Carnet de bord de l’ouverture des données de Neuville-saint-Remy
par Clémence F., Yannis Foulquier, Jérémy Grunner, Paul-Alexis Reynaud et Manon Cabanes

JOUR 1 – DIAGNOSTIC
Nous avons pris connaissance de Gather, lundi 15 février 2021 à 9 heures. Gather est un logiciel permettant des réunions, comme son nom l’indique, sous forme de jeu vidéo semblable dans les graphismes à Pokemon. Il permet de se réunir de façon ludique et pratique.
L’équipe de Datactivist nous a bien accueillis et nous a expliqué le projet de la semaine. Il y avait beaucoup d’informations à intégrer ce qui n’était vraiment pas simple. Nous nous sommes réunis sur Zoom avec l’ensemble de la promotion ainsi que l’équipe organisatrice du challenge et, durant une heure, on nous a expliqué plus en détail les principes et l’organisation de la semaine.
De plus, Datactivist avait mis à notre disposition un site internet et des ressources nous permettant de mieux comprendre le challenge. Dans ce site internet étaient indiquées les étapes à suivre chaque jour de la semaine. Le premier jour était fractionné en 3 parties : la récolte d’informations, le filtrage puis la rédaction d’une wishlist et des vidéos tutoriels ont été mis en place par l’organisation pour nous guider ce qui nous a été d’une grande utilité pour prioriser nos tâches et nous organiser alors même que nous étions submergés par la quantité d’informations à découvrir. De plus, nous avons dû découvrir aussi les ressources clés dont nous avions besoin.
Dans un deuxième temps nous nous sommes réunis par groupe. Notre groupe est composé de Manon, Jeremy, Clémence, Yannis et Paul-Alexis. Nous avons appris que nous allions nous concentrer sur la commune de Neuville Saint Rémy. C’est une commune de 3833 habitants. L’équipe administrative comprend 52 agents municipaux dont 9 agents administratifs. Nous avons donc dû chercher des informations sur cette ville du nord, des informations se rapportant à leur digitalisation, sur la façon dont le passage des informations se fait vers leurs administrés, les différents services etc..
Nous avons pu découvrir sur la table de Gather les coordonnées de notre future interlocutrice. Le premier contact avec la mairie fut téléphonique et nous avons pu établir un premier lien avec la direction générale des services. Nous avons ensuite programmé un rendez-vous sur Gather avec nos interlocuteurs pour 14 heures.
A 13 heures 50 notre interlocutrice a téléphoné à Jeremy pour tenter de nous rejoindre sur Gather. Après quelques minutes d’explications, nous nous sommes retrouvés autour d’une table virtuelle où nous avons pu évoquer plusieurs sujets importants.
Monsieur Dumont, Le Maire, était aussi présent au début et nous a gentiment accordé du temps malgré un emploi du temps chargé. C’est un homme fort sympathique et abordable, qui a un grand sens de l’humour et qui a répondu de façon simple et efficace.
Nous les avons d’abord questionnés sur l’idée qu’ils se faisaient des données et essayé de dissiper le flou qui existait dans leur esprit entre les notions d’informations et de données. Ceci nous a donné l’occasion de rendre ces définitions plus claires également pour nous : en effet, ces deux notions sont proches et difficiles à définir séparément. Monsieur le maire et un membre de l’administration nous ont posé de nombreuses questions car la notion de données ne leur était pas familière.
On nous a ainsi confirmé qu’aucun agent administratif n’était chargé de la gestion des données, même si l’un des agents était chargé de la politique RGPD (ce qui n’était pas vraiment en lien avec ce que nous recherchions), ce que nous avions déjà présagé. En effet, nous pensions que Neuville Saint Rémy, de par sa taille, n’avait peut-être pas eu les moyens, dans le passé, de s’investir dans l’ouverture des données même si nous avons été surpris par leur site internet et leur application mobile très modernes.
L’un des freins principaux à l’ouverture des données pour l’équipe interlocutrice était le manque d’information sur le sujet des données. Nous avons donc pu les informer sur le cadre légal et les enjeux que représentent l’ouverture des données pour la transparence et la facilitation du passage de l’information.
Nous nous sommes rendus compte que la mairie n’avait pas entrepris de politique d’ouverture de leur données et que cela rendrait notre tâche plus compliquée mais aussi plus intéressante.
Puis vînt l’heure de choisir les domaines et les sujets qui intéressaient les membres de l’administration pour ces ouvertures de données. Très vite, un premier obstacle est apparu sur la question des subventions: un membre était hésitant à les dévoiler pour éviter toute tension. Nous comprenions évidemment qu’ils veuillent éviter les soupçons de favoritisme et “la foire d’empoigne”. Finalement, après plusieurs minutes d’échanges et compte tenu du fait que ces choix seraient retranscrits dans les délibérations du conseil municipal, nous avons pu obtenir leur accord.
La volonté de la municipalité étant de mettre l’enfance au cœur de la politique de la commune, les membres administratifs désiraient que les données concernant ce sujet occupent une place importante dans la communication de celles-ci.
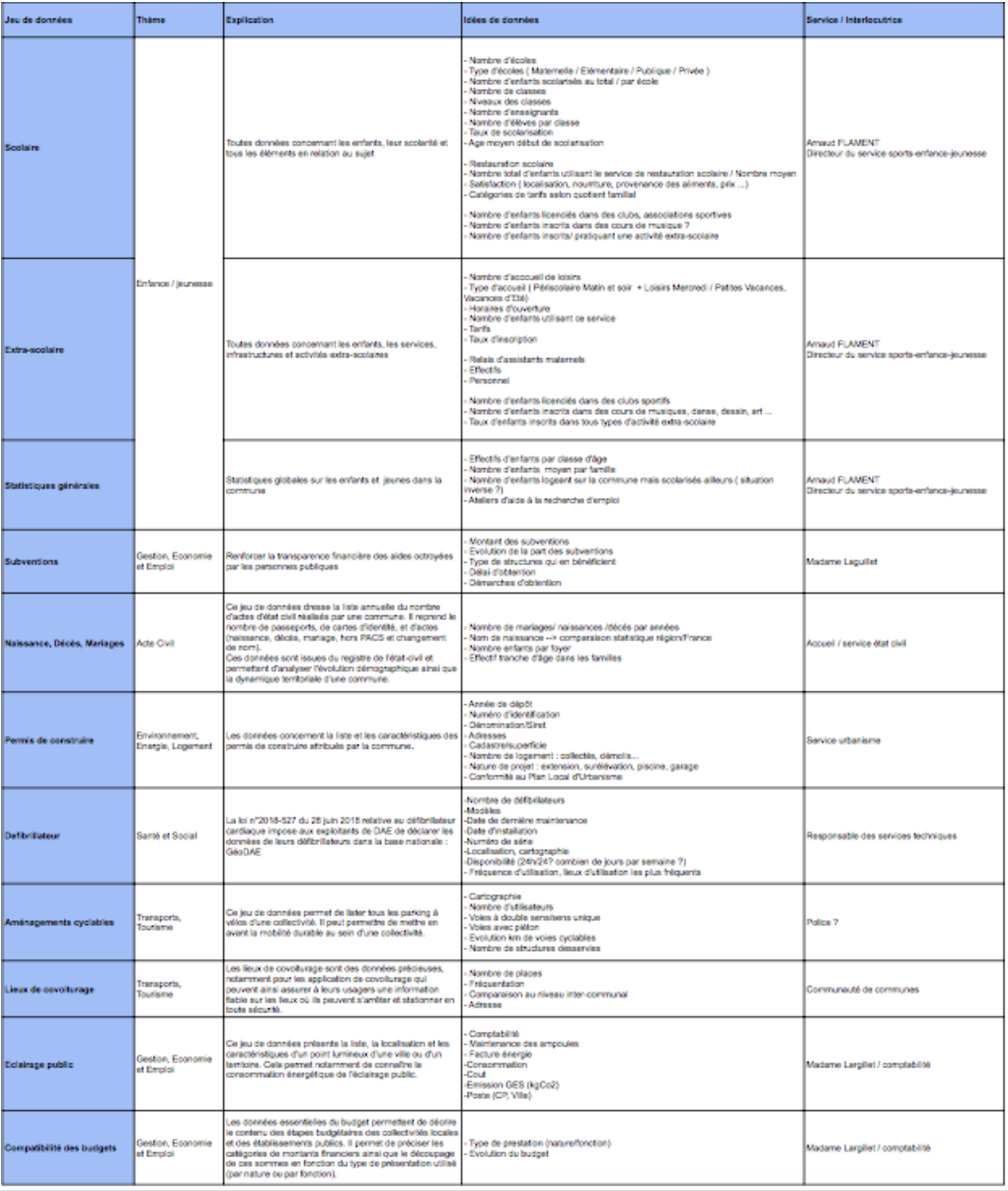
Nous nous sommes finalement mis d’accord sur 10 thèmes allant de l’enfance aux lieux de covoiturage et nous devions après l’entretien leur faire parvenir une courte wishlist par ordre d’importance suite à cette réunion : Enfance jeunesse coupées en deux ou trois jeux de données, l’éclairage, les naissances, les défibrillateurs, les subventions, les délibérations, les aménagements cyclables, l’aire de covoiturage ainsi que les permis de construire. Dans cette wishlist, nous avons recherché et noté les contacts et les services concernés afin de faciliter notre tâche future. Cependant nous voulions rendre leur tâche moins compliquée et nous avons donc décidé de leur transmettre une wishlist plus complète, que vous pouvez trouver ci-dessous. Cette wishlist comprend en effet ce que nous avons mentionné ci dessus mais aussi des explications qui nous avaient été fournies dans les ressources clés ainsi que le thème.
Lien de la wishlist simple :
https://docs.google.com/document/d/10ub4t6uu5WTH9JgVx6R7xfeN3-Xe-rca/edit
Julia a joué un rôle primordial d’interlocutrice et nous a accompagnés tout au long de notre entretien. Cela nous a énormément aidés puisqu’elle nous a éclairé sur ces sujets mais elle a aussi su faire le lien entre notre équipe et les membres de l’administration.
