nous répartir les tâches pour la réunion de l’après-midi :
- Alix Cariou se chargera de lire le questionnaire à nos deux intervenants.
- Clothilde Borel remplira ce même questionnaire en fonction des réponses.
- Marie Lacourty et Arthur Maimbourg se chargeront d’analyser les résultats et de filtrer les données en fonction de ceux-ci.
- Daniel Dobias rédigera la wishlist.
- Emma Jomary écrira le carnet de bord du jour.
Après une rencontre avec notre référent Allyson, nous préparons notre réunion de l’après-midi en ouvrant un google document pour y mettre toutes nos recherches et informations concernant la commune :
- Alix et Clothilde explorent le site web https://www.villedupre.fr et se renseignent sur la loi du 8 octobre 2016 pour une République numérique.
- Emma consulte également le site web en se focalisant plus particulièrement sur la rubrique “Ville numérique et solidaire” (https://www.villedupre.fr/ma-ville-change/ville-numerique-et-solidaire/).
- Marie se rend sur la fiche wikipédia de la ville pour collecter des informations générales (superficie, nombre d’habitants, maires…) et étudie les points forts de cette ville (les équipements culturels et l’organisation territoriale).
- Arthur et Daniel étudient le catalogue de données en profondeur afin de pouvoir expliquer de façon claire et précise chacune des rubriques à nos interlocuteurs.
Il est 13h30 et notre réunion peut commencer. Nous rencontrons nos deux interlocuteurs sur la plateforme Teams : nos référents 1 et 2.
Notre référent 1 est chargé du développement des outils et infrastructures numériques ainsi que de l’accompagnement des citoyens vers les nouveaux outils numériques (télétravail etc). Notre référent 2 a une connaissance très fine des dynamiques locales et pourra nous aider à réaliser des maquettes de données.
La motivation de la ville à ouvrir ses données est de respecter :
- la législation du 8 octobre 2016 pour une République numérique obligeant les administrations à ouvrir leurs données publiques. La ville n’est pas en règle car elle ne publie pas ses données et dispose d’une grande quantité de datas non classées.
- la volonté de la nouvelle équipe municipale d’opter pour une politique plus transparente et résolument tournée vers le numérique. En effet, depuis les élections municipales de mars 2020, l’adjointe au maire et élue “Jeunesse, transition numérique et politique de la ville”, elle est particulièrement intéressée par le développement de l’open data et les bienfaits que cela pourrait apporter à la ville.
A la suite du questionnaire et de la réunion, nous pouvons dresser le diagnostic suivant : le Pré-Saint-Gervais est une commune qui ne dispose pas de service ou de responsable exclusivement chargé du développement de l’open data. Nos interlocuteurs se sont saisis de cette mission mais ils possèdent des connaissances limitées sur le sujet (par exemple, ils ne connaissent pas les différentes solutions permettant de publier des données en open data). Notre référent 1 nous explique que, jusqu’à assez récemment, l’open data n’était pas un enjeu important pour la collectivité.
Ainsi, le personnel de la mairie est peu formé à l’open data. Si notre référent 2 espère pouvoir réaliser une formation open-data cet été, peu d’employés de la mairie seraient capables de transformer et/ou préparer un jeu de données par exemple.
Dès lors, les freins à la démarche open data au sein de la collectivité sont :
- un problème de connaissance et de sensibilisation à l’open data : beaucoup de fonctionnaires ne savent pas ce qui se cache derrière ce terme qui paraît assez vague et n’ont pas conscience des enjeux du sujet,
- des bases de données non organisées, non classées (doublons) et non centralisées (chaque service dispose de sa propre base de données). La mairie n’est pas dotée d’un outil de gestion de ces bases de données et, dès lors, elle ne dispose pas d’informations issues du traitement de ces données, les métadonnées. L’utilisation de celles-ci dans les processus de décision ou de prédiction de phénomènes est donc impossible : le Pré Saint-Gervais n’utilise pas l’informatique décisionnelle.
A la suite des réponses de nos interlocuteurs, nous découvrons que la maturité numérique de la ville est au palier 2. Avec ce résultat, nous passons donc en revue les différents types de données que nous pourrions exploiter et, avec l’aide de nos interlocuteurs, nous distinguons trois catégories :
- La première est constituée des données que nous ne traiterons pas pour cause d’absence de datas sur ces sujets et/ou la petite taille de la ville : équipements collectifs publics ; infrastructure de recharge pour véhicules électriques ; lieux de stationnement (gérés en externe) ; lieux de covoiturage ; établissement d’accueil petite enfance ; monuments historiques ; emprunts des livres.
- La seconde réunit les options intéressantes mais non prioritaires ou réalisables pour le moment : marchés publics (la majorité du service est partie) ; îlots de fraîcheur - équipement (cela concerne le plan canicule et ce n’est pas une priorité en février) ; espaces verts ; parking à vélo (peut-être dans trois ou quatre ans).
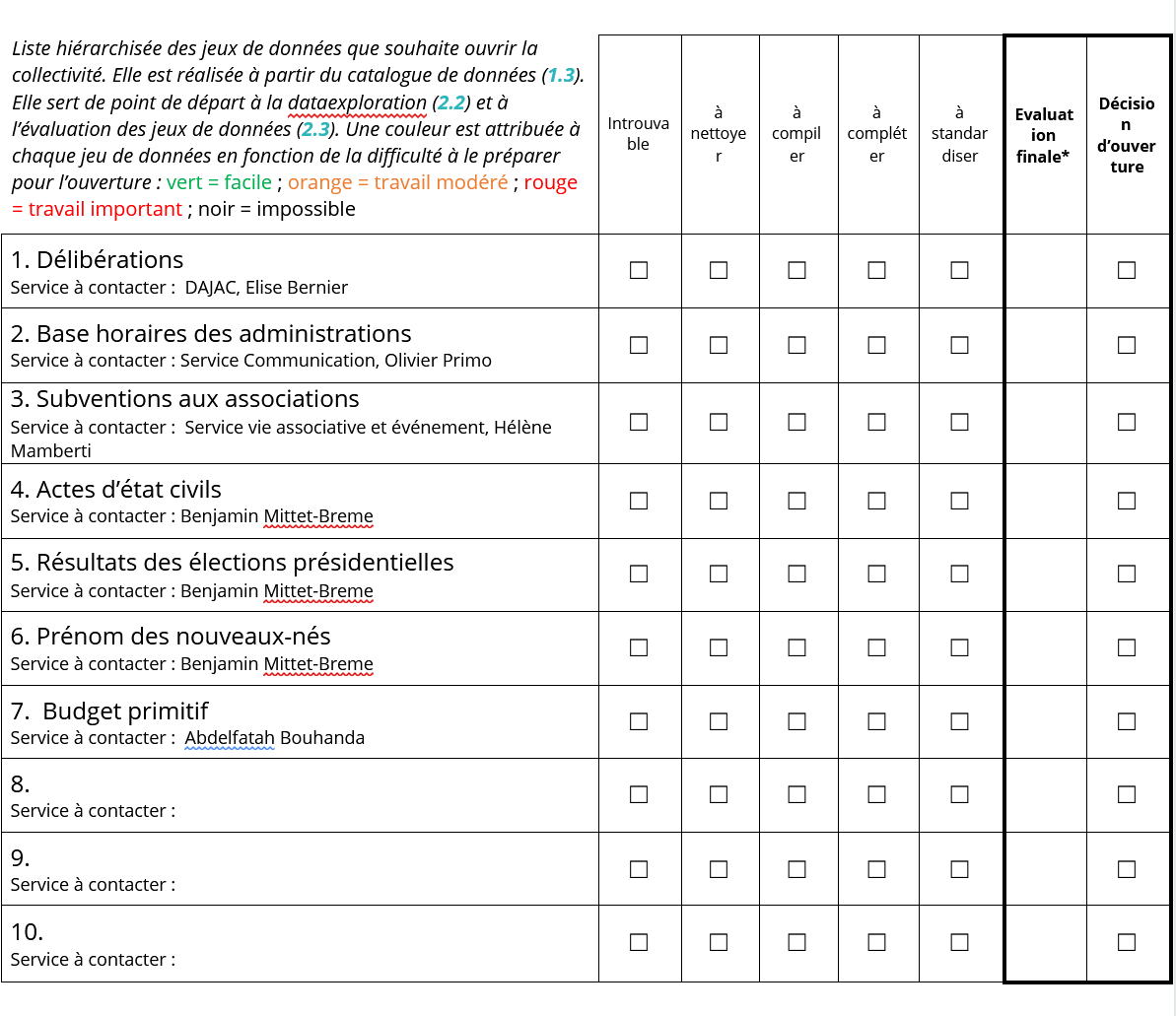
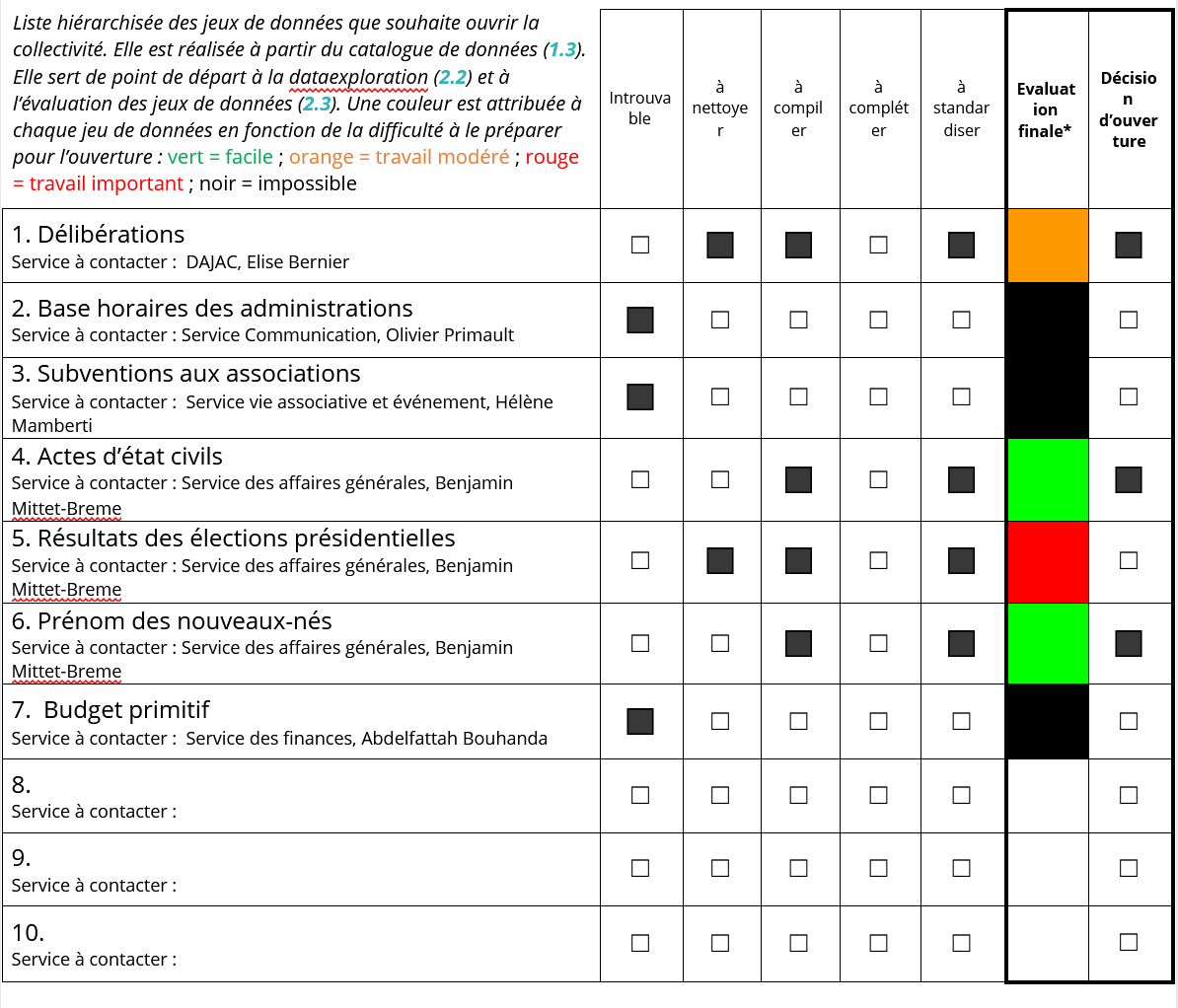
- Enfin, la dernière catégorie est constituée des données que nous avons retenus (classées par ordre) et qui constitueront notre wishlist :
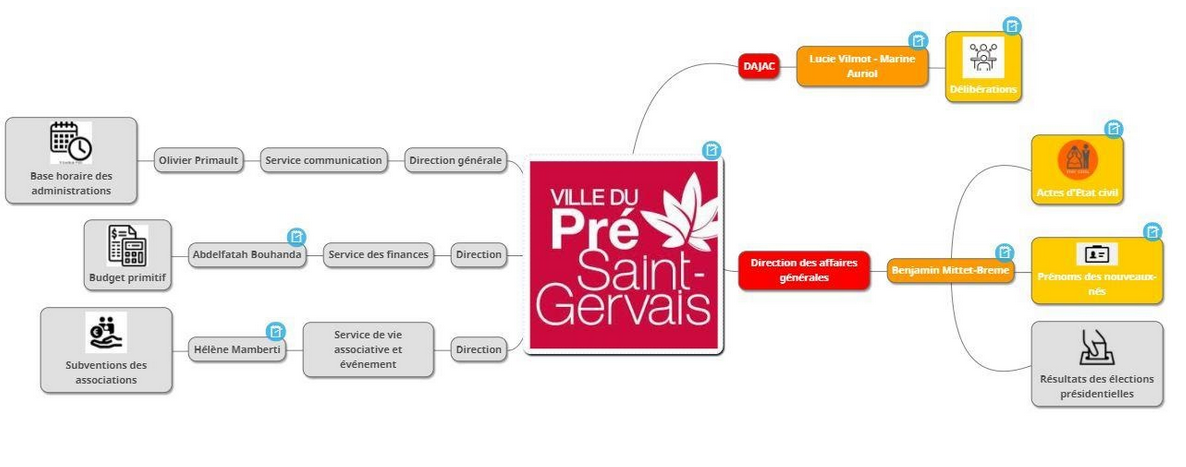
1° Délibérations : ces données sont essentielles pour l’externe (les citoyens) et l’interne (les fonctionnaires). De plus, une base de données assez conséquente existe sur ces questions (ex : délibérations lors des conseils municipaux).
2° Bases horaires des administrations : Notre référent 1 évoque un problème propre à sa collectivité qui est que les horaires de la mairie et des différents services ne sont pas affichés sur le site web. Un traitement de ces données permettrait donc plus d’efficacité.
3° Subventions : cette catégorie est intéressante car elle est l’un des objectifs de la nouvelle équipe municipale qui désire plus de transparence quant à l’attribution des subventions par la ville, notamment celles pour les associations. Cependant, ceci touchant à des questions financières, il est nécessaire que la mairie valide l’ouverture de ces données.
4° Les résultats des élections présidentielles
5° Actes d’état-civil : il existe une base de données importante et plutôt bien classée grâce au logiciel Arpège et aux données déjà envoyées à l’INSEE.
6° Budgets primitifs : la collectivité dispose de nombreuses données à ce sujet mais il est, ici aussi, nécessaire d’obtenir l’autorisation de la mairie pour les traiter.
7° Prénoms des nouveaux-nés
JOUR 2 – IDENTIFICATION
Dès 9 heures ce mardi, on participe à la réunion matinale avec notre expert Allyson. Petite nouveauté pour ce deuxième jour, on a décidé de tous se retrouver physiquement pour travailler ensemble. Quoi de mieux que d’être tous réunis pour se lancer dans la dataexploration.
En effet, ç’a été un véritable avantage de pouvoir être en présentiel, on a pu dès le départ se concerter et créer un « plan d’action » pour la journée de façon efficace. La communication est bien plus facile (le lundi on a eu pas mal de petits problèmes informatiques et techniques), on gagne beaucoup de temps, on confronte et accorde plus facilement nos différents points de vue et nos compréhensions des démarches à suivre et enfin, on a créé une ambiance à la fois sérieuse et détendue, qui a stimulé notre motivation à avancer dans le challenge data et à produire un contenu de qualité.
Cela peut paraître anecdotique mais Marie a par exemple récapitulé tous les jeux de données que nous obtenions et les personnes qui nous les fournissaient au fur et à mesure sur une grande feuille. On a aussi affiché l’écran d’ordinateur sur la télé (grand écran) pour que tout le monde puisse suivre et interagir lorsqu’une personne s’occupait d’une étape importante.
Pour commencer cette dataexploration, on s’est lancé rapidement dans une longue série d’échanges de mails et d’appels avec les membres de la collectivité du Pré Saint-Gervais pour obtenir les jeux de données sur lesquels on s’était entendu la veille.
Encore une fois, il a été très pratique d’être tous présents pour être informés en temps réel des éléments qui nous sont livrés par la collectivité. Parfois, les responsables de la collectivité nous posaient des questions plus précises sur ce que nous voulions exactement, par exemple en termes de format des jeux de données (format pdf, excel, archives manuscrites, etc.). On n’a pas toujours été en mesure de répondre de façon instantanée mais le fait d’être tous ensemble nous a permis de bien nous compléter et de prendre le relai dès qu’une personne avait des doutes. J’ai trouvé cela très constructif.
Parmi les questionnements auxquels on a été confrontés, on peut évoquer les suivants :
-
un membre du service des affaires générales pouvait ouvrir les archives et nous chercher des données (concernant les actes d’état civil et les prénoms des nouveau-nés). Il nous a posé une question sur la taille de l’extraction de données que l’on souhaitait. Il nous a expliqué que pour les actes de naissance, il avait plus de 70 000 données (sur 220 ans). Finalement on a dû se poser la question de l’antériorité des données. Est-ce pertinent pour nos jeux de données d’avoir des données très anciennes ? et surtout quelle quantité de données on a le temps de traiter ? On a donc demandé aux experts et on s’est fixé aux 3 dernières années pour les prénoms et aux 20 dernières années pour les actes d’état civil (naissance, mariage et décès).
-
De même, on a dû se poser la question de savoir ce qu’on était capables techniquement de réaliser (et en temps limité) en termes de traitement des bases de données que la collectivité nous proposait. Le service des affaires générales nous a par exemple expliqué qu’il avait des jeux de données qui nécessitaient une automatisation du traitement. Après avoir consulté les experts, nous n’avons pas pris ce type de données.
-
Par ailleurs, on a dû prendre en compte le fait que certaines données ne nous sont pas accessibles (juridiquement pas possible), que certaines données sont privées et qu’on ne peut donc pas les traiter (par exemple le nom des personnes concernées : mariage, décès, etc).
-
De plus, pour certaines données qu’on avait prévu de traiter le lundi, nous n’avons pas eu l’autorisation (la validation) par la mairie, notamment parce qu’il s’agissait de questions financières. On a donc évacué le traitement des données concernant les subventions et les budgets primitifs.
En fin de compte, la récupération des jeux de données s’est très bien passée et a été plutôt rapide. Je pense qu’on a eu beaucoup de chance car tous nos contacts ont été très réactifs et très à l’écoute, la communication interne à la collectivité concernant le challenge data réalisée par notre référent 1 a été très efficace et la disponibilité de nos interlocuteurs nous a rendu le travail agréable. La récupération des données a pu être complètement achevée au cours de la matinée. On a en revanche dû laisser tomber le jeu de données sur les bases horaires de la collectivité étant donné que la personne chargée de ces données est en congé.
De même concernant notre coach datactivist, on a pu se réunir très régulièrement tout au long de la journée. Sur gather, on partage nos écrans avec Allyson et on le met en copie de tous nos mails échangés avec la collectivité du Pré Saint-Gervais pour qu’il soit informé en temps réel.
Cela nous a permis de faire de nombreux points sur l’état de nos questionnements, de notre avancement et de continuer sereinement dans notre dataexploration. En plus de continuer sereinement, on poursuit avec bonne humeur : on fait tous danser nos personnages sur gather autour de la table pour en témoigner - distanciel oblige.
Maintenant, plus précisément, concernant les autres étapes de la dataexploration :
-
On a rempli collectivement la mindmap, ce fut rapide et cela a apporté de la clarté et de la lisibilité (notamment lorsqu’on la communiquera à la commune) à tous les éléments qu’on a en notre possession.
-
On s’est familiarisé avec Workbench, Arthur a uploadé toutes les données qu’on a recueilli sur la plateforme. Pour les fichiers excel qui nous ont été transmis on n’a pas eu de souci. En revanche, on a opéré quelques regroupements de plusieurs fichiers excel en un seul pour avoir toutes les données d’état civil sur un même document par exemple. S’agissant du jeu de données sur les résultats aux élections présidentielles de la ville du Pré Saint-Gervais, on a eu quelques difficultés car les données nous ont été transmises sous forme de pdf. Allyson nous a conseillé d’utiliser Tabula pour pouvoir les uploader sur Workbench.
Une fois toutes les données uploadées, on s’est attaqué à l’évaluation de la qualité de nos données. On possédait 4 jeux de données, on les a tous évalués et finalement on en a retenu 3.
Nous avons gardé, sur notre wanted list :
-
Les actes d’état civil : on a jugé qu’il y a peu de travail de nettoyage, que le travail de compilation ne devrait pas trop être trop important (quelques données sont manquantes et d’autres sont incohérentes et erronées concernant les années de naissance : on a par exemple des individus nés en 2206 ou encore en 5000). Les données sont exhaustives et en termes de standardisation, seulement l’expression des dates est à modifier. Ainsi, on a considéré que le traitement de ces données serait facile.
-
Les prénoms donnés aux enfants : on n’a pas de travail de nettoyage à réaliser, on doit ajouter certaines informations (le sexe des enfants notamment, on ne sait pas exactement comment on va procéder pour ajouter ces informations car on n’est jamais certains du sexe à partir d’un prénom). Il n’y a pas de travail de complétion à réaliser et le travail de standardisation est simple. L’ouverture de ce jeu de données nous a donc paru facile.