Wishlist transmise à l’équipe :
Les apprentissages du jour ont été les suivants :
- La gestion et la priorisation d’un grand nombre d’informations
- La gestion du temps
- L’organisation et la répartition des tâches
- La communication avec des intervenants extérieurs
- La prise en main de logiciels nouveaux et de ressources dont nous n’avions aucune connaissance
- Apprendre davantage sur les enjeux des données et leur importance
Cette première journée, primordiale pour la suite de notre travail s’est avérée être très ardue et intense mais très passionnante et riche en apprentissages. Nous nous rendons compte de ce qui nous attend et des difficultés que nous allons devoir surmonter et du challenge qui nous attend…
JOUR 2 – IDENTIFICATION
La journée d’hier, nous a été précieuse pour mettre un pied dans la compréhension de cette mission. Effectuer le diagnostic de notre commune nous a permis d’identifier les envies, besoins et les particularités de Neuville-Saint-Rémy. Cette phase fut très importante pour faire la transition avec l’étape « identification » des jeux de données.
Nous avons premièrement assisté au briefing de 9 heures à 9h45 par Julia, notre référente. Si nous avions déjà hier soir identifié les tâches de cette journée, nous n’avions pas conscience de la complexité à les réussir.
La première étape consistait effectivement à reprendre la wishlist que l’on a produite hier en accord avec les membres de l’administration. Nous avions déjà ciblé les acteurs et les services ayant les données que nous cherchions. Néanmoins, il serait honnête de décrire notre inquiétude et nos doutes sur cette récolte. Effectivement, la commune de Neuville-Saint-Rémy comporte 3800 habitants et la mairie n’est pas à la pointe de la technologie. Nous avions essayé de prendre la « tendance » hier pour connaître s’ils disposaient de données de ce type dans des fichiers Excel quand on mesurait le taux de maturité, néanmoins sur les 28 thèmes, une membre de l’administration pouvait nous assurer qu’il y avait qu’un seul tableau Excel à sa connaissance. Afin d’anticiper ce potentiel blocage, nous avons envoyé un long mail explicatif à notre interlocutrice. Dans ce mail, nous avons listé pour chaque service de la mairie les pièces nécessaires dont l’on va avoir besoin pour mener à bien la restitution du jeu de données. Ainsi, cette personne a pu transmettre ce document à l’ensemble des services de la mairie afin qu’ils soient au courant de notre appel d’aujourd’hui. Si cela a été une grande charge de travail hier, cela nous a fait gagner du temps aujourd’hui. Notre wishlist était déjà complète grâce à l’identification hier de données potentielles que nous nécessiterons pour effectuer ce travail. Nous avions déjà exploré une grande partie du champ des jeux de données de nos 10 thèmes choisis hier.
« L’avantage » que nous avions est qu’il y a très peu d’agents en Mairie : uniquement 9. Cela a diminué ainsi les potentiels interlocuteurs qui pouvaient détenir nos informations. Chaque agent a en effet un secteur de la mairie et ils ont donc chacun leur spécialisation.
Notre stratégie était donc de récupérer et demander le maximum de données à l’ensemble des services pertinents afin de pouvoir trier ces derniers.
Si nous avons gagné beaucoup de temps hier soir en prévenant les services concernés de notre appel, ce matin nous avons connu un blocage, car les agents de ces services n’étaient pas disponibles. Un des services n’était pas disponible de la journée, car le responsable était en déplacement et malgré un appel sur son téléphone portable professionnel nous n’avons pas obtenu de réponse. D’autres appels ont été plus concluants et se sont poursuivis avec des rendez-vous : un à 14h (Service animation : sports, écoles et jeunesse), un à 15h (Service accueil, états civils et élections) et le dernier à 17h qui était déjà fixé avec un membre de l’administration. Afin de clarifier avec eux notre demande, dès 11h30 on leur a adressé un mail pour leur expliquer les documents demandés et le format. Encore une fois, nous voulions leur faciliter la compréhension, car nous savions qu’un appel n’est pas évident pour comprendre notre démarche.
Si certains n’étaient pas disponibles, d’autres ne détenaient pas les informations et n’étaient pas au courant de notre action. Nous avons pu constater que dans ce cas-là qu’il était beaucoup plus compliqué d’obtenir des réponses. Notre interlocutrice nous avait par exemple renvoyés vers le service de police pour obtenir les données sur les aménagements cyclables. Bien que nous ayions trouvé ça étonnant, nous les avons appelés pour avoir confirmation. Comme nous nous y attendions, la police municipale n’a pas pu nous aider. Nous avons continué notre investigation en appelant la communauté d’agglomération de Cambrais. Notre interlocutrice nous avait fait comprendre qu’ils n’avaient pas les compétences pour les transports et notamment en ce qui se rapporte à l’aide de covoiturage. Malheureusement, la personne compétente à la communauté d’agglomération n’était pas disponible et nous lui avons écrit un mail encore sans réponse ce soir. Nous avons finalement essayé d’appeler le service urbanisme concernant les questions sur les permis de construire, mais il n’était pas disponible non plus. Nous n’avons pas relancé l’appel, car cette requête était en dernière position sur leur wishlist.
Finalement, notre blocage est également venu du fait que notre interlocutrice était en formation toute la journée. Elle nous avait dit qu’elle nous enverrait certains documents lundi soir, mais nous sommes sans nouvelles. Ces documents se rapportaient aux subventions, aux délibérations et à l’éclairage. Pour les délibérations, nous avons trouvé les comptes-rendus sur internet, néanmoins une donnée clé nous est manquante. Il s’agira donc demain de faire état de ce point et celui des subventions. Pour ce qui en est de l’éclairage, aucun service de la mairie n’a pu réellement nous faire avancer à ce projet.
En attendant les rendez-vous, nous avons profité de notre fin de matinée pour avancer sur les prochaines étapes.
Premièrement, dans le but de mieux identifier les besoins, nous avons créé comme demandé une banque de données avec les thèmes que nous pensions pouvoir traiter. Pour autant, il ne sera pas le cas de tous, une modification sera amenée à évoluer demain.
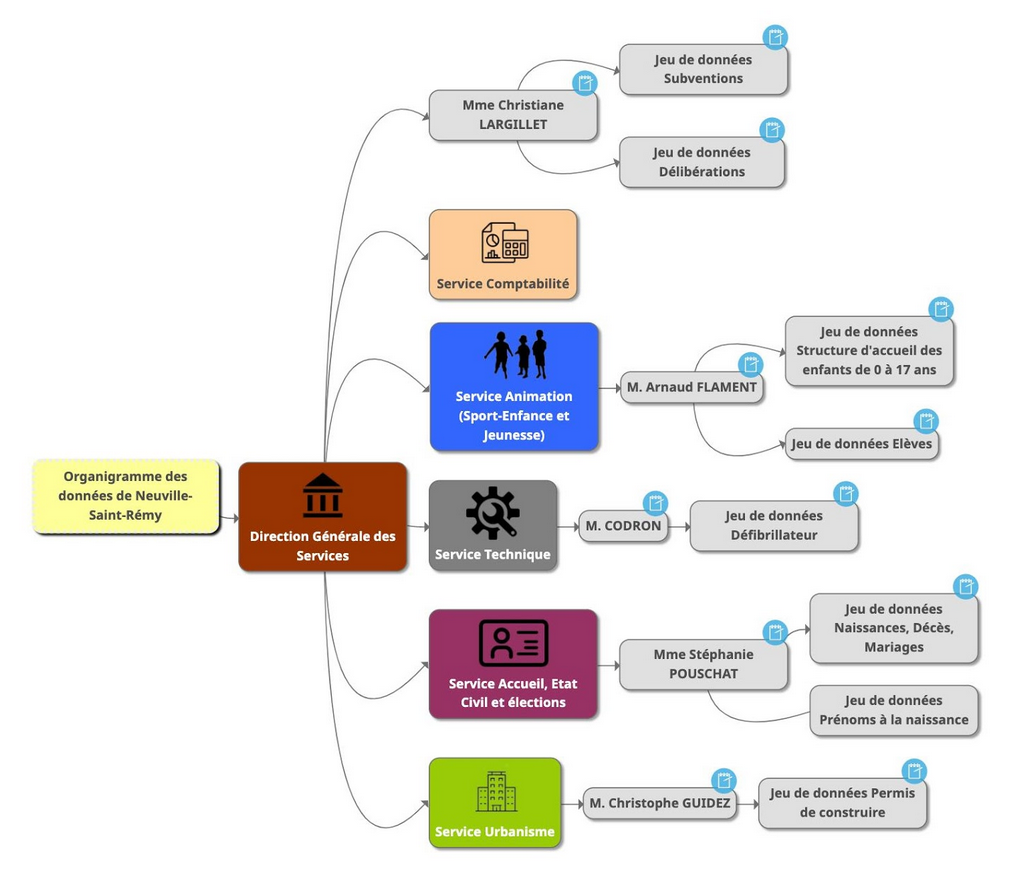
Puis, nous avons également commencé à produire notre organigramme. Avant d’utiliser l’outil Mindmup, nous l’avons premièrement fait sur un papier pour commencer notre réflexion. Ensuite, Jérémy l’a reproduit sur le format Mindmup. Il nous a expliqué toute la démarche et notamment les difficultés. Il a passé beaucoup de temps dessus et a été obligé de regarder plusieurs fois la vidéo YouTube pour les détails techniques (insertion des cases, déplacement, lien…). Par la suite, ayant pris l’outil en main, il s’est amusé à l’enjoliver de couleurs et d’icônes. Cette division du travail nous a permis d’avancer avec l’autre partie de l’équipe sur les rendez-vous téléphoniques des autres services.
Le premier rendez-vous a été réalisé avec un membre du service animation qui prend en compte le sport, l’enfance et la jeunesse. Ce rendez-vous était très important, car M. Le Maire nous avait confié la veille que c’était les données dont ils avaient le plus besoin. Nous avions ainsi énormément travaillé dessus et nous étions prêts pour le rendez-vous. Il a tout de suite compris notre démarche grâce aux deux mails envoyés avant cet appel. Il a de même l’habitude de travailler sur des tableaux Excel, car il doit fréquemment en envoyer à la CAF. Il était donc ravi de nous aider dans nos démarches et s’est empressé par la suite de nous envoyer les données demandées par mail. Également, il a apprécié que l’on effectue cette réunion sur Gather qui l’a rendu beaucoup plus dynamique.
Par la suite, nous avons appelé à 15h une personne gestionnaire de l’accueil, des états civils et des élections. Cet appel était également très important, car nous avions deux jeux de données à lui demander : un recensement des décès et mariages et un autre sur les prénoms des nouveau-nés. Tout comme le précédent rendez-vous, il s’est extrêmement bien passé sur Gather, elle souhaitait nous aider sans réellement avoir les moyens. Toutefois, des stagiaires avaient été embauchés précédemment dans la mairie pour recenser ces informations. La personne a ainsi pu nous envoyer l’ensemble de ces fichiers : une petite soixantaine !
Suite à ces deux appels, nous étions agréablement surpris de pouvoir obtenir « autant » d’informations et de données au vu de la taille de la commune.
Ensuite, nous nous sommes réunis avec la deuxième partie du groupe en charge de l’organigramme pour faire un point. Avec les informations que l’on avait obtenues, nous avons pu les aider à hiérarchiser l’organigramme et ajouter les contacts. En échange, ils nous ont également aidés à prendre l’outil en main. Ce mindmup est désormais complet, il nous restera uniquement à la fin de la semaine à ajouter les URL des jeux de données. Ils ont simplement eu un problème important pour la sauvegarde du travail. Ils ont effectué une capture d’écran en attendant et ont pu résoudre ce problème avec Julia.
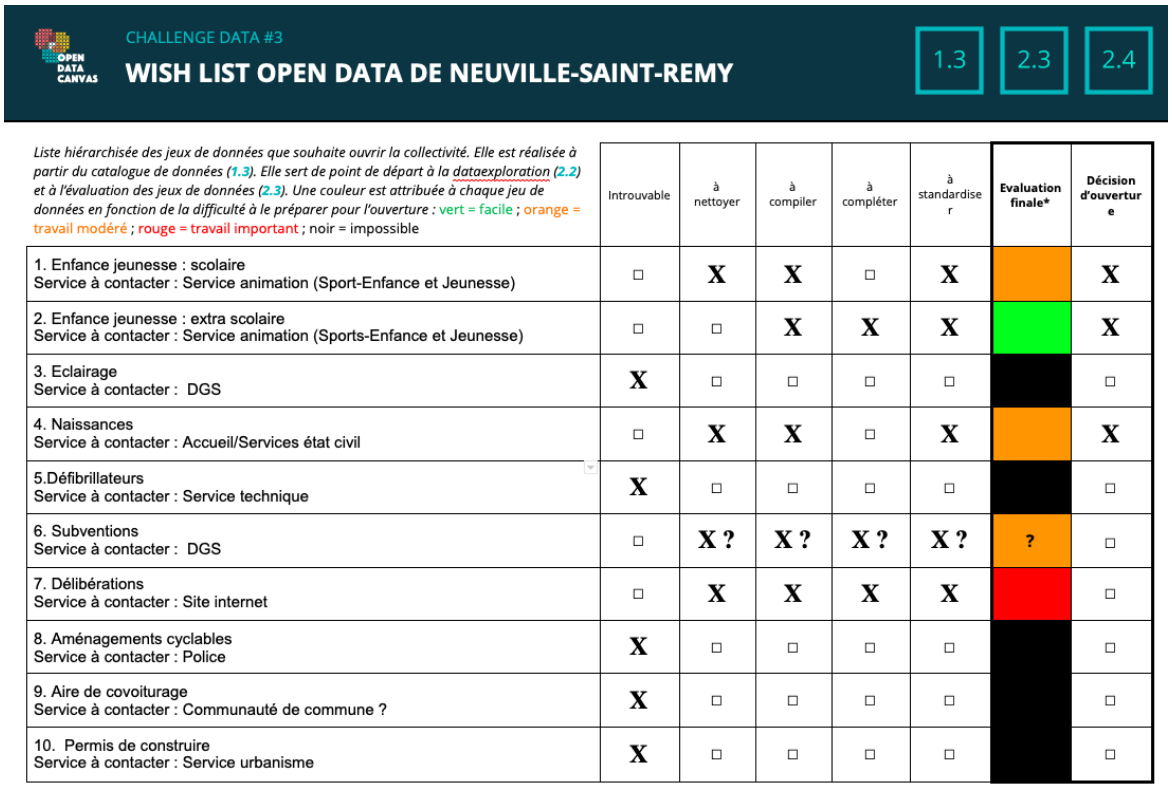
Ce point nous a surtout permis d’évaluer les données que nous avions obtenues. Si nous nous sommes permis d’éliminer directement la moitié des jeux de données, car nous n’avions pas obtenu d’information (aire de covoiturage, aménagements cyclables, permis de construire, défibrillateurs et éclairages), il a été plus compliqué pour les suivants d’en déterminer la qualité des données reçues.
Le premier reçu était celui concernant les structures d’accueil ouvertes pour les enfants et jeunes de la commune. Sous format Excel, nous avons estimé ce travail comme « facile », car le fichier manquait surtout d’une réorganisation. Le second, toujours sur le thème de l’éducation, mais concernant les écoles et la scolarisation, est lui beaucoup plus dur et a été qualifié de « travail modéré ». En effet, il s’agit d’un document PDF comportant 8 documents différents. Il sera nécessaire demain de transférer ce PDF premièrement et d’essayer de créer de ces 8 documents un jeu de données cohérent.
Ensuite, concernant la catégorie que l’on avait nommée « naissance » nous souhaitons la réorganiser en deux sous-catégories au vu de la quantité des documents. Nous allons ainsi pouvoir produire un document sur les prénoms des nouveau-nés et un autre sur les états civils (mariage, décès voire naissance). Nous avons identifié ce travail sous le terme de « modéré », car nous avons la chance d’avoir déjà un format Excel. Toutefois, les 60 documents ainsi que le travail de réorganisation (standardisation et compilation surtout) vont occuper notre temps. Nous souhaitons le garder et allons demain voir le temps qu’on pourra accorder à cela. En effet, nous disposons de toutes les données de 1908 à 2016. Il s’agira donc de sélectionner la période demain à ajuster selon le temps que l’on aura.
Puis, bien que nous n’ayons pas obtenu les données des subventions, notre interlocutrice nous les avait préparées donc nous avons trouvé ça pertinent de ne pas utiliser la case « introuvable », mais attendre demain pour adapter selon l’information que l’on a.
Enfin, comme déjà précisé, les documents de délibération sont des comptes-rendus publiés sur leur site internet. Manquant d’informations (notamment le code et les noms ACTES budgétaires), il nous est compliqué de traiter ce point.
Suite à ce travail d’évaluation de la mise en qualité, nous avons complété une première fois la grille d’évaluation en comparant notamment nos données avec celles disponibles sur les templates d’exemples. Nous avons donc appelé Julia pour lui faire part de nos premiers choix de liste définitive que l’on est en capacité de produire pour la commune. Étant optimistes et motivés, nous souhaitions avoir un avis éclairé sur la question. Elle nous a, comme nous nous en doutions, confirmé que nous avions beaucoup de travail et qu’il faudrait demain réajuster cela selon la période des données sur l’état civil notamment. L’abandon de la case délibération était justifié également selon elle.
Finalement, étant désormais capables d’évaluer ce sur quoi nous étions en capacité de nous engager en accord avec l’avis de Julia, nous avons appelé M. Le Maire, car notre interlocutrice n’était pas disponible. Il était totalement d’accord avec nos choix et nous a remerciés pour notre investissement. Il a toutefois ajouté une dernière envie à notre projet et souhaitait que l’on travaille finalement bien sur les subventions en analysant également le nombre d’adhérents aux associations. Nous avons donc convenu d’un appel demain matin avec lui, notre interlocutrice et/ou unepersonne en charge de l’urbanisme et des associations pour échanger sur cela. Si les données possèdent un cadre de « travail modéré ou simple » et sont fournies avant le début de l’après-midi nous nous sommes engagés à potentiellement le produire. Nous ajusterons ainsi demain la liste.
Nous sommes donc engagés à fournir les données suivantes :
- École et scolarisation
- Infrastructures d’accueil
- Prénom des nouveau-nés (période à déterminer entre 1908 et 2016)
- États civils : Mariage et Décès (peut être naissance)
Deux interrogations restent sur le traitement des données de subventions et de délibérations. Nous reparlerons de ce point demain. M. Le Maire est totalement compréhensif sur cette interrogation.
Ainsi, nous pensons avoir pu passer à travers chacune des étapes définies dans le site opendatacanvas sur lequel nous nous sommes beaucoup appuyés. Seulement, nous avons reçu de nombreux fichiers à nettoyer, corriger et réadapter. Ainsi, nous avons simplement essayé d’uploader quelques tableaux récoltés, mais il s’agissait finalement simplement de test pour prendre l’outil en main. À la fin de la journée de demain, nous serons en capacité d’uploader les bons fichiers. C’est l’unique étape à laquelle nous ne sommes pas capables de répondre totalement ce soir.
Les apprentissages du jour ont été les suivants :
- Plus les informations sont claires et expliquées en amont, plus il est facile de les obtenir. À l’inverse, si un agent n’est pas au courant de notre démarche nous pouvons être sûrs de ne pas obtenir les informations (sauf en passant par M. Le Maire).
- La collecte des données devient aujourd’hui beaucoup plus précise.
- Le travail va être conséquent dans les trois prochains jours malgré qu’il s’agisse d’une petite commune. Sa taille ne nous confère aucune baisse de travail, au contraire, les données n’existent pas en tant que tel et les efforts d’explication et d’informations sont encore plus nécessaires dans cette situation.
En définitive, cette journée a été importante pour cadrer notre travail et évaluer nos possibilités à la suite du travail de récolte. Cette étape nous permet de réellement nous projeter dans les jours à venir alors qu’hier matin il était plus compliqué de comprendre l’ampleur du travail. Bien que motivés, nous nous rendons compte qu’il nous faudrait des jours voire des semaines pour pouvoir mener à bien cette mission en entier. Toutefois, nous restons motivés et avons hâte de mettre en qualité les données récoltées aujourd’hui.
Les documents du jour sont :
JOUR 3 – MISE EN QUALITÉ
Avant de commencer cette journée de mise en qualité des données, nous avons assisté à un briefing avec Julia à 9h. Nous avons ainsi pris connaissance des grandes étapes à venir. Lors de la réunion, il a été rappelé l’importance de fournir des données qualitatives, et correspondant aux standards de publication des données. En effet, ces données doivent être réutilisables et exploitables. Pour nous faciliter la tâche, l’espace de travail du challenge data répertorie quatre grandes étapes clés de mise en qualité des données : nettoyer les données, les compiler, la standardisation et enfin la validation. Nous avons donc pris le temps de regarder en détail chaque étape et chaque vidéo avant de commencer à travailler. Nous avons appris des jours précédents où nous avancions au fur et à mesure et où il était parfois difficile d’avoir un point de vue global sur toutes les tâches à effectuer dans la journée. Compte tenu de la charge importante de travail que la mise en qualité des données représente, nous nous sommes répartis les jeux de données à traiter.