-
Les délibérations : le jeu de données n’est pas propre (notamment concernant les ordres du jour), le travail de compilation apparaît assez important (il manque notamment l’année du budget, le nom du budget et les informations en termes de vote). Toutefois, nous n’avons pas noté de travail de complétion et de standardisation à réaliser. Finalement, on a classé ce jeu de données comme étant modérément difficile à ouvrir. Le travail semble important mais on s’est dit qu’il était intéressant à réaliser, d’autant plus que notre référent 1 nous a expliqué que la publication des données de délibérations est la plus utile et intéressante pour la commune à l’heure actuelle.
Le jeu de données « impossible » à préparer pour l’ouverture :
- Les élections présidentielles : on a relevé un travail de nettoyage assez conséquent, de même que de compilation (le tour, la date, le quartier, le bureau, les procurations sont des exemples d’informations manquantes). Sur le plan de la standardisation, il y a également un gros travail à faire (c’est notamment lié au fait que nos données sont issues de pdf). On a donc estimé que l’ouverture de ce jeu de données nécessitait un travail important, ce qui nous a logiquement conduit à se séparer de ce jeu de données pour la publication. Ce choix a été également motivé par le discours de la collectivité au sujet de ces données, et notamment notre référent 2 qui nous les a fournies : pour lui, ces données ne sont pas une priorité pour faire l’objet d’une publication car elles sont déjà faciles d’accès (sources ouvertes à tous) de façon générale.
Après avoir fait valider nos choix par Allyson, on peut dresser le bilan suivant : on s’engage à publier 3 jeux de données, les actes civils et les prénoms nous paraissent faciles à traiter, les délibérations un peu moins mais elles sont aussi celles qui intéressent le plus la collectivité et donc qui nous challengent le plus.
Avoir réduit nos jeux de données à 3 nous laisse la possibilité de travailler sur plusieurs types de données tout en se focalisant quand même sur un nombre réduit, ce qui nous permet de prétendre à un travail de qualité. On part sereins pour mercredi matin, et nos objectifs finaux se dessinent de mieux en mieux donc la motivation est elle aussi à l’ordre du jour.
JOUR 3 – MISE EN QUALITE
A 9h, nous suivons la réunion habituelle durant laquelle nous prenons une photo de groupe avec notre coach. Nous avons beaucoup de travail aujourd’hui et il est donc encore plus important de commencer la journée dans la bonne humeur.

Il s’agit aujourd’hui de faire la mise en qualité de nos données afin de les rendre utiles. Nous allons donc traiter les différents jeux de données que nous avons conservés.
Etape 1 : le Nettoyage :
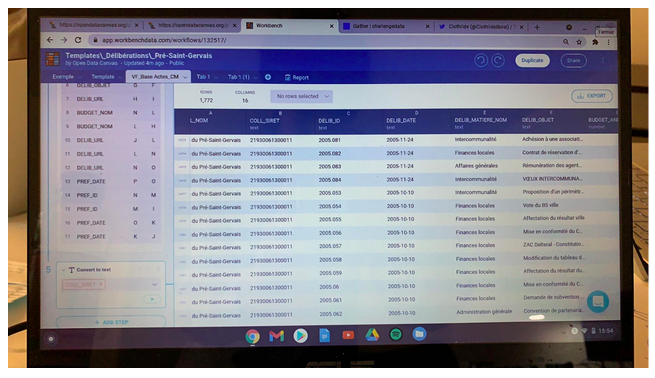
Pour les délibérations : Nous choisissons de garder la matière, le titre et toutes les dates. L’étape suivante est de corriger les fautes de frappe et de typographie. Nous supprimons également les doublons. On passe finalement de 2 255 à 1 772 lignes. Avant 2003, les matières de délibération n’étaient pas indiquées, nous avons donc décidé de les retirer.
Pour les prénoms : Nous ne gardons que les lignes où il y a le prénom de l’enfant et sa date de naissance, ce qui en a retiré 2.
Pour les actes d’état civils : On enlève les évènements où la date n’est pas notée, ce qui a retiré 2 lignes également.
Etape 2: la Compilation
Pour les délibérations : Arthur a ajouté le code siret pour se conformer à l’exemple.
Pour les prénoms : Nous avons deux types de données, les données externes et les données internes. Nous compilons le fichier des enfants qui ont au moins un parent qui vient du Pré Saint-Gervais mais sont nés ailleurs (externe) et le fichier comprenant les quatre enfants qui sont nés sur le territoire du Pré Saint-Gervais (interne). Nous éprouvons des difficultés à fusionner les deux fichiers, il faut pour cela ajouter les données grâce à la formule “Cancatenate tabs” que nous avons découverte après plusieurs essais.
Etape 3 : la Complétion
Pour les prénoms : Nous avions initialement complété la case “Occurrences’’ afin de savoir combien chaque prénom a d’occurrence sur les 688 prénoms. Cela peut être intéressant à connaître afin de voir les tendances par années. Nous écrivons finalement 1 partout dans le nombre d’occurrence, puisque nous ne pouvions pas regrouper toutes les mêmes occurrences d’un prénom sur une même case.
Nous éprouvons une difficulté puisque certains enfants ont plusieurs prénoms et que comme, pour certains, il y a des virgules et pour d’autres non, nous ne savons pas si l’enfant a un prénom composé ou s’il s’agit d’une erreur et que la virgule entre le prénom et le deuxième prénom a été oubliée. Nous choisissons de garder les lignes dans lesquelles il n’y a pas de virgule entre les prénoms. On considère donc qu’il s’agit des prénoms secondaires après la virgule.
Autre problème, les dates des trois premières lignes de jeu de données n’ont aucun sens. Nous n’avons pas de moyen de savoir s’il s’agit de vraies naissances, ou de fautes de frappe alors nous les supprimons.
Etape 4 : la Standardisation
Pour les délibérations :
Nous avons dû changer les noms des matières de délibération. Nous avons rencontré un problème puisqu’il fallait ajouter des colonnes à partir de l’exemple standard mais il nous manquait les données. Après avoir vu avec le coach Arthur, ces données n’étaient pas nécessaires pour la validation mais nous avons eu un problème de structure car il manquait des colonnes (les votes et le nom du budget), nous avons donc dû créer des colonnes vides pour que le jeu de données soit validé par le site validata. Malgré tout, même si nous n’avions plus d’erreurs de structures, le fichier n’est précis qu’à 80%, le niveau de précision n’est pas parfait et cela s’explique par le fait que le nom de matière de délibération pourrait être plus précis. Il y des sous catégories de délibération que nous n’avions pas à disposition.
Pour les actes d’état civils :
Nous avons eu un problème car nous ne savions pas si on devait garder la colonne Dates de décès. Nous avions la date de décès et aussi une date de déclaration de mort sauf que cette colonne n’existe pas dans les standards que l’on nous a proposés. Nous nous sommes donc demandé s’il fallait la garder. Ce qui est intéressant pour la garder c’est que pour certains morts nous n’avons pas la date de décès mais seulement la date de déclaration de leur mort. Nous avons vu avec notre coach Allyson que cela pourrait être intéressant par la suite pour faire de la datavisualisation avec des deux catégories pour voir les différences entre le jour du décès et sa déclaration à la mairie.
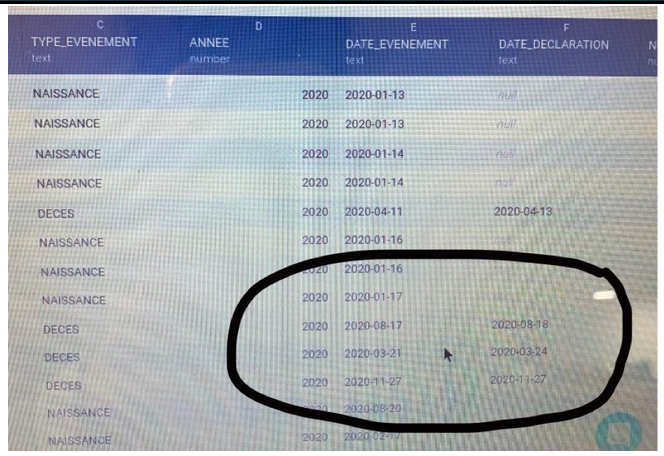
Nous avons eu un problème avec la standardisation des dates. Au début nous avions une date présentée de la façon suivante : MM-JJ-AA. Cette notation est peu commune, nous avons eu beaucoup de mal à trouver comment retranscrire ça sous la forme standardisation qui est : AAAAMMJJ. Sachant que l’on a plus de 7000 données.
On a remarqué que la base de données de Pré n’est pas du tout standardisée car sur l’acte civil nous avons eu le format de date MM-JJ-AA alors que pour les prénoms il y avait une autre forme.
Pour résoudre ce problème, le coach Arthur nous a aidé et nous avons réussi à avoir la date dans le bon ordre mais quand même avec des tirets. Ce n’est pas grave car la base de données ne doit pas être soumise à validation.
Pour les prénoms :
Il était nécessaire de retirer les deuxième prénoms et comme nous n’avons pas trouvé de meilleure manière de le faire, nous les avons retirés manuellement et cela nous a pris un temps assez conséquent.
Pendant la journée d’hier, un troisième interlocuteur nous avait donné un premier jeu de données. Celui-ci étant en congé aujourd’hui, nous avons demandé à un second interlocuteur, notre référent 2 afin qu’il nous transmette les données concernant les sexes des enfants. Il y a des incohérences entre les différents fichiers que nous avons reçus. Cela a causé beaucoup d’incompréhension au sein du groupe car les enfants des deux listes n’étaient pas du tout les mêmes et donc il nous était impossible. Nous avons décidé de traiter le premier jeu de données que nous avions déjà traité. Nous n’avons donc pas inscrit les sexes des enfants puisqu’ils étaient sur le deuxième fichier.
Bilans des traitements exportés depuis Workbench :
Délibérations : https://app.workbenchdata.com/workflows/132517/?fbclid=IwAR3pdB3OP2Hz5N8lOV4SZLKvlwg94Fzj11hvVqop8Mrfo9-kHZDvuB0NVYE
Actes d’état civil : https://app.workbenchdata.com/workflows/132653/?fbclid=IwAR0njaoyckFto0u4hqNFtEZH3Rc9xRtKksD5Vt1iTrLPPuFSVjO7ouoTfAM
JOUR 4 – PUBLICATION
Comme les jours précédents, nous nous sommes retrouvés dans l’appartement d’Arthur (notre coéquipier) à Saint Germain en Laye tout en respectant les barrières sanitaires.
4.1) Compléter la fiche descriptive des jeux de données
Dès 8:00, nous avons envoyé un mail à notre référent 1 de la commune pour fixer un rendez-vous afin de compléter les fiches descriptives. Le rendez-vous a été fixé pour 10:00 via l’application Teams de Microsoft.