Dans la répartition des tâches, Manon s’est occupée du document concernant les infrastructures d’accueil des enfants de 0 à 17 ans et sur les capacités des différents types d’accueil de l’accueil de loisirs « Les p’tits futés ». Ces informations étaient réunies dans un même fichier Excel avec 2 tableaux différents.
Le premier tableau reprenait déjà la grande majorité des éléments essentiels puisque que nous lui avions envoyé le nom des colonnes de données souhaitées dans notre mail avant notre appel hier. Nous avons ainsi directement pu importer le fichier sur Workbench. Manon a tout d’abord nettoyé en supprimant les colonnes inutiles d’esthétique autour du tableau. Elle a ensuite renommé tous les titres de colonnes pour les adapter au template. Elle a ensuite standardisé le format du contenu, notamment le passage de lettres minuscules en majuscules et l’écriture en nombres des âges sans le mot « ans » apparent. A ce sujet, elle a converti certaines colonnes Texte en format Nombre. Dans le cadre de cette étape, la question qui s’est posée était celle d’adapter la colonne Age_Mini_Mois dans notre situation. En effet, alors que le template standard concerne les infrastructures d’accueil de petite enfance, notre jeu de données intègre également le centre d’animation jeunesse et les écoles, c’est-à-dire au-delà de la petite enfance. Il n’est donc plus pertinent de calculer en mois. Il faut donc réadapter le standard à notre situation. Manon a ensuite décidé de compléter les informations manquantes telles que l’ID. La question s’est posée de quoi faire, comment le créer. Après discussion avec Julia, elles ont décidé de reprendre la structure CodeINSEE-EAJE(issu du template)-001(chiffre croissant) comme vous pouvez le voir dans l’annexe 1. Une autre information était à compléter, celle de la géolocalisation. Une personne du service nous avait communiqué les liens Google Maps, mais pour les adapter de la manière la plus proche au standard, Julia a pu conseiller Manon sur la méthode pour récupérer la latitude et la longitude. Enfin, Manon a effectué une validation manuelle en re-comparant tous les éléments avec le template. Pas de difficulté particulière, seulement quelques ajustements mineurs.
Ainsi a pu être créé le premier jeu de données intitulé « Infrastructures Accueil Enfants 0-17 ans. Voici par exemple le début du jeu de données en annexe 1.
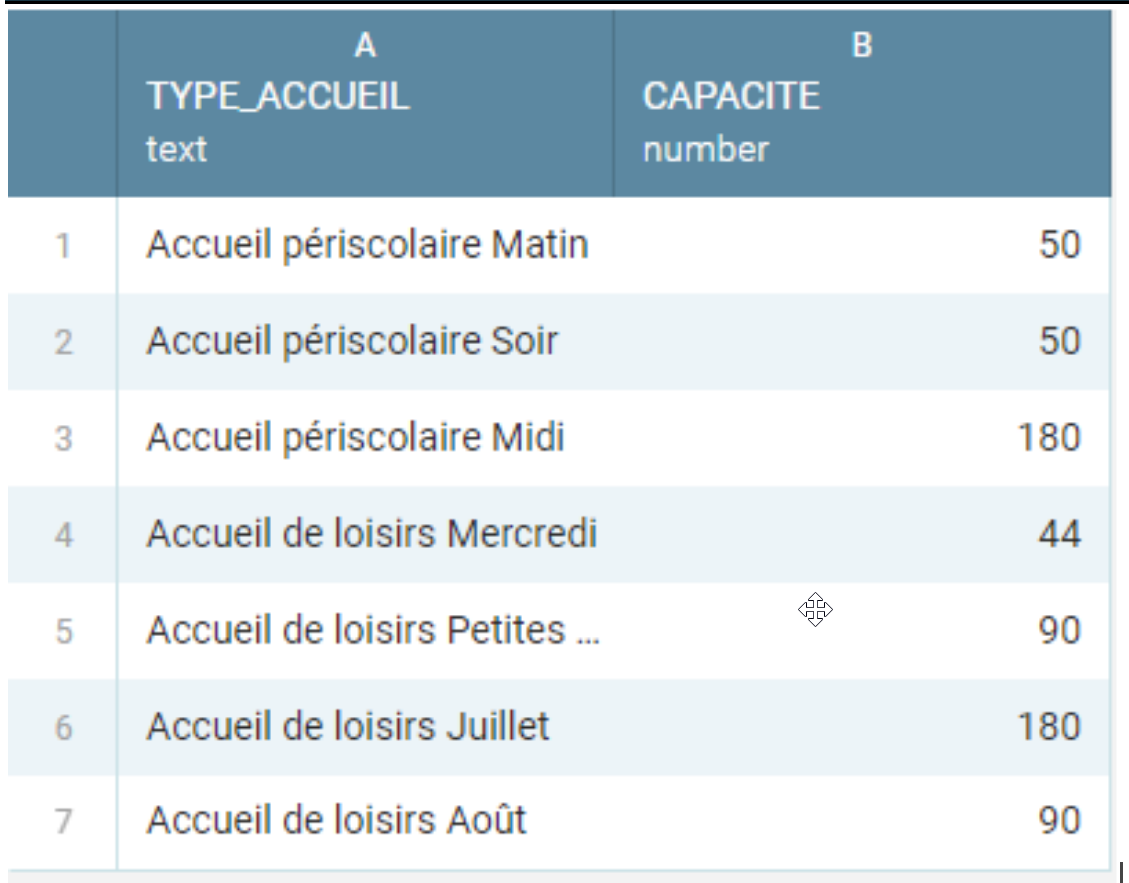
Le deuxième tableau est lui bien plus restreint. Il concerne les capacités de l’accueil de loisirs « Les p’tits futés », distinguant diverses situations d’accueil : accueil périscolaire (Matin, Midi, Soir), accueil de loisirs (Mercredi, petites vacances, Juillet, Aout). La question s’est posée de savoir si on intégrait ces données au premier jeu de données mais le choix a été fait de le séparer en un second jeu de données. Pour le garnir, Manon et Julia ont envisagé d’y ajouter les horaires, et de séparer les accueils du matin et du soir. Après recherches des horaires, il s’est avéré que les horaires ne sont pas forcément fixés étant donné les adaptations aux mesures contre la Covid-19. Il n’est donc pas possible de publier les horaires de manière correcte. Nous nous contenterons donc de ces 2 colonnes, renommées Type_Accueil et Capacité. La validation de ce jeu de données est presque évidente, le jeu de données étant très simple. Ce deuxième jeu de données porte ainsi le titre « Accueil de Loisirs “Les p’tits futés”-Capacité ». Voici son contenu dans l’annexe 2.
Annexe 1 : Début du jeu de données 1 - Infrastructures Accueil Enfants 0-17 ans :
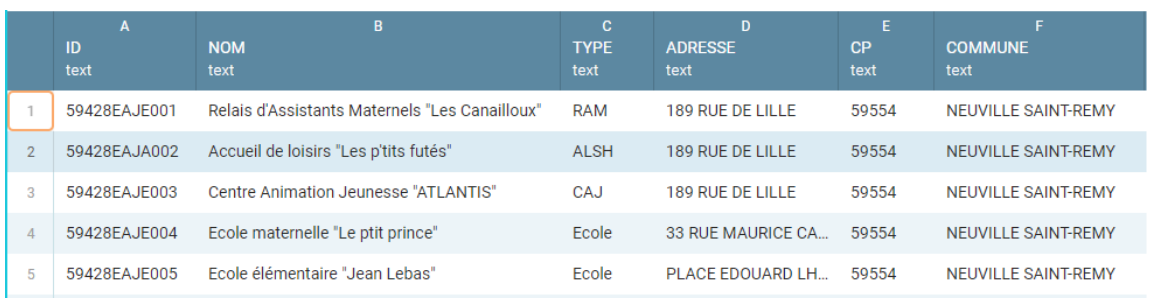
Annexe 2 : Jeu de données 2 - Accueil de Loisirs “Les P’tits Futés”-Capacité
Clémence était chargée de créer le jeu de données sur les prénoms des nouveaux-nés et Yannis était chargé de créer le jeu de données sur l’état civil avec les mariages et les décès. Plusieurs difficultés se sont présentées.
Nous avons reçu 20 dossiers concernant les prénoms des nouveaux-nés de 1908 à 2016. Nous avons décidé de ne pas traiter les années antérieures car nous n’avions pas d’informations entre 1932 et 1953 et entre 1972 et 198. Nous avons donc mis bout à bout tous les dossiers de 1983 à 2016. En effet, nous souhaitons fournir un travail de qualité en se limitant à l’année 1983 ce qui représente plus de mille lignes. Nous avons supprimé la colonne « nom de famille » car il s’agit d’une donnée personnelle que l’on ne peut exploiter. Autre difficulté majeure concernant les prénoms des nouveaux nés : il manque la donnée du sexe. À ce moment, nous décidons dans un premier temps de faire sans cette donnée.
De plus, d’autres données nécessitent une réadaptation du format d’écriture. Nous avons donc décidé d’effectuer ces premières modifications sur excel que nous maîtrisons mieux, avant d’importer les tableaux un peu plus “propres” sur Workbench. Il a ainsi fallu ajouter les colonnes « Commune_Nom » (NEUVILLE-SAINT-REMY) et « Coll_Insee » (59428).
Trois grandes difficultés se sont alors présentées pour le jeu de données sur les prénoms :
La première difficulté est que le tableau nous donne les dates exactes avec le nom de la ville de Naissance. À l’aide de l’outil « remplacer par », Clémence a supprimé les villes de naissance. Toutefois, nous avons rencontré des difficultés car selon les années les dates étaient écrites de différentes manières. Nous avons utilisé deux outils : remplacer par (par exemple : sept. Remplacer par septembre) et « format de cellule » (pour mettre tout sous le format jj/mm/aaaa). Ensuite, nous avons créé une nouvelle colonne pour inscrire seulement les années avec la formule =(ANNEE;CELLULE) il était simple de le faire.
La deuxième grande difficulté était d’isoler le premier prénom (car dans la case des prénoms il y avait tous les prénoms écrits. Clémence a utilisé la formule : =GAUCHE(C239;(CHERCHE(“ « ;C239;1))-1) -> « C239) correspond simplement à la cellule où il y avait tous les prénoms. Cette formule est très efficace, seulement il y avait parfois des erreurs dû au fait qu’il y avait qu’un prénom. Dans ce cas-là, il s’agissait simplement de copier-coller le prénom. Par la suite, il a fallu trier le fichier par ordre du plus récent au plus ancien (outils : clic droit -> trier -> du plus récent au plus ancien -> étendre la sélection). Enfin, il ne manquait qu’à compter les occurrences des prénoms donnés, grâce à la formule: =NB.SI($D$2:$D$1529;D2). Après avoir effectué ce tableau, nous avons fait l’essentiel du travail. Nous avons repris les différentes étapes et avons fait quelques modifications que l’on peut retrouver sur Workbench : suppression de la colonne avec les deuxièmes, troisièmes et quatrièmes prénoms. Il a également fallu nettoyer en raison de la présence de ponctuation.
Nous avons cependant pris conscience, grâce au schéma dont le lien figure sur Workbench que le sexe figure aux données essentielles. Il est donc impossible de publier ce jeu de donnée sans la mention du sexe. Ainsi nous sommes demandés comment obtenir ces informations sans devoir passer chaque ligne manuellement afin de déterminer selon le prénom s’ il s’agit d’un garçon ou d’une fille (sachant qu’il y a en l’espèce plus de 1400 lignes). Paul-Alexis a ainsi pris ce problème à bras le corps. Plusieurs difficultés se sont présentées à lui. Tout d’abord il s’agissait de trouver les bonnes formules pour le nettoyage et la standardisation (formules de calcul d’effectif/exportation des genres à partir d’une base de données data.gouv). En outre, tous les prénoms donnés dans la ville ne correspondent pas à l’ensemble de la base de données. Il fallait par conséquent vérifier à la main et valider en fonction des deuxièmes prénoms, le risque d’erreur est ainsi limité au maximum. Paul-Alexis a ainsi procédé à plusieurs étapes; le nettoyage des données avec calcul des effectifs à partir d’une formule excel (=nb.si). La standardisation avec d’abord l’export d’un fichier prénom/genre pour déterminer le sexe du nouveau né (fichier data gouv de 24 000 éléments), puis l’utilisation de la formule =recherchv pour comparer les noms du fichier source au fichier data gouv et ainsi avoir une colonne sexe valide et enfin la vérification des erreurs M/F et les corrections. Pour qu’il ne soit pas nécessaire de reproduire ces manoeuvres, nous soulignerons auprès de la mairie l’importance de mettre les données sur le sexe. Une vérification manuelle a ensuite été réalisée pour valider le document.
Début du jeu de données “prénoms” :
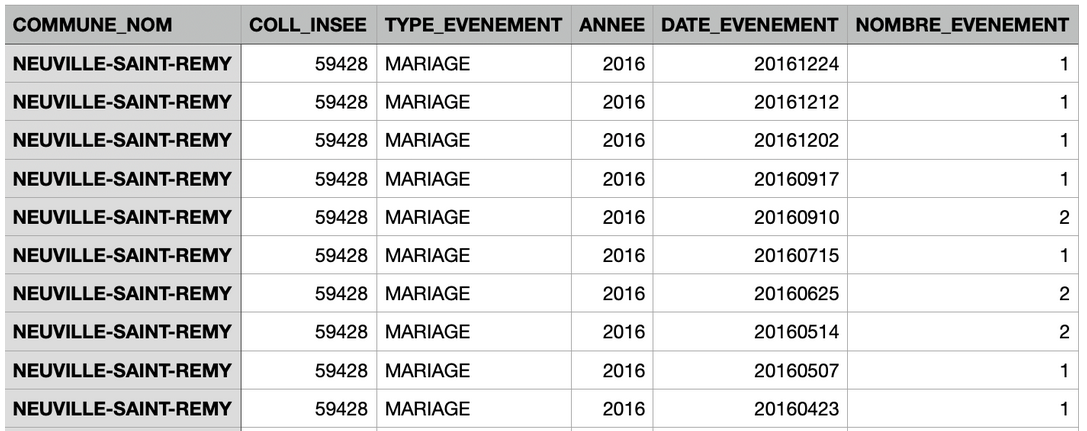
Les difficultés étaient similaires pour les actes d’état civil. Il a dans un premier temps fallu se référer au schéma pour s’assurer que nous disposions des éléments obligatoires concernant les décès et les mariages. Il s’agit en l’espèce du jour, du nombre de décès ou mariage par jour considéré, et de l’année de relevé. Si les documents fournis comportent toutes ces informations, les tableaux Excel contenaient également des informations en trop, notamment les noms et prénoms des mariés ou des personnes décédées. Nous avons ainsi procédé au nettoyage sur Excel avant d’importer les fichiers sur Workbench. Ici aussi, il a fallu traiter des dates sous différentes formes (écrit en toutes lettres, avec des “/” ou des “-”) Il fallait modifier ces dates au format standard pour l’état civil : aaaammjj. Il fallait également ajouter une colonne sur le nombre de mariages ou décès le même jour et trier du plus récent au plus ancien. Le travail le plus fastidieux a été d’importer les différents documents Excel qui comprenaient différentes formes d’écriture de dates dans un seul document.
Il a ensuite fallu l’importer dans workbench. Il fallait supprimer les doublons pour que les dates où il y avait plusieurs événements ne soient inscrits qu’une fois, avec dans la colonne de droite leur nombre. L’ultime difficulté a concerné la validation. Ce jeu de données ne dispose pas de validateur, il a donc fallu le valider manuellement. Nous nous sommes à ce moment rendu compte que certaines dates présentaient des erreurs. En effet, il arrivait que l’année ne corresponde pas à la date événement. Il était donc nécessaire de modifier manuellement les années. Cette étape apparaît dans la case 8 sur Workbench et aurait pu être réalisée de manière automatique mais cette fonctionnalité n’a pas été trouvée.
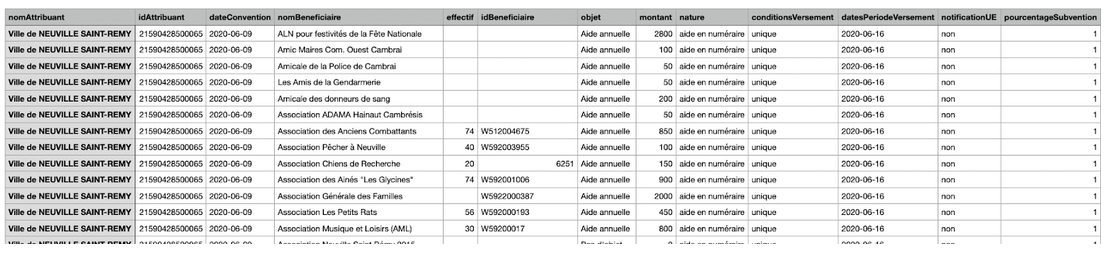
PA était chargé de s’occuper du jeu de données sur les subventions. Notre interlocutrice nous avait transmis un tableau qui était malheureusement en format word. Il a également fallu trouver la carte d’identité de Subvention sur data.gouv/data.Paris pour pouvoir standardiser les données. Paul-Alexis a ainsi eu la tâche de transformer le fichier en excel et le nettoyer(cases vides, titre, lignes inutiles (Total), redéfinition en texte). Il a ensuite fallu ensuite importer le fichier sur workbenchdata. Malheureusement l’upload avait modifié complètement les chiffres, chiffres qui se sont retrouvés avec des décimales etc… PA a beaucoup cogité car certains chiffres étaient considérés comme des textes et d’autres comme des chiffres. Finalement après quelques temps, il a trouvé l’origine du problème et a refait un excel et à dû de nouveau retranscrire tous les chiffres.
L’upload a finalement marché sur workbenchdata. Il manquait plus qu’à contacter un membre du service qui, malgré un emploi du temps chargé, s’est engagé à nous transmettre les données manquantes dans l’après-midi. Une fois celles-ci reçues, il a fallu les compiler et de nouveau standardiser en respectant la carte d’identité (suppression de doublons, suppression des colonnes/lignes inutiles, suppression des “,” et “-”…).
La dernière étape de mise en qualité concernait la validation. Pour cela, ce jeu de données “subventions” bénéficie d’un validateur. Après de nombreux essais, nous sommes parvenus à entrer le jeu dans le validateur et nous avons obtenu un score de cellules valides de 87.9%

Après l’analyse des recommandations :
La mention “cellules vides (16)” correspond aux associations qui n’ont pas reçu de subvention pour l’année 2020. Il a été décidé, en accord avec le maire, de laisser les associations qui n’avaient pas de subvention cette année et ne pas les supprimer pour lui permettre d’avoir un point de vue global et réfléchir aux subventions de l’année prochaine.
La mention “numéro SIRET invalide” est liée à l’absence de numéro SIRET pour les associations. En effet, il s’agissait ici de traiter uniquement les subventions aux associations.
La mention “Format incorrect (21)” est liée au fait qu’il y a des textes et numéros dans une case où il est censé y avoir que des chiffres.
L’analyse ne fait état d’aucune erreur de structure.
Il faut enfin préciser que certains effectifs sont introuvables malgré les recherches et l’implication de Monsieur Guidez.
Début du jeu de données subventions :
Jeremy au début de la journée était chargé de rechercher des jeux de données existants pour pouvoir créer un jeu propre sur les données scolaires. Il n’y avait en effet pas de template sur les données scolaires dans les 28 sur Workbench. Pour cela, il a d’abord tenté de retrouver des templates sur schema datagouv.fr, open data France ou « communes pionnières de l’open data ». Cependant, ces sources se sont ici avérées inutiles car servent seulement à standardiser les données et ne contiennent pas d’exemple type pour des données scolaires.