A 9:00, nous avons eu une présentation avec notre coach Allyson pour faire le point de la journée d’hier mais surtout il nous a présenté la quatrième journée. Les explications étaient claires et efficaces. Par exemple, nous avons appris de nouvelles choses concernant les applications web de stockage des données comme CKAN ou Sans. Aussi, il nous a présenté le site web data.gouv.fr. Il s’agit d’un site du gouvernement français qui est responsable de la diffusion des données publiques de la France. Les informations acquises lors de ce rendez-vous nous ont été utiles pour le reste de la journée.
Comme conclu précédemment, à dix heures, nous avons commencé notre réunion avec notre premier référent. Notre coach était également présent à ce rendez-vous. D’abord, nous avons expliqué nos progrès dans le travail tout en envoyant les liens pour nos bases des données. Notre référent 1 a beaucoup apprécié notre travail. À la question d’Allyson qui consistait à savoir si cela correspond à ses attentes, elle a confirmé qu’il s’agissait “d’un travail formidable” et qu’elle était contente de “mettre les pieds dans l’Open Data”. Durant la deuxième partie de notre appel, nous avons posé des questions afin de compléter les fiches descriptives. Malheureusement, les réponses étaient de temps en temps “vagues” parce que certaines données nous ont été envoyées par un collègue de notre référent 1 qui était en vacances depuis mardi soir.
Nous avons rempli ensemble trois fiches descriptives : sur les délibérations, prénoms des nouveau-nés et actes d’État civil. Sans rentrer dans les détails et les spécificités de chaque fiche, nous pouvons brièvement mentionner les éléments communs : la commune souhaite actualiser les données une fois par an (à l’exception des délibérations où ce sera quatre fois par an). Les raisons de la production de ces données ont été plus ou moins semblables. En effet, la commune souhaite faciliter l’accès à ces données en les publiant dans le cadre de l’Open Data tout en étant plus transparentes. La commune souhaite également montrer davantage la vie de la commune et sa structure démographique et civile.
Pendant la réunion, nous avons également demandé le contact du service de la Communication afin de discuter et d’affiner la stratégie de la communication des données et du projet Open Data. Cependant, la responsable de ce service est en congés maternité, alors il était impossible de la contacter. Après la discussion avec notre coach et notre référent 1, nous avons conclu que nous allions proposer une stratégie de communication de ces données. Puis, une fois que la responsable de service reviendra, cette stratégie lui sera proposée et ce sera à elle de l’accepter ou non.
Le dernier sujet abordé a concerné l’inscription de la ville du Pré Saint-Gervais sur data.gouv.fr. Nous avons donc demandé le logo de la ville afin de pouvoir réaliser cette inscription. Le logo a été envoyé ultérieurement par notre référent 1. La réunion s’est terminée à 10:30.
Une fois la réunion terminée, nous avons mis au propre les fiches descriptives. Cela s’est déroulé sans soucis particuliers car nous possédions toutes les informations grâce au précédent rendez-vous.
Pendant ce travail, notre coach est venu nous informer que le groupe 3 (Neuville Saint-Rémi) avait rencontré le même problème que nous concernant la colonne “sexe” dans le jeu de données sur les prénoms des nouveau-nés. En effet, notre problème était que les données envoyées par la Commune n’avaient pas de contenu dans la colonne “sexe”. Mais, le groupe 13 nous a conseillé de fusionner notre tableau Excel contenant les informations de la part de la Commune et une base de données sur le site data.gouv.fr où, pour une large base de prénoms, il est mentionné s’il s’agit d’un garçon ou d’une fille. Grâce à cette fusion, trois quart des prénoms dans excel ont été automatiquement indiqués comme fille ou garçon. Quant au reste du fichier où le sexe n’était pas déterminé, nous l’avons donc indiqué par nous-même.
Le deuxième problème que nous avons rencontré par rapport à notre travail d’hier était que pour les enfants nés hors (externe) de la commune du Pré Saint-Gervais, le Code INSEE qui apparaissait correspondait toujours au Code INSEE de la ville du Pré Saint-Gervais. Après avoir consulté Allyson, nous avons décidé de le garder ainsi. En effet, ces enfants vivent probablement au Pré Saint-Gervais comme au moins un de leurs parents y habite, seulement leur lieu de naissance est hors de cette commune.
4.2) Publication des données et de la fiche descriptive sur un portail open data
Une fois la fiche descriptive remplie et les imprécisions d’hier réglées, nous sommes passés à l’étape de la publication des données sur le site data.gouv.fr.
Nous avons d’abord créé le profil de notre commune car il n’existait pas encore. Nous avons donc ajouté leur logo tout en écrivant une petite description de la Commune.
Une fois cette étape passée, nous avons complété les métadonnées sur nos jeux de données. Ce processus s’est déroulé sans difficultés significatives. Ce qui nous a pris le plus de temps a été de bien remplir la description de chaque jeu de données pour qu’elle soit la plus compréhensible et complète possible pour les futurs utilisateurs. À la fin de chaque fichier, nous avons bien précisé qu’il était réalisé par des étudiants lors de la semaine de Challenge Data. Ensuite nous avons ajouté notre référent 1 dans l’administration du compte de la commune Le Pré Saint-Gervais afin qu’il puisse l’utiliser dans le futur.
Nous avons également envoyé un mail afin que notre organisation soit identifiée et certifiée comme un service public. Quelques heures plus tard, nous avons reçu une réponse qui confirmait alors que cette organisation avait bien été identifiée comme un service public.
A 14:40 les travaux de la publication étaient finis et nous sommes passés à la dernière étape de la journée.
4.3) Préparation de la communication de la commune autour de l’ouverture des données
Comme nous l’avons déjà indiqué, nous n’avons pas pu contacter la personne responsable du service de communication alors nous avons établi une stratégie de communication par nous-même. Grâce à l’aide de notre référent 1, nous avons pu identifier les canaux de communication qui sont les plus utilisés par la commune. Il s’agit de Facebook, YouTube, de leur site Internet et de LinkedIn.
En utilisant template, nous avons essayé d’établir notre stratégie de communication. Nous nous sommes surtout basés sur le fait qu’il s’agit d’une assez petite commune donc nous avons opté pour la stratégie qui s’inscrira dans les réalités locales et qui serait donc réellement envisageable par les services de la Communication. Nous avons donc essayé de formuler une stratégie où la commune serait capable de s’approcher le plus des habitants de la commune par différents moyens : non seulement digitaux mais également par la presse écrite ou bien avec une interaction directe avec le personnel de la commune qui s’engage dans Open Data. Le but envisagé est de s’adresser au plus grand nombre de personnes, de gagner leur confiance en étant le plus transparent possible et de les sensibiliser aux avantages que les Open Data peuvent apporter.
À la fin de la journée, nous avons envoyé un mail à notre référent 1 et Allyson afin de faire un point sur la journée et en leur expliquant les décisions prises.
Url des jeux de données publiés : https://www.data.gouv.fr/fr/organizations/le-pre-saint-gervais/#datasets
JOUR 5 – VALORISATION
Pour ce dernier jour, c’est le cœur un peu nostalgique que nous nous sommes retrouvés à saint germain en laye. Comme chaque matin nous assistons à la réunion avec les coachs. C’est Julia aujourd’hui qui nous explique le déroulement de la journée car Allyson n’est pas disponible. C’est donc Etienne de Datactivist qui nous aidera ce matin.
Pour que nous soyons tous certains de la manière de procéder nous regardons ensemble les vidéos. Il s’agit aujourd’hui de valoriser les données que nous avons collectées et ouvertes sur data.gouv en les représentant visuellement. Nous commençons à réfléchir ensemble sur l’ensemble des données: comment les représenter, quelles données devons-nous choisir en particulier? Quelles interprétations pouvons-nous leur donner ? etc.
Pour les actes civils nous commençons par nous dire qu’il faut comparer les décès et les naissances afin d’analyser l’évolution de la population. Pour cette comparaison, nous pensons à un diagramme en bâton, plus représentatif. Cela permettrait également d’observer les pics de naissances / décès/ mariages.
Pour les délibérations, nous nous disons qu’il serait intéressant de représenter l’occurrence des matières sur la période de 2003 à 2020 avec un graphique compartimentage ce qui nous permettrait ensuite de réduire nos variables aux seuls sujets les plus abordés afin de les analyser par rapport aux années.
Pour les prénoms, en revanche…. nous n’avons pas d’idée !
Nous nous mettons au travail: suivant les conseils des coachs, nous nous mettons en groupe de deux et nous nous répartissons les jeux de données (ce sera plus efficace !!).
Et c’est parti: Emma et Alix s’occupent des données relatives aux actes civils, Daniel et Arthur des prénoms (très gentleman… ils ont pris le sujet sur lequel nous séchions !) et Clothilde et moi, les délibérations.
Pour chaque groupe la première difficulté a été de se familiariser aux différents logiciels de création de graphiques. Nous avons dû essayer tous les sites, observer les différentes fonctionnalités et regarder quels modèles graphiques pourraient correspondre aux données.
Les logiciels proposés par Datactivist (Rawgraphs et opendatasoft) ainsi que workbench ont véritablement été nos principales difficultés. En effet nous n’avons pas toujours réussi à trouver les modèles graphiques que nous souhaitions pour représenter au mieux nos données. Nous avons donc dû nous adapter et ce, en changeant parfois nos choix.
- Alix et Emma: Les actes civils
Alix et Emma ont d’abord cherché et testé les différents logiciels afin de trouver les meilleurs modèles graphiques. Elles ont très vite écarté Workbench car le jeu de données des actes civils possède différent type d’évènement au sein d’une même colonne et sans transformation en nombre (les données événements sont en format texte) il était impossible de les représenter sur ce site. Ainsi les filles ont choisi d’aller sur opendatasoft ce qui leur offrait la possibilité de faire des diagrammes en bâtons. Le logiciel était compliqué à s’approprier, les filles ont dû se créer un compte et au bout de quelques essais mêlant maîtrise, chance et hasard elles ont obtenu un graphique en bâton permettant de comparer les naissances, les décès et les mariages. Afin de diversifier les visualisations, elles ont également réalisé un diagramme en courbe. Ces deux graphiques permettent donc de comparer plus facilement les grandes tendances des mariages, naissances et décès sur 20 ans.