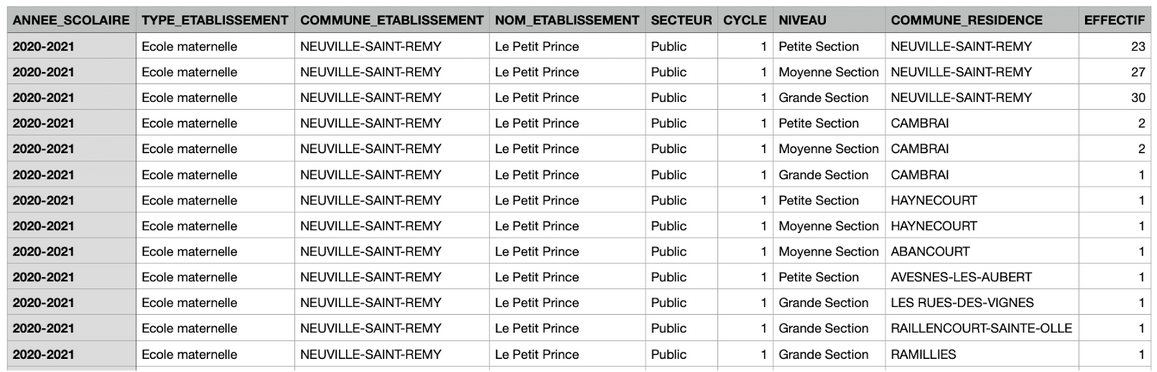
Jérémy a ensuite fait appel à Julia pour réfléchir sur les lignes qu’il fallait créer à partir des données en notre possession. Certaines données ont été exclues (les pourcentages qui sont déjà des calculs, ou des données qui sont ici intéressantes ou inexploitables). Il est ressorti de l’échange que 3 jeux de données pouvaient être créés. Lors de la définition de la liste d’envies par le maire, ces données avaient été évoquées et nous apparaissent donc comme importantes. Il nous faut donc 2 autres jeux de données : un concernant les enfants de neuville pour voir ou ils sont scolarisés et ceux qui sont scolarisées à Neuville pour savoir d’où ils viennent. Jeremy a ensuite reporté les données dans Excel. Cette tâche s’est avérée longue car chaque case de chaque ligne et chaque colonne représente une ligne dans excel. Si résumer cette activité prend ici une phrase, elle a en réalité occupé une majeure partie de l’après-midi. A 17H30, Jérémy avait validé les données pour la provenance géographique des élèves scolarisés à St Remy ainsi que les effectifs genres par niveau. Il restait donc un possible dernier jeu de données à réaliser. Cependant, compte tenu du temps restant et des tâches qu’il nous restait à réaliser, nous avons préféré rester sur les deux jeux de données de qualité et laisser de côté le troisième.
Début jeu de données “Provenance géographique des élèves de primaire scolarisés à NSR” :
A la fin de la journée, il restait une dernière étape : l’envoi d’un mail à notre interlocutrice pour la confirmation et validation des données et la programmation d’un rendez-vous à demain pour en discuter de vive voix. Nous lui avons dans ce mail partagé les 7 jeux de données avec la fonctionnalité “share” depuis workbench. Voici ci-dessous les 7 jeux de données exportés depuis workbench :
Neuville Saint Rémy / Infrastructures Accueil enfants 0-17 ans / Jeu de données 1:
https://app.workbenchdata.com/public/moduledata/live/582808.csv
Neuville Saint Rémy / Accueil de loisirs “Les p’tits futés”- Capacité / Jeu de données 2:
https://app.workbenchdata.com/public/moduledata/live/582265.csv
Neuville Saint Rémy / Effectifs genrés par niveau pour le primaire / Jeu de données 3 :
https://app.workbenchdata.com/public/moduledata/live/582865.csv
Neuville Saint Remy / Provenance géographique des élèves de primaire scolarisés à NSR / Jeu de données 4 :
https://app.workbenchdata.com/public/moduledata/live/582911.csv
Neuville Saint Rémy / Actes Etat Civil - Mariages Décès / Jeu de données 5 :
https://app.workbenchdata.com/public/moduledata/live/582762.csv
Neuville Saint Rémy/ Prénoms / Jeu de données 6 :
https://app.workbenchdata.com/public/moduledata/live/583046.csv
Neuville Saint Rémy / Subventions / Jeu de données 7 :
https://app.workbenchdata.com/public/moduledata/live/582860.csv
JOUR 4 – PUBLICATION
La journée d’hier a été la plus éprouvante de la semaine puisque nous l’avons consacré à créer les 7 jeux de données que nous nous étions engagés à publier en fin de semaine. Mais cette journée a surtout été celle de notre propre production de données, notre valeur ajoutée, au service de la collectivité de Neuville-Saint-Rémy.
Ce quatrième jour de Challenge Data a une fois encore débuté par un rapide briefing animé par Julia dans lequel elle nous a expliqué les missions de la journée. Il s’agissait aujourd’hui de publier les données que nous avions produites la veille sur une plateforme nationale appelée data.gouv.fr, sur laquelle il est notamment possible de trouver une myriade de données déjà déposées par différents organismes.
Avant de commencer sa présentation des différentes tâches, Julia a d’abord tenu à rappeler qu’il fallait rendre accessibles nos liens workbench que nous avions créés hier à la collectivité en s’assurant de cocher la case « Share with the world ». Cette information nous a été d’une grande utilité puisque le matin-même, Clémence a reçu un mail de la part de notre interlocutrice à ce sujet. Effectivement, hier en fin de journée, Clémence avait rédigé un mail à notre interlocutrice résumant les grandes lignes de notre travail. Dans le corps du mail, elle avait ajouté des liens workbench pour lui permettre d’accéder aux jeux de données que nous avions créés, mais ces derniers se sont avérés inaccessibles par notre interlocutrice, d’où son mail du début de matinée. L’éclairage de Julia sur ce point nous a donc permis de répondre rapidement à ce problème. Nous avons profité de notre réponse à ce mail pour proposer un rendez-vous téléphonique à notre interlocutrice à 10h30 pour refaire un point sur nos missions de la journée.
Entre temps, Julia s’est jointe à notre table pour nous demander de nos nouvelles. Elle voulait s’assurer que nos liens workbench que nous avions transmis à la collectivité étaient bien accessibles. Mais surtout, elle voulait nous féliciter, et plus particulièrement féliciter Paul-Alexis, pour son travail hier concernant les manipulations sur la plateforme workbench, notamment avec l’option « join » qu’il avait utilisé sur le jeu de données 6 portant sur les prénoms à la naissance. Cela a amené Julia à évoquer les travaux récents d’un sociologue à propos des prénoms donnés en France aux hommes et femmes depuis le début du XXe siècle. Le sujet de la conversation s’est ensuite porté sur la réutilisation de nos données par la mairie, puisque l’exportation des jeux de données sur workbench étaient des documents CSV. Julia nous a appris à ouvrir un document CSV sur Excel afin de le modifier, puis une fois celui-ci mis à jour, l’exporter à nouveau en format CSV en vue sa publication sur le site data.gouv.
En attendant la réunion après le départ de Julia de notre table, nous nous sommes attachés à visionner les vidéos disponibles pour la Challenge Data expliquant les différentes étapes de la journée. Trois étapes rythmaient la journée : le remplissage des fiches descriptives des jeux de données, la publication des données et de leur fiche descriptive sur un portail open data, et enfin la communication de la commune autour de l’ouverture des données. Suite au visionnage de ces vidéos, nous nous sommes mis à réfléchir en vue de remplir les fiches descriptives. Dans un souci de répartition des tâches et de productivité dans notre travail de groupe, Paul-Alexis s’est mis à penser puis à écrire notre message de communication évoqué dans la mission 3.
Vers 10h40, n’ayant pas de nouvelles de notre interlocutrice, nous avons pris la décision de l’appeler au téléphone. Elle nous a rapidement répondu, et Clémence et Manon se sont chargées de mener la discussion via FaceTime pour favoriser la convivialité. Durant cet entretien, chacun de nous a présenté les jeux de données qu’il avait produit, Manon les deux premiers jeux de données, moi-même les deux suivants, Yannis le cinquième, Clémence le sixième, et Paul-Alexis le dernier. Notre interlocutrice a tenu à nous féliciter pour ce travail considérable que cela avait demandé. Nous cherchions par cet appel son accord pour faire valider ces jeux de données. Validation que l’on a eue aussitôt, et ce pour une raison simple : elle n’avait pas besoin de l’aval de Monsieur le Maire pour cette décision puisque la commune de Neuville-Saint-Rémy comptant moins de 50 agents temps plein, elle n’était donc pas tenue d’ouvrir ses données comme le préconise la loi pour une République numérique. Cette démarche était ainsi optionnelle. En fin de discussion, nous lui avons informé que nous allions écrire une note sur la publication des données. Notre question portait sur le support adéquat sur lequel véhiculer cette communication. C’est à ce moment-là que nous avons appris qu’une personne du service Animation, était en charge de la communication de la mairie. Il n’existe en effet pas de référent communication au sein de la mairie. Nous devions donc nous mettre d’accord avec elle pour voir quelle forme allait prendre la communication autour de l’ouverture des données dans la journée. Notre interlocutrice a enfin accepté notre proposition de rédiger en son nom un mail qu’elle pourrait envoyer en interne à la mairie pour détailler l’ouverture des données réalisées au cours de notre Challenge Data.
Pour la fin de matinée, le groupe s’est scindé en deux : les premiers s’attachaient à remplir les fiches descriptives, tandis que les autres peaufinaient le message de communication, puis préparaient un logo pour le message. Paul-Alexis était à l’œuvre sur le logiciel Canva pour cette tâche. Yannis et Clémence ont eux appelé par téléphone le service État Civil, pour qu’il les aide à remplir certaines informations, à savoir : les raisons de production des données, le processus de la collecte et la fréquence de mises à jour. Lors de cet appel, il est ressorti que les données avaient été compilées pour la première fois il y a deux ans et que désormais la mairie disposait d’un logiciel qui actualise en temps réel les informations lorsque celles-ci sont créées. De plus, il a été précisé que les données d’État civil étaient obligatoires et que sur recommandation des archives, la commune avait procédé à des tables décennales. Une fois ces informations obtenues, il a été possible de compléter ces deux fiches descriptives.
Concernant les jeux de données l’enfance et la jeunesse, il nous manquait à Manon et à moi-même les mêmes informations pour remplir les fiches descriptives. Nous avons fait le choix de prévoir un appel dans l’après-midi avec le service Animation et Jeunesse, chargé de communication de la mairie, nous voulions attendre que notre texte de communication et notre logo soit prêt pour rassembler dans notre appel nos deux demandes.
Au sujet du logo, Paul-Alexis en avait créé 7 variantes, reprenant les couleurs (le bleu, le jaune et le gris) et la police que l’on trouve sur le site de la commune. Il a également ajouté le cerf, blason de la ville, que l’on retrouve sur l’emblème des associations sportifs de la ville. Julia s’est par hasard retrouvée au milieu de ce vote, ce qui lui a permis de nous conseiller de conserver la charte graphique de la ville. En effet, Paul-Alexis avait ajouté une quatrième couleur au blason, mais qui ne correspondait pas donc à la charte graphique.