Le diagramme en bâton
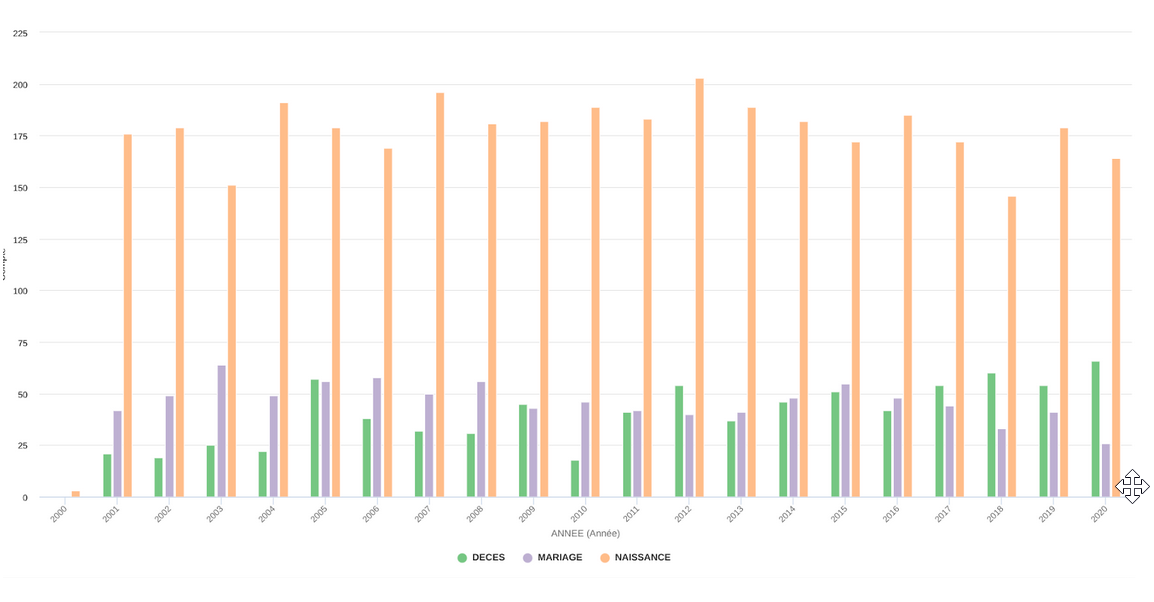
Le diagramme en courbe:
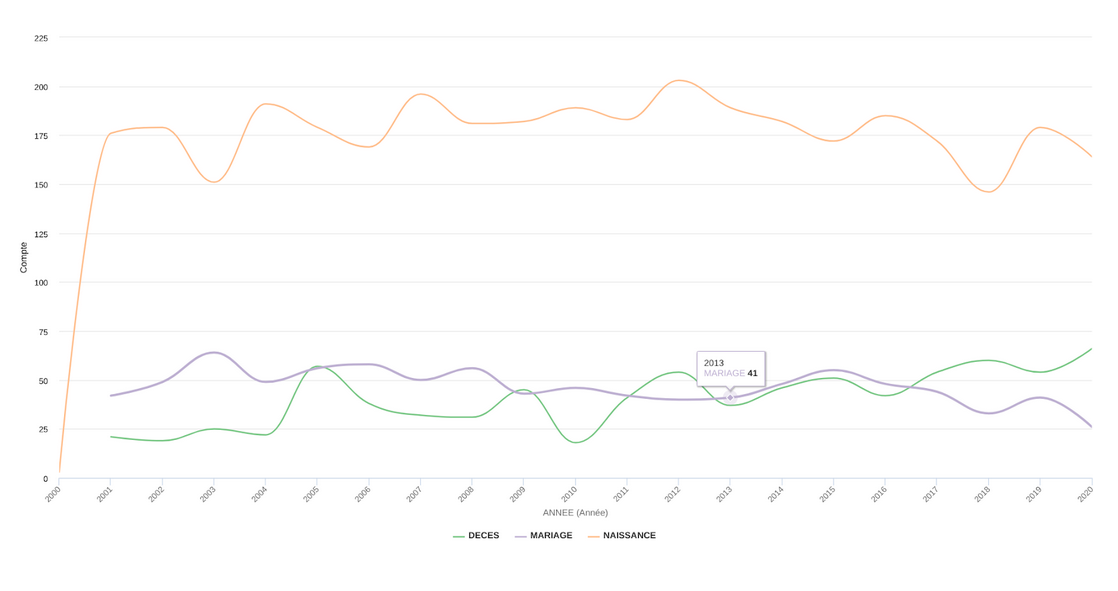
Difficultés:
- Il faut faire attention à l’interprétation des données. En effet l’axe des abscisses est sur la base des années cependant tous les jeux de données ne commencent pas toujours en 2000 (les décès et les mariages ne sont pas représentatifs en 2000 car les données collectées les concernant ne commencent qu’en 2001). La même chose se produit pour l’année 2020.
- De plus, les filles ont voulu représenter l’écart entre le décès et la déclaration de décès afin d’analyser le temps entre ces deux moments. Néanmoins elles n’ont pas trouvé cela pertinent au vu de l’écart, souvent très court (un jour environ). Enfin, elles ne savaient pas vraiment comment matérialiser cela sur un graphique.
- Daniel et Arthur: Les prénoms
Les garçons se demandent d’abord quelles données représenter: les sexes ? les prénoms? les occurrences? les préférences des prénoms?
Le jeu de données qu’ils possèdent amenait à réaliser des diagrammes de répartition et de distribution des données, c’est pourquoi ils ont décidé de choisir les histogrammes. Leur premier histogramme a été réalisé sur workbench: il représente les 10 prénoms les plus donnés entre 2018 et 2020. La seule réserve de ce graphique est le manque d’exhaustivité puisqu’il s’agit seulement de 10 prénoms (sur une courte période) dont l’occurrence n’est pas si élevée.
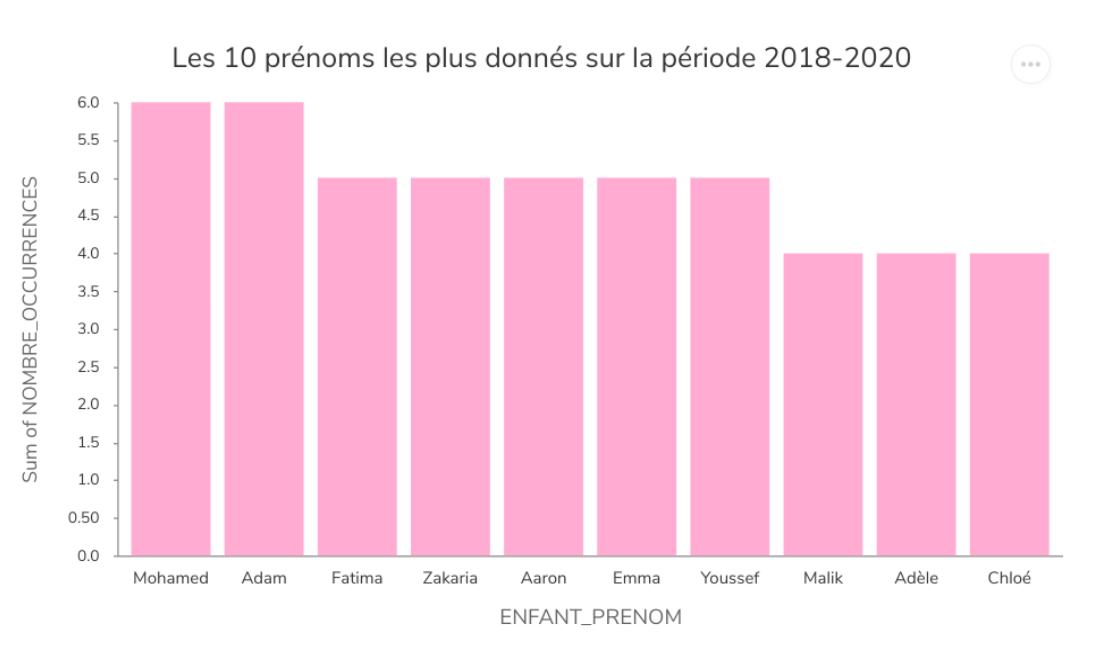
Ensuite les garçons ont voulu analyser la répartition des prénoms en fonction du sexe. Pour cela, ils ont choisi d’utiliser opendatasoft.
Ils ont d’abord réaliser un simple diagramme circulaire pour regarder la répartition entre les sexe masculin et féminin sur la période 2018-2020. Enfin, pour observer la répartition des sexes selon les années (2018- 2019 -2020) ils ont réalisé un autre diagramme à barres empilées.
Diagramme circulaire:
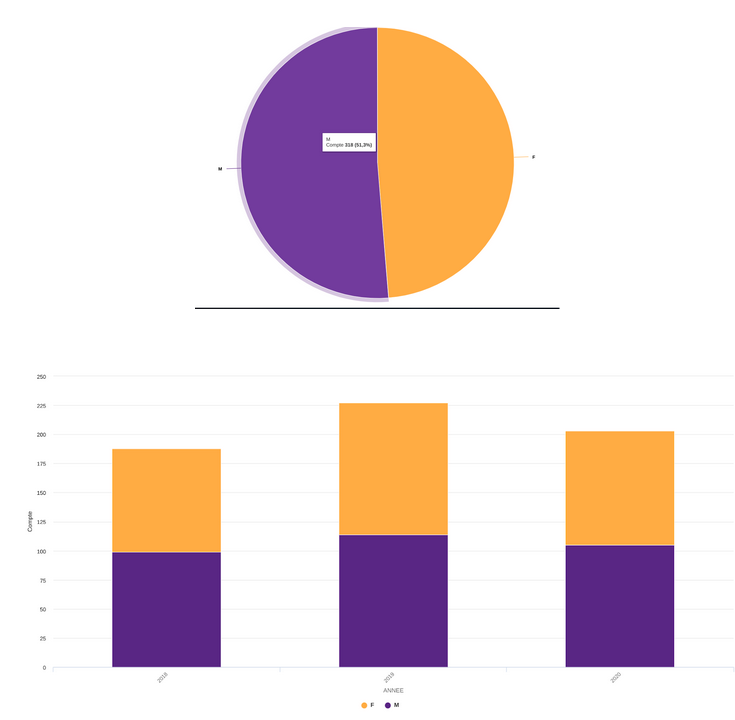
Diagramme à barres empilées
Pour terminer, les garçons se sont un peu amusés !! Ils se sont dit que l’intérêt d’avoir des graphiques était d’aider les parents, habitants de la ville, à choisir les prénoms de leurs futurs enfants en leur offrant une visibilité sur les prénoms les plus choisis.