Annexe 1 : Logo Open Data

Après avoir déjeuné deux quiches lorraines cuisinées par Clémence et moi-même, notre groupe a entamé la deuxième étape de la journée : la publication des données. Pour ce faire, Manon a créé un compte sur le site data.gouv.fr en renseignant le nom, prénom et mail de Paul Alexis. Manon a également pu créer la rubrique organisation nommée Commune de Neuville-Saint-Rémy. Elle a notamment complété le nom de la commune, le sigle, le logo (une fois celui-ci finalisé), la description et le site web. Le prochain mail adressé à notre interlocutrice consistait ainsi à lui indiquer comment elle pouvait créer un compte sur ce site, puis devenir l’administrateur de la page. C’est notamment ce que nous avons mentionné dans le mail que nous nous sommes proposés d’écrire en son nom pour informer les différents services de nos démarches.
A 15h a commencé notre appel avec le service communication. Comme avec notre interlocutrice, nous avons Manon et moi-même présenté nos quatre jeux de données Enfance et Jeunesse, en indiquant les différents problèmes que nous avions rencontré, notamment pour moi où j’ai dû construire deux jeux de données ad hoc. Suite à ce rapide aperçu, nous lui avons posé des questions pour pouvoir compléter les fiches descriptives sur ces jeux de données. Il nous a fait part de la provenance des données, des raisons de leur publication et de leur fréquence de publication. Enfin, nous avons abordé la communication que nous proposions autour de la publication des données. Si le service a validé le texte, il a préféré que nous remplacions le cerf par le blason de la ville sur le logo Challenge Data, le souci étant que l’image publiée sur le site de la mairie doit être libre de droit, c’est-à-dire qu’il n’y ait pas de droit d’auteur. Pour cela, il suffit de chercher une image sur google en mettant le caractère licence « creative commons » dans la rubrique outils. Il a confirmé que nous publierons notre communication sur le site internet de la commune et l’application NSR direct de la commune, avec notamment un délai de 24h avant la publication sur le site web de la mairie. Nous nous sommes enfin proposés de rédiger un retour par mail de l’entretien que nous venions d’avoir.
En parallèle, Yannis s’est connecté sur la plateforme data.gouv pour publier nos jeux de données. Il a commencé par le premier jeu : Infrastructures d’accueil des enfants de 0 à 17 ans. Le site n’était pas évident pour s’y retrouver mais il s’y est retrouvé pour remplir la description, le contenu, la licence, les mots clés, la couverture temporelle et spatiale, et la granularité spatiale (commune française). Clémence est venue rapidement l’aider pour accélérer la publication. L’enjeu a été d’uniformiser les métadonnées destinées à qualifier les jeux de données publiés, surtout que plusieurs personnes différentes ont publié, et que chacun a rempli les critères à sa manière. Pour répondre à la demande express de Julia, nous avons joint l’hashtag #ChallengeData à toutes nos publications.
Annexe 2 : Publication des 7 jeux de données sur data.gouv.fr
Les dernières tâches de la journée ont concerné le mail récapitulatif adressé à notre interlocutrice dans lequel nous lui avons joint l’organigramme des sources de données mis à jour, le PDF des fiches descriptives rédigées dans la journée, et le PDF intitulé « Créer et gérer un compte sur data.gouv.fr ». En dessous du mail se trouvait notre proposition de message que pouvait envoyer notre interlocutrice en interne pour informer les différents services de l’ouverture des données de la commune sur le site data.com.fr.
Il est à noter qu’après la création de notre compte sur le site open data, la certification du compte a été effectuée, ce qui nous a finalement facilité la tâche dans la publication des données. Aussi, étant donné que la ville de Neuville-Saint-Rémy est très petite, un plan de communication n’a pas été nécessaire pour amener l’ouverture des sept jeux de données publiés par la commune.
Les apprentissages du jour ont été les suivants :
· Savoir structurer nos appels téléphoniques lorsque nous avons plusieurs questions à aborder avec notre interlocuteur
· Répartir les missions qui ont pu être réalisées presque simultanément, contrairement aux autres jours où la réalisation d’une étape conditionnait le passage à la suivante
URL des jeux de données publiés :
-
Infrastructure d’accueil des enfants de 0 à 17 ans
-
Capacité de l’accueil de loisirs “Les p’tis futés”
-
Effectifs genrés par niveau dans les établissements
-
Provenance géographiques des élèves de primaire
-
Mariages, décès
https://www.data.gouv.fr/fr/datasets/actes-etat-civil-mariages-deces-de-neuville-saint-remy/
-
Prénoms des nouveaux nés
https://www.data.gouv.fr/fr/datasets/prenoms-des-nouveaux-nes-de-neuville-saint-remy/
-
Subventions
https://www.data.gouv.fr/fr/datasets/subventions-de-neuville-saint-remy/
JOUR 5 – VALORISATION
Le jour 5 sonnait la fin de l’aventure challenge data. Nous étions déterminés à finir en beauté et à fructifier les efforts faits tout au long de la semaine. Comme à l’accoutumé, la journée commençait par une petite conférence commune et au visionnage des vidéos tutoriels du site de datactivist. La stratégie choisie par l’équipe était simple: faire au moins 4 datavisualisations sur les jeux de donnés les plus pertinents pour les Neuvillois et les agents de la commune. Nous avons passé notre journée pratiquement en autonomie, contrairement aux autres jours. Les premières difficultés ont commencé dans la compréhension des logiciels proposés: Umap, Raw Graph et Open Data soft. Des noms barbares qui n’inspiraient pas confiance. Pourtant, ils nous ont rapidement aiguillés dans la concrétisation graphique des questions globales que nous nous étions posées devant nos 7 jeux de données publiés la veille. Leur prise en main a été cependant difficile, notamment pour Raw Graph ou seulement une personne sur nous 6 arrivait à importer des fichiers CSV… mystère. L’idée était de favoriser les datavisualisations à plusieurs variables avec à la fois de la répartition géographique, une évolution dans le temps, des comparaisons de valeurs et des proportions. La machine était lancée, nous nous sommes chacun réparti des axes sur lesquels il n’y avait qu’un seul mot d’ordre: la réussite.
Comme dit précédemment, nous avions pour objectif de créer 4 datavisualisation, d’en faire l’analyse et de les publier:
- Une map de données géographiques sur les infrastructures d’accueil des enfants de 0 à 17 ans
- Un diagramme en bâton sur la répartition des mariages de la commune pour chaque mois, toutes les années confondues
- Un diagramme hiérarchique de répartition des subventions par associations neuvilloises pour l’année 2020
- Et enfin, avec une ambition élevée, un graphique dynamique montrant l’évolution des prénoms les plus donnés au sein de la commune, à l’instar de celui qui nous avait subjugué dans le tweet d’un professeur de sociologie
Si nous les finissions rapidement, nous entamerions d’autres datavisualisations. Par une efficacité remarquable et un sens collectif à son apogée, ce fut rapidement le cas.
PA entama le pas en proposant un graphique de compartimentage représentant toutes les subventions des associations. Quelle n’en fut pas la surprise de voir que la légende proposée par excel ne pouvait accueillir que 20 associations, et non pas 38. Après de nombreuses tentatives, l’idée fut abandonnée. Yannis avait notamment essayé de créer un graphique similaire sur Raw Graph, mais en vain, car nous n’arrivions pas à modifier la taille des compartiments, leur place et le format du texte. PA s’est alors dirigé vers un graphique en secteurs avec une focalisation en barre sur les plus petites associations bénéficiant des subventions, car nous ne les voyions pas suffisamment. Le choix a été fait de mettre à la fois le montant et la proportion des subventions pour rendre le graphique plus accessible et avec le maximum de données disponibles.
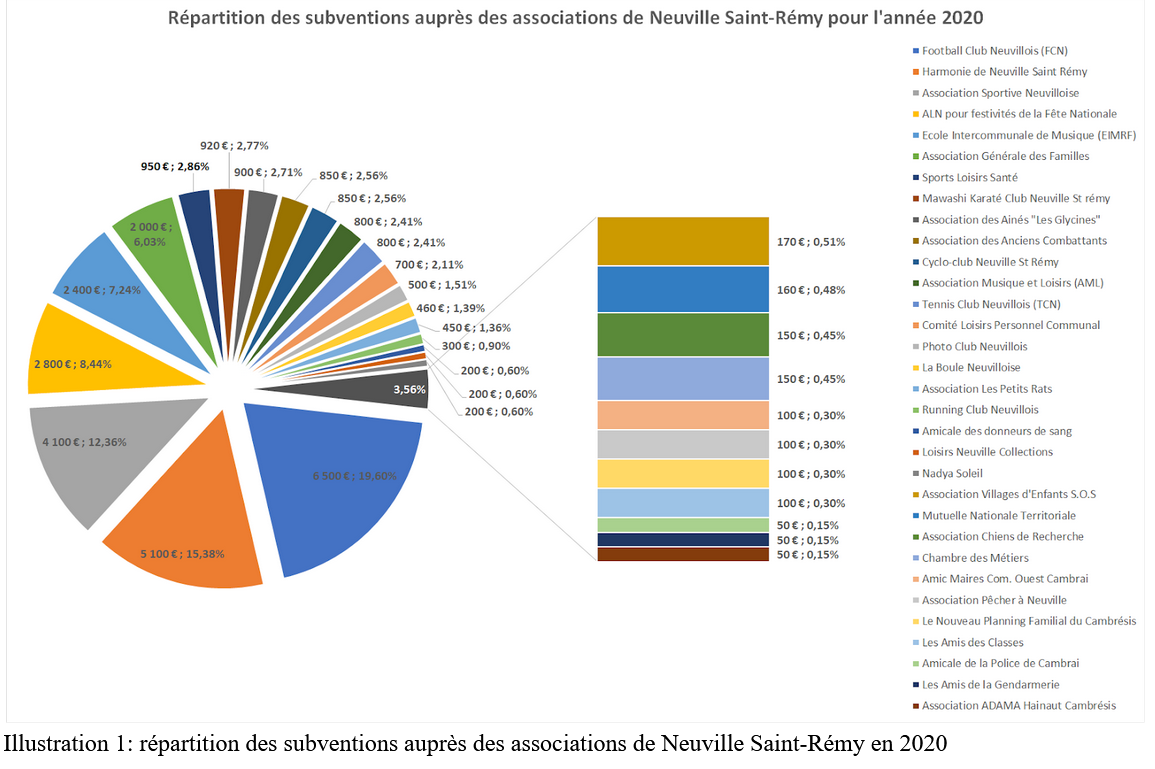
Illustration 1: répartition des subventions auprès des associations de Neuville Saint-Rémy en 2020
Dans le même temps, un Yannis de compétition accoucha sur une datavisualisation issue de Raw Graph. Seul à pouvoir le dompter, il arriva à cumuler l’ensemble des mariages depuis 1983 jusqu’à 2016 distinctement pour chaque mois. Un graphique sans appel qui montre que les mariages dans le Nord s’effectuent principalement en été mais aussi en septembre et en décembre où le froid règne. La difficulté a été de modifier les abscisses et les ordonnées, chose que nous n’avons pas réussi à faire directement sur Raw Graph, nous sommes donc passés par Excel pour cette étape précise.
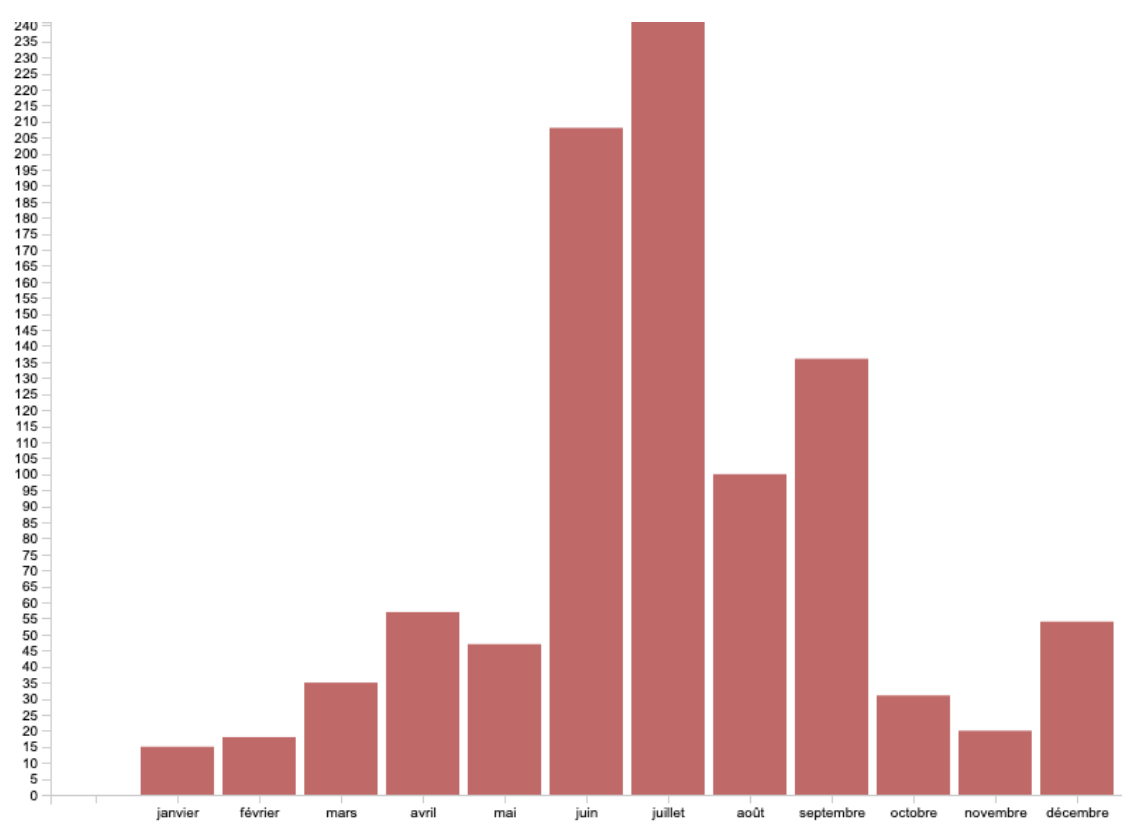
Illustration 2: saisonnalité des mariages à Neuville Saint-Rémy entre 1983 et 2016
Notre journée est allée de surprise en surprise. Alors que la réalisation des datavisualisations battait son plein, Manon et Jérémy se sont attelés à créer une datavisualisation géographique des infrastructures d’accueil des enfants de 0 à 17 ans. Un difficulté s’est rapidement présentée: les données géographiques préalablement entrées dans les jeux de données étaient erronées. Il a fallu les modifier (latitude, longitude) sur data.gouv. L’autre problème a été de trouver le bon contributeur, étant donné les droits d’auteur. Après acharnement, une première carte graphique faite à partir de Umap a vu le jour: une réussite difficile qui entamait le pas sur une journée à succès.
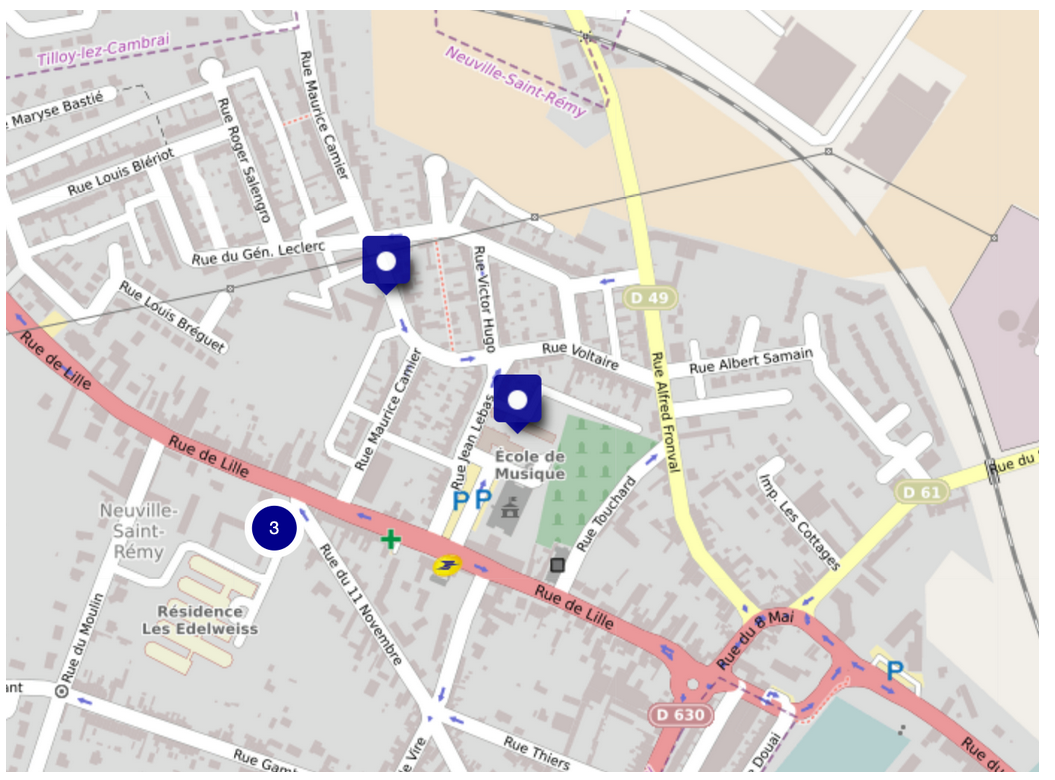
Illustration 3: localisation des infrastructures d’accueil des enfants de 0 à 17 ans de la Ville de Neuville Saint-Rémy
En fin de matinée et en début d’après-midi, PA et Clémence ont créé non pas 1, ni 2, mais 3 datavisualisations à partir du jeu de données des prénoms et des sexes à la naissance de puis 1983. A partir d’Excel, deux premiers graphiques ont vu le jour par la main éveillée de Clémence: les 2 TOP 10 des prénoms féminins et masculins donnés aux nouveaux nés de 183 à 2016 à Neuville Saint-Rémy. Mise à part la place hiérarchique des prénoms qui était à modifier, la réalisation de ces graphiques n’a demandé que du temps et de la patience.
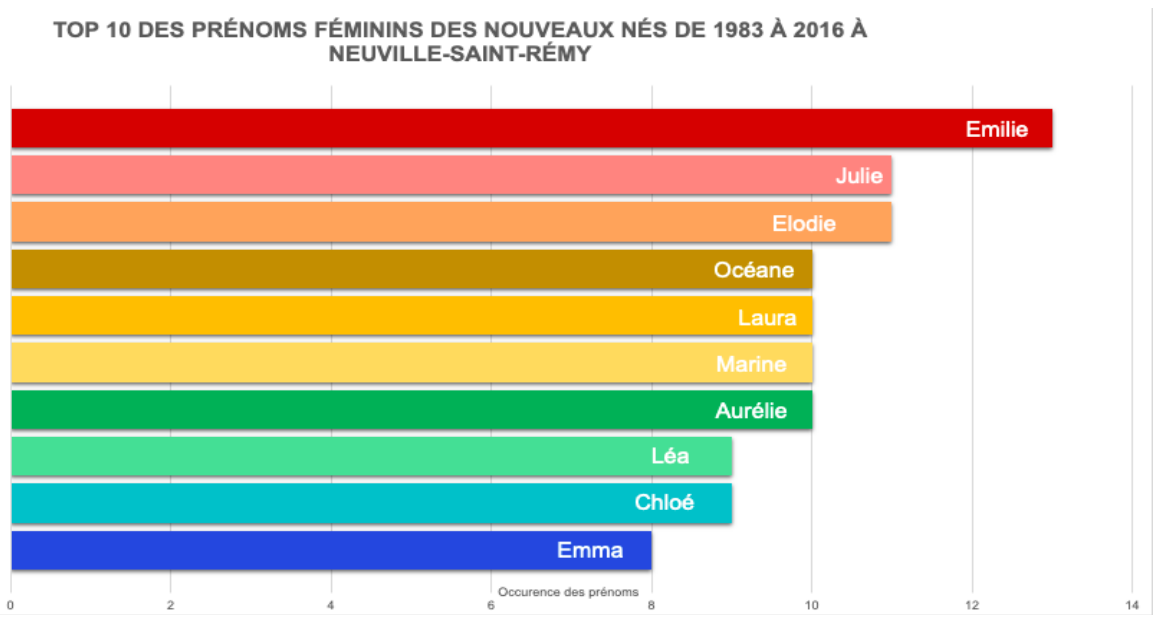