Ils ont donc réalisé un diagramme en bâton pour chaque année avec les trois prénoms les plus utilisés, cela pour le sexe masculin et le sexe féminin:
Diagramme en bâton des trois prénoms masculins les plus utilisés par année
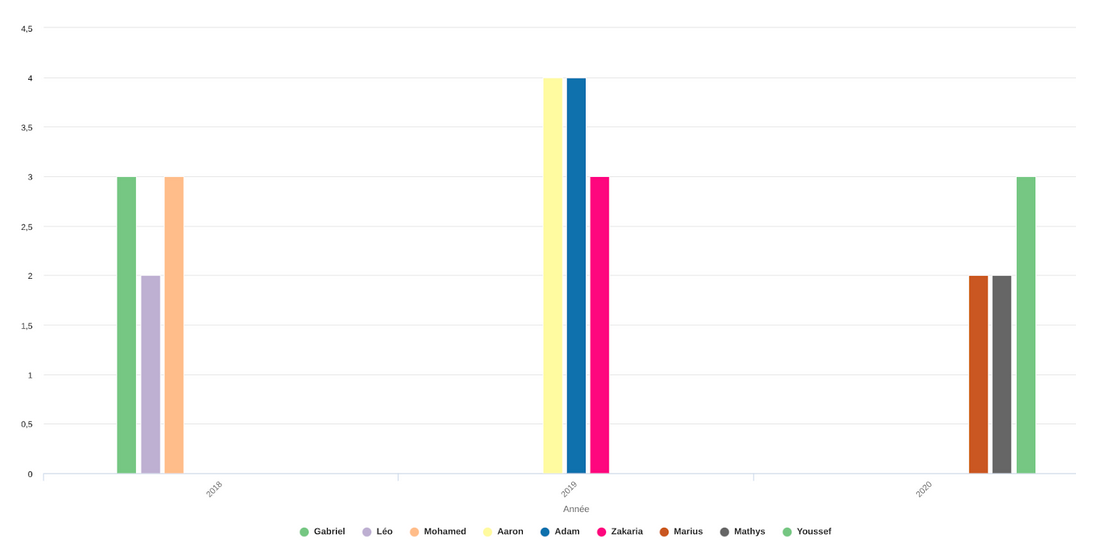
Diagramme en bâton des trois prénoms féminins les plus utilisés par année
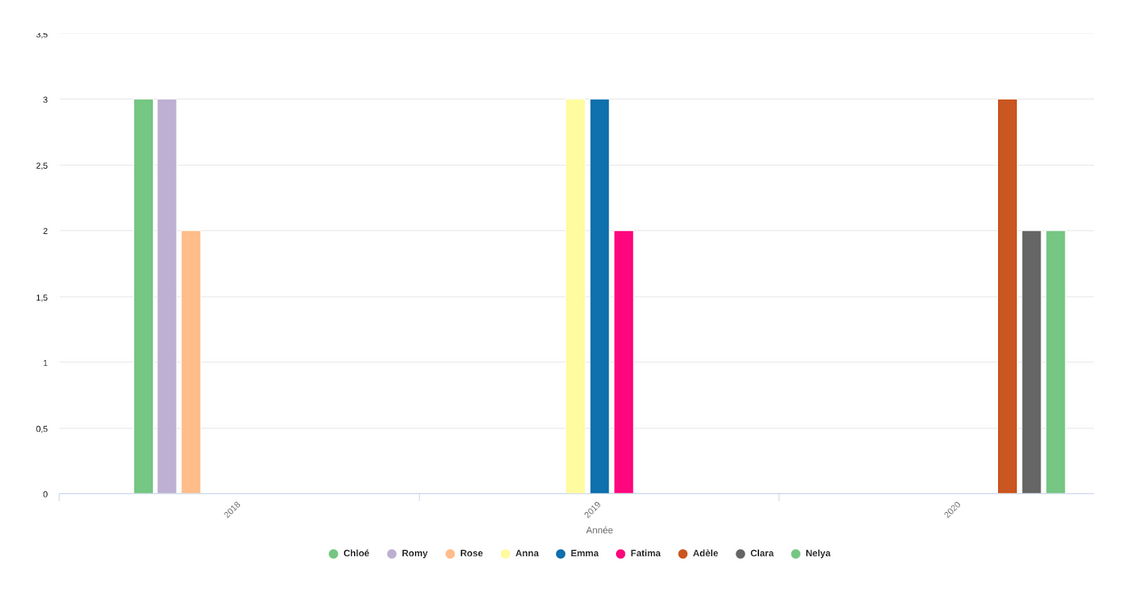
Difficultés:
Mis à part la difficile prise en main du logiciel, c’est le manque de diversité des modèles graphiques qui a limité le choix et la possibilité de création de graphiques originaux.
- Clothilde et Marie (c’est-à-dire moi ^^): Les délibérations
Nous pensions avoir fait une bonne affaire avec Clothilde sur ce jeu de données… mais nous avons vite compris que ça allait être plus difficile que prévu.
Tout d’abord il a fallu se mettre d’accord sur ce que nous voulions démontrer. Nous étions partie sur un diagramme circulaire nous permettant de distinguer les matières les plus abordées par la ville entre 2003 et 2020. Puis nous voulions réduire le champ des variables aux seules matières les plus abordées afin de les comparer, cette fois-ci, en fonction des années.
En quête de notre diagramme circulaire nous avons cherché sur opendatasoft et sur Rawgraphs puis nous avons été confrontées à notre premier problème: nous n’avions pas mis les occurrences sur le tableau workbench. Ainsi ne ne pouvions pas faire de graphique puisque chacune de nos variables (= les matières des délibérations) étaient comptées sans qu’il y ait de regroupement en fonction des occurrences.
Ainsi nous avons importé le template sur excel où nous avons rajouté une colonne “occurrence”. Nous avons ré-importé le tout sur workbench. Sur les conseils d’Arthur nous sommes finalement restées sur workbench pour réaliser notre graphique: nous avons donc adapté notre stratégie et abandonné le diagramme circulaire.
Nous avons donc représenté le nombre d’occurrence des sujets abordés en délibérations entre 2003 et 2020.
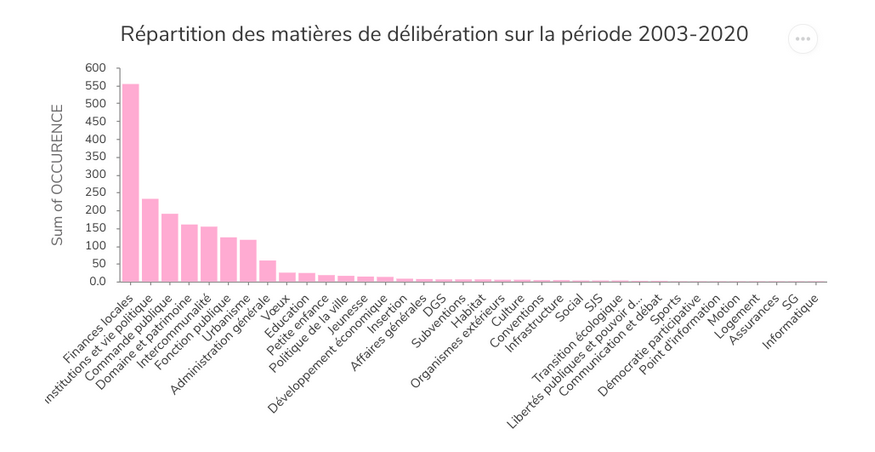
Histogramme des matières les plus examinées entre 2003 et 2020
Nous avons ensuite décidé de ne retenir que les matières dont les occurrences dépassaient les 100:
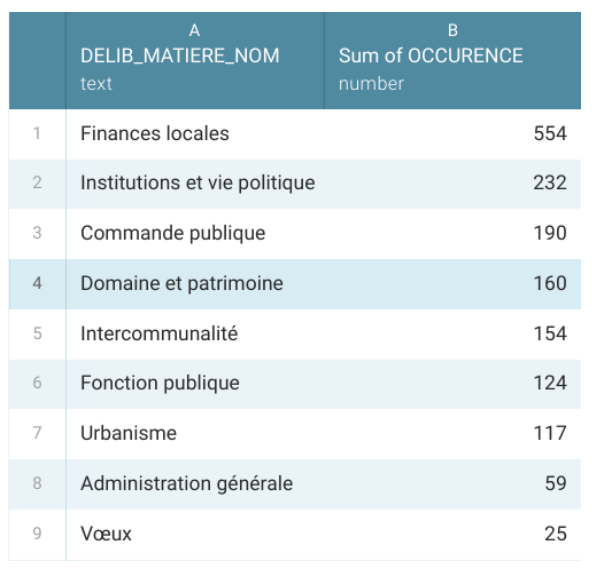
Nous avons donc sélectionné 7 matières (finances locales, institutions et vie politique, commande publique, domaine et patrimoine, intercommunalité, fonction publique et urbanisme).
Nous voulions comparer ces matières selon leur importance chaque année. De plus, ce choix était nécessaire afin d’obtenir un graphique lisible et efficace (la multitude des matières aurait rendu notre graphique incompréhensible). Cependant (et cela a été notre plus gros casse-tête d’ailleurs !) nous n’avons pas réussi à importer nos 7 matières, leur occurrence et toutes les années dans Rawgraphs pour obtenir ce que nous voulions. Cela a été très difficile et très long, nous avons été aidées par Alix et conseillées par Arthur. Finalement nous avons réussi à restructurer nos données sur workbench pour qu’elles puissent s’adapter au logiciel Rawgraphs.
Enfin notre dernier problème a été de trouver un modèle graphique compréhensible et lisible, néanmoins, comme je l’ai déjà précisé plus haut, le nombre de modèles étant réduit, nous avons dû faire un choix par défaut.
Notre graphique représente donc les matières les plus importantes selon les années. Sa complexité, nécessitant une lecture attentive, ne le rend pas moins intéressant: il nous permet d’analyser la proportion de chaque matière selon les années mais également de les comparer sur un temps plus long. Nous pouvons également remarquer l’apparition de la couleur bleue (institutions et vie politique) en 2012 ce qui induit l’hypothèse selon laquelle cette matière n’était pas enregistrée avant cette date.
Graphique sur l’évolution des 7 matières les plus examinées selon les années
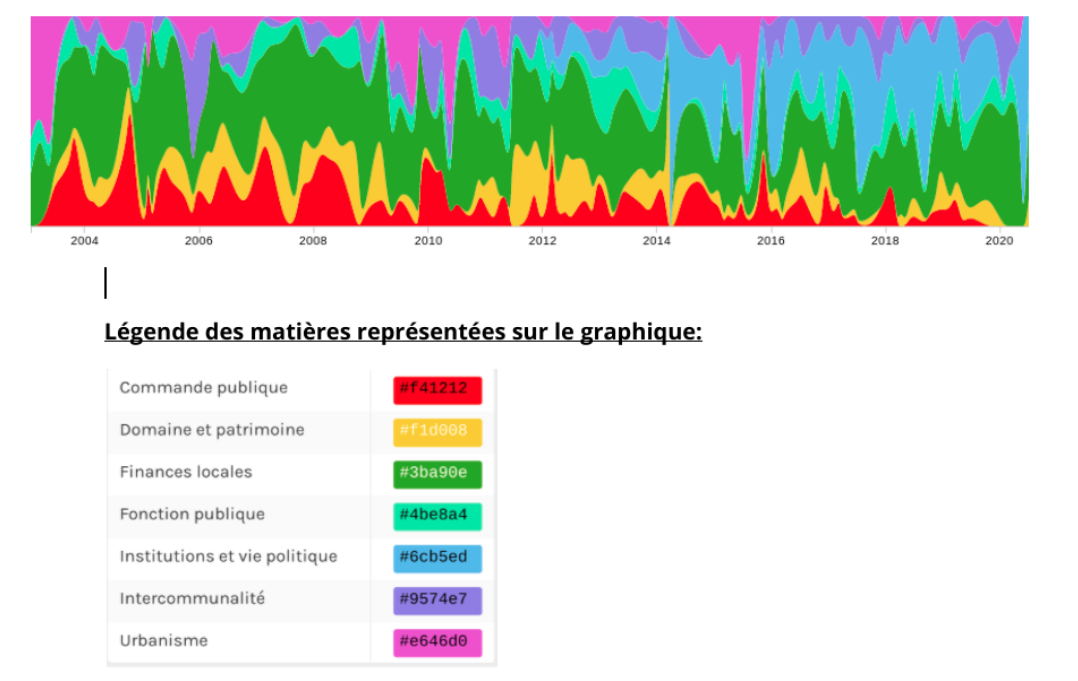
Une fois nos graphiques terminés, nous avons fait une pause déjeuner. Puis nous avons tous rédigé les fiches explicatives liées à nos graphiques.
Ensuite, il nous restait du temps avant la remise de 17h, nous avons donc décidé de revenir sur notre mindmap et sur notre stratégie de communication afin de les rendre plus attractives (images, couleurs etc.).
Emma s’est chargé de la stratégie communication avec de très jolis visuels. Elle a également ajouté une photo d’une simulation de sondage qu’elle avait créé afin d’illustrer
une de nos propositions pour faire participer les citoyens à de nouvelles ouvertures de jeux de données. Ces images leur donneront des idées pour leur communication (nous l’espérons en tout cas).
De leur côté, Alix et Daniel ont amélioré notre mindmap: couleurs pour les données ouvertes et gris pour les données que nous n’avons pas pu ouvrir (par absence de données).
Les éléments en gris concernent les données non reçues ou non exploitées après décision du groupe.
Plus le temps passait, plus nous nous rapprochions du rendu. L’atmosphère était mêlée de stress, d’excitation et de nostalgie pour cette dernière soirée ensemble.
Alix s’est chargé d’insérer les liens URL de nos graphiques sur data.gouv. Petit stress de mon côté: je n’ai pas réussi à récupérer l’URL de notre graphique sur Rawgraphs !! J’ai contacté Julia qui m’a indiqué que le site ne fonctionnait plus, le plus simple était de télécharger le graphique sous forme de photographie et de l’insérer sur la fiche explicative de google doc. J’ai donc créé un google doc unique sur lequel j’ai copié collé notre fiche explicative ainsi que le graphique et j’ai partagé le lien en lecture seule à Alix qui l’a uploadé sur data.gouv.
De la même manière, Emma et Arthur avaient des difficultés à rendre accessibles leurs liens URL (opendatasoft), lesquels restaient en mode privé. Arthur de Datactivist est alors intervenu et les a guidé pour pallier ce problème.
17h pile: FINI !!! Nous avons réussi à tout insérer sur data.gouv. Je dois avouer que personnellement j’étais fière de ce que nous avions accompli et de tout ce que nous avions appris.
Nous avions invité par mail notre référent 1 à la réunion afin qu’il puisse assister à notre présentation. Après le joli discours de Julia, nous sommes allés dans la salle de présentation et nous y avons retrouvé notre référent. Il était content de notre travail, il nous a dit que le service communication aurait souhaité nous associer dans le long terme avec nos propositions et qu’ils auraient été heureux de nous remercier en personne.
C’était une très belle aventure (et pas seulement dans le domaine de la data que personnellement je ne connaissais pas !), une aventure humaine. Nos encadrants, Julia, Arthur, Magalie ont toujours été à notre écoute avec grande bienveillance. Nos interlocuteurs au Pré Saint-Gervais ont été très présents et réactifs à nos demandes. Nous avons particulièrement apprécié notre référent 1 qui a tout fait pour être disponible dès que nous en avions besoin. Et enfin, un grand merci à Allyson qui nous a partagé sa bonne humeur, ses petits tips pour danser sur gather et son rire communicatif.
Un grand merci à tous !!
CONCLUSION
Le bilan de la commune
● 18h. Vendredi 19 février. Vient l’heure du bilan. Pour la commune, et comme nous l’a confirmé notre référent 1, celui-ci s’avère extrêmement positif. La collectivité était désireuse de s’essayer à l’ouverture des données et le Challenge Data lui a permis de mettre un pied dans l’open data – il est certain que les efforts fournis cette semaine ne s’arrêteront pas. En effet, trois jeux de données ont été ouverts et publiés sur data.gouv.fr : les délibérations, les prénoms et les actes civils.
-
Si les données liées aux prénoms pourraient sembler anecdotiques, elles sont en réalité nécessaires du point de vue de la communication. Pour le service de communication, il s’agit d’une bonne manière d’inviter les habitants du Pré Saint-Gervais à s’intéresser aux données qui ont été ouvertes.
-
De la même manière, les données liées aux actes civils sont importantes pour faire une « photographie » de la commune et raconter son histoire.
-
Mais les données les plus intéressantes restent celles des délibérations. Avoir publié ces données est un grand bond au niveau de la transparence du Pré Saint-Gervais et au niveau de l’implication des citoyens dans la vie politique de la commune.
Outre l’intérêt que représente l’ouverture de ces données en elles-mêmes, il convient de noter que le Challenge Data aura permis au Pré Saint-Gervais d’obtenir un compte certifié sur le site data.gouv.fr, élément essentiel à l’ouverture des données, et aura permis à la commune d’avoir une idée des exploitations potentielles qui pourront être faites à partir de ces data. En effet, notre groupe s’est attaché à produire des exemples de datavisualisations qui pourront être réutilisées et complétées dans le futur. Remarquons également que la création d’un plan de communication fût une manière de donner des pistes et des stratégies à la commune du Pré Saint-Gervais pour faire la promotion des données qui ont été ouvertes et de celles qui le seront dans le futur – pensons, par exemple, à l’utilisation de YouTube pour faire des vidéos de présentation.
● Par ailleurs, l’intérêt du Challenge Data, pour le Pré Saint-Gervais, se trouve au niveau des éléments qui peuvent être améliorés pour l’ouverture de futures données et qui, pour nous, ont constitué un frein. Tout d’abord, la commune ne dispose pas d’un service municipal spécialisé dans l’ouverture des données et peu d’agents sont formés à cette question. Aussi nos référents 1 et 2 nous ont-ils confié être des autodidactes. Ensuite, les données actuellement détenues par la commune sont compliquées à utiliser (données manquantes ; formats différents ; standardisation inexistante pour certains jeux de données). Par exemple, bien qu’il nous ait été possible d’ouvrir les données liées aux délibérations, il manquait des informations sur la répartition des votes. Enfin, les données sont réparties entre plusieurs services municipaux : peut-être serait-il pertinent de les regrouper au sein d’un même service.
Néanmoins, il serait périlleux de penser qu’il n’existe pas de leviers à l’ouverture des données au Pré Saint-Gervais – notre groupe n’a eu de cesse de le remarquer. Premièrement, les agents de la commune sont motivés et ont pleinement conscience des intérêts liés à l’ouverture des données. Pour eux, cela constitue une véritable exigence et, si cela a facilité notre travail, il s’agit surtout d’une preuve du fait que l’ouverture des données du Pré Saint-Gervais a de beaux jours devant elles. Par exemple, dès notre première entrevue, notre référent 1 nous a confié que l’open data faisait partie des priorités de la municipalité et qu’ils s’étaient fixés l’objectif d’ouvrir leurs données avant la fin du mandat. Ensuite, nos interlocuteurs du Pré Saint-Gervais sont réactifs et cela ne fait aucun doute qu’ils mettront tout en œuvre pour aider leurs futurs prestataires ou agents sur la question de l’open data. Par exemple, nos appels comme nos courriels recevaient toujours une réponse rapide et des réunions étaient fixées avec facilité. Enfin, les données actuellement détenues par la commune, même si elles sont compliquées à utiliser pour des novices comme nous, demeurent largement exploitables par des experts.
● Pour conclure sur le bilan de la commune, notons simplement que le petit pas qu’est le Challenge Data sera bientôt un grand bond dans l’open data – surtout quand on connaît l’ampleur des leviers à l’ouverture des données au Pré Saint-Gervais. Nul doute que des dizaines de jeux de données rejoindront bientôt les 3 que nous avons publiés.
Le bilan de notre groupe
● Penchons-nous, maintenant, sur le bilan de notre groupe. En tant qu’étudiants en sciences politiques, et quelle que soit notre spécialité, la semaine a été riche en enseignements. Tout d’abord, et c’est l’un des points les plus évidents, nous avons appris à organiser notre travail, à travailler en équipe et à nous répartir les tâches pour être les plus efficaces possible. Par exemple, lors de nos sessions de travail, nous n’hésitions pas à nous faire confiance et à faire des petits-groupes (de 2 ou 3 personnes) pour effectuer le travail demandé. Notamment, pour le nettoyage de nos data comme pour leur exploitation à travers des datavisualisations, nous avons constitué des groupes de 2 pour chaque jeu de données. De même, lorsqu’il s’agissait d’obtenir des renseignements auprès de nos interlocuteurs ou lorsqu’il fallait leur faire un retour en réunion, chacun avait un rôle précis à jouer. Ensuite, le Challenge Data fut une véritable initiation au traitement des données. Nous avons appris à utiliser des logiciels que nous ne connaissions pas, à nous saisir d’un langage nouveau (et qui, au premier abord, semblait difficilement compréhensible) et à comprendre le processus complexe que constituait l’ouverture des données (diagnostic ; identification ; mise en qualité ; publication ; valorisation). Par exemple, je me rappelle très bien de notre incompréhension lorsque nous avons découvert Workbench. Pourtant, ce logiciel nous est rapidement paru familier et nous savons désormais utiliser ses fonctionnalités au mieux. De plus, autre enseignement de cette semaine intense, nous nous sommes saisis des codes du service public et de la manière dont il fallait procéder pour aider une collectivité locale - et, par-là, contribuer à l’action publique. En effet, nous avons appris à entrer en contact avec une collectivité, à nous adresser aux agents de celle-ci comme à ses différents services et à intégrer son esprit, sa vision des choses. Par exemple, bien que notre référent 1 ait été notre principal interlocuteur, nous avons également dû passer par d’autres agents pour mener à bien l’objectif d’ouverture des données. Enfin, et c’est peut-être l’enseignement le plus important tant il regroupe tous les autres, nous avons connu une véritable immersion dans le monde du travail : journées intenses, tâches précises, exigences à satisfaire, etc. C’est d’autant plus intéressant que, lors de cette immersion, nous avons également appris à demander de l’aide quand nous en avions besoin et à privilégier la qualité à la quantité. En somme, le Challenge Data fut une semaine d’apprentissage et nul doute que nous en ressortons grandis.
● A cet égard, nous en ressortons d’autant plus grandis que le Challenge Data n’a pas été seulement riche en enseignements : il nous a apporté plein de choses. Premièrement, avoir participé au Challenge Data est synonyme de satisfaction d’avoir servi l’intérêt général. Quoi de plus valorisant qu’un travail effectué pour le bien du plus grand nombre et dans l’intérêt des citoyens ? En effet, savoir que notre travail et les jeux de données publiés pourront être consultés par les habitants du Pré Saint-Gervais et utilisés par la commune est satisfaisant. Par exemple, nous avons l’impression que nos 3 jeux de données sont un véritable coup de pouce pour la collectivité dans sa quête de transparence et qu’elle va tout faire pour les compléter. Deuxièmement, le Challenge Data aura apporté, entre mes camarades et moi, une excellente entente mêlée à un travail d’équipe des plus efficaces. Rien de plus agréable que de travailler dans de bonnes conditions, avec des personnes qui se font confiance mutuellement et, surtout, dans la bonne humeur. Je ne compte plus nos rires partagés et nos danses endiablées avec Allyson. Troisièmement, et dernièrement, le Challenge Data nous aura apporté la satisfaction d’avoir répondu aux exigences des experts et de nos interlocuteurs de la commune (du moins, nous l’espérons). Par exemple, ce fut un réel plaisir de voir qu’Allyson nous félicitait pour notre travail et que notre référent 1 nous remerciait d’avoir aidé la commune du Pré Saint-Gervais. Une chose est certaine : nous n’oublierons pas le Challenge Data.
● Pour conclure sur le bilan de notre groupe, le Challenge Data était une expérience des plus intéressantes, tant du point de vue des enseignements que de la satisfaction que nous en retirons.
Nous espérons sincèrement que notre travail aura répondu aux exigences des experts de Datactivist comme du Pré Saint-Gervais.
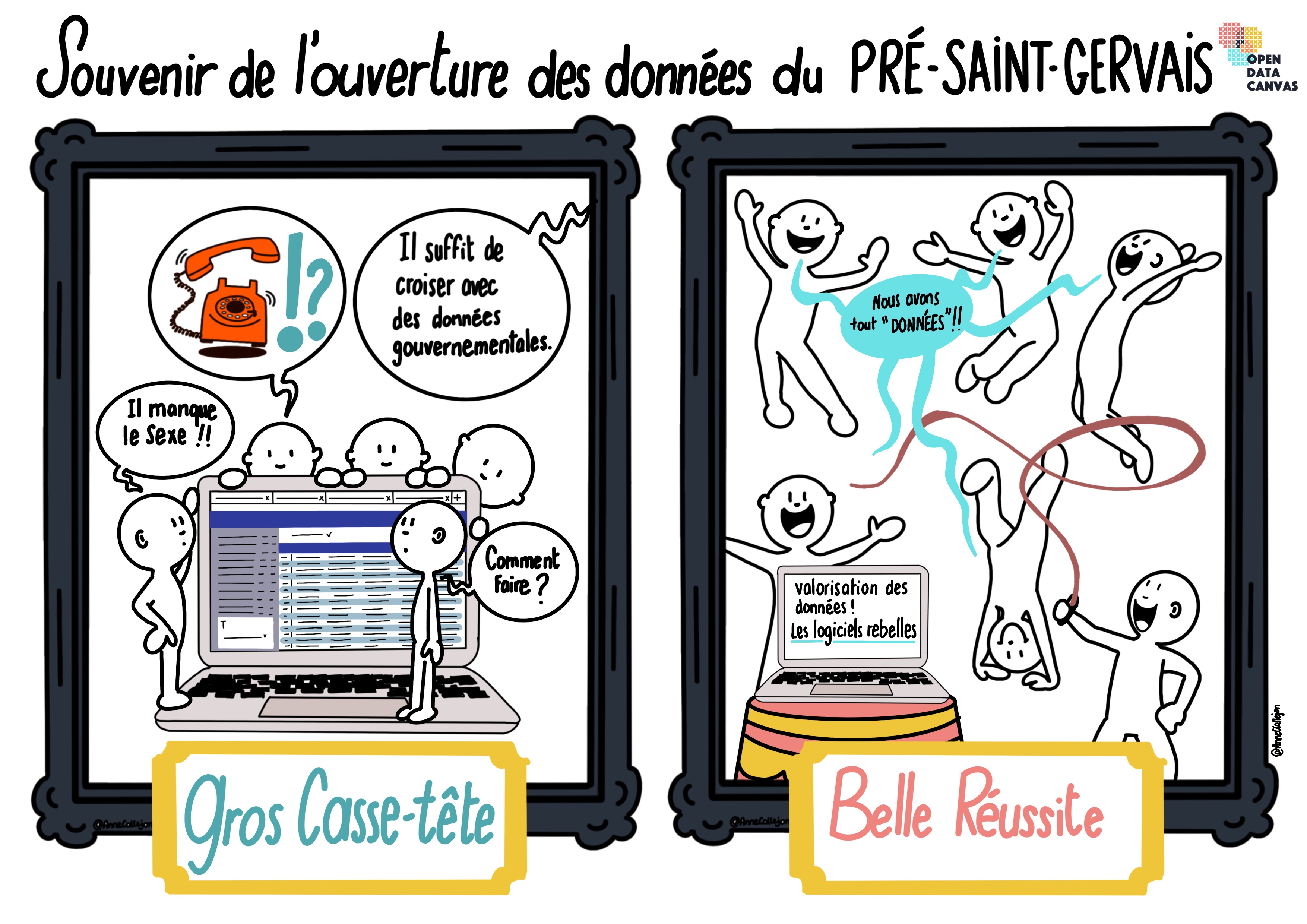
Notre plus gros casse-tête
● L’une des raisons pour lesquelles nous n’oublierons pas le Challenge Data est liée à notre plus gros casse-tête. Si chaque jour connaissait son lot de difficultés, notre difficulté majeure est apparue lors du troisième jour : le jour de la mise en qualité des données. Alors que nous avions choisi d’ouvrir le jeu de données contenant les prénoms des enfants nés au Pré Saint-Gervais entre 2018 et 2020, une donnée essentielle manquait : le sexe des enfants à qui ces prénoms étaient attribués. Or, nous pensions pouvoir récupérer cette donnée facilement. Il suffisait simplement de revenir auprès du service qui nous avait fourni les données sur les prénoms lors du deuxième jour (celui de l’identification), c’est-à-dire le service des affaires générales. Pas de chance, la personne en charge de ce service était en vacances depuis la veille au soir. Comment faire ? Nous ne pouvions décemment pas abandonner, cela aurait nui à la qualité de notre travail et cela n’aurait pas été conforme à l’esprit de notre groupe. La première solution fut de contacter l’un de nos interlocuteurs au Pré Saint-Gervais, notre référent 2, pour lui demander s’il pouvait avoir accès à ces données. Celui-ci, très réactif au demeurant, nous a expliqué qu’il n’avait pas accès au même logiciel d’extraction que son collègue et qu’il allait faire de son mieux. Quelques heures plus tard, notre référent 2 nous a envoyé les données sur le sexe des enfants. Victoire ! Il ne nous restait plus qu’à les joindre à notre jeu de données sur Workbench. Mais notre joie fut de courte durée : les prénoms ne correspondaient pas avec ceux que le service des affaires générales nous avait envoyés la veille. Les données étaient inutilisables. Retour à la case départ. Cependant, encore une fois, l’abandon n’était pas une option. Dès lors, quelle solution adopter ? Après avoir mûrement réfléchi, nous avons décidé d’essayer de remplir le sexe des enfants à qui les prénoms étaient attribués à la main, sur Excel. Il s’agissait de la fausse bonne idée par excellence. D’une part, il y avait presque 700 prénoms : même en s’y mettant à plusieurs, nous nous sommes rapidement rendus compte du fait que ça allait prendre des heures. D’autre part, il était difficile de déterminer le sexe de certains prénoms : Camille est-il un prénom masculin ou féminin ? Et Charlie ? Les difficultés s’ajoutant les unes aux autres, le temps pressant, nous avons décidé, largement à contre-cœur, d’abandonner. Après tout, ce n’était pas de la mauvaise volonté, c’était juste mission impossible et les experts de Datactivist nous l’ont confirmé. Ainsi, c’est contrariés que nous avons terminé notre troisième jour de Challenge Data – ce casse-tête ayant véritablement occupé nos esprits la journée durant.
Comme un miracle, la solution est apparue le lendemain. Alors que nous discutions avec notre coach Allyson, celui-ci nous dit qu’un groupe, le groupe n°13, avait rencontré le même problème avec le sexe des enfants à qui les prénoms étaient attribués. Or, ils avaient trouvé une solution ! Allyson nous dit de les contacter. Nous nous empressons de le faire et, Paul-Alexis, membre de ce groupe, nous vient rapidement en aide. Sur Gather, il s’assoit à notre table et me demande de lui partager mon écran pour qu’il m’indique la manipulation à effectuer. La manipulation en question consistait à utiliser une base de données gouvernementale, avec le sexe des prénoms, et à la mettre sur Excel pour compléter automatiquement le sexe des prénoms attribués aux enfants du Pré Saint-Gervais. L’opération fut un succès : nous avions, enfin, la donnée qui nous manquait !
En somme, notre plus grand casse-tête montre qu’aucun casse-tête n’est insoluble et que l’aide d’autrui peut permettre de venir à bout des pires difficultés. Même lorsque la solution semble inexistante.
Notre plus grande réussite
● L’une des autres raisons pour lesquelles nous n’oublierons pas le Challenge Data est liée à notre plus grande réussite. Si chaque jour connaissait son lot de victoires, notre plus grande réussite est apparue lors du cinquième et dernier jour : le jour de la valorisation des données. Alors que nous venions de réfléchir à quelles datavisualisations effectuer pour mettre en valeur les données publiées, nous nous sommes rapidement rendus compte de la difficulté que représentait la prise en main de logiciels comme Open Data Soft. Pourtant, avec sa bonne humeur habituelle, notre petit groupe n’a pas abandonné. Au contraire, par groupes de 2, nous avons essayé de comprendre comment fonctionnait Open Data Soft et comment faire un histogramme, un camembert ou autre datavisualisation. Finalement, après maintes et maintes manipulations, nous sommes parvenus à obtenir des datavisualisations convenables et, lorsqu’un membre du groupe était dans la panade, nous n’hésitions pas à lui venir en aide. Par exemple, je revois très bien nos difficultés pour exploiter les données liées aux délibérations du Pré Saint-Gervais : il a fallu faire de nombreuses manipulations sur Workbench (inverser les lignes et les colonnes, supprimer les catégories non-nécessaires pour la datavisualisation, etc.), essayer plusieurs datavisualisations avant de trouver la bonne et, une fois la bonne datavisualisation _trouvée, parvenir à l’expliquer. De la même manière, pour les _datavisualisations sur les prénoms, il fut difficile de savoir ce qu’il était intéressant de représenter et, surtout, comment le faire : contrairement à ce que l’on pourrait penser, il n’est pas si simple de déterminer les prénoms les plus donnés chaque année et de le montrer avec un visuel ! Malgré tout, nous y sommes parvenus et, pour des novices comme nous, ce fut une réelle réussite que de voir que nous arrivions à utiliser des logiciels inconnus et ce en autonomie. La réussite fut d’autant plus grande que, lors de la présentation de fin de journée, à 17h15, notre référent 1 a apprécié ces datavisualisations.
Outre cette réussite, à savoir le fait que nous avons réussi à apprivoiser des logiciels pourtant rebutants au premier abord, la plus grande réussite est peut-être la bonne ambiance de notre groupe. Nous nous retrouvions chaque jour dans le même appartement pour travailler ensemble et les rires se mêlaient aux données. Nul doute que nous n’oublierons pas le Challenge Data, les thés partagés, les gaufres pour reprendre des forces, les danses avec Allyson sur Gather, les prises de tête avec les données, la joie d’accomplir le travail demandé…
Derniers mots…
C’est non sans nostalgie que nous mettons un terme à ce carnet de bord et au Challenge Data. L’expérience fut riche et intense. Une chose est certaine : nous avons tout « données » !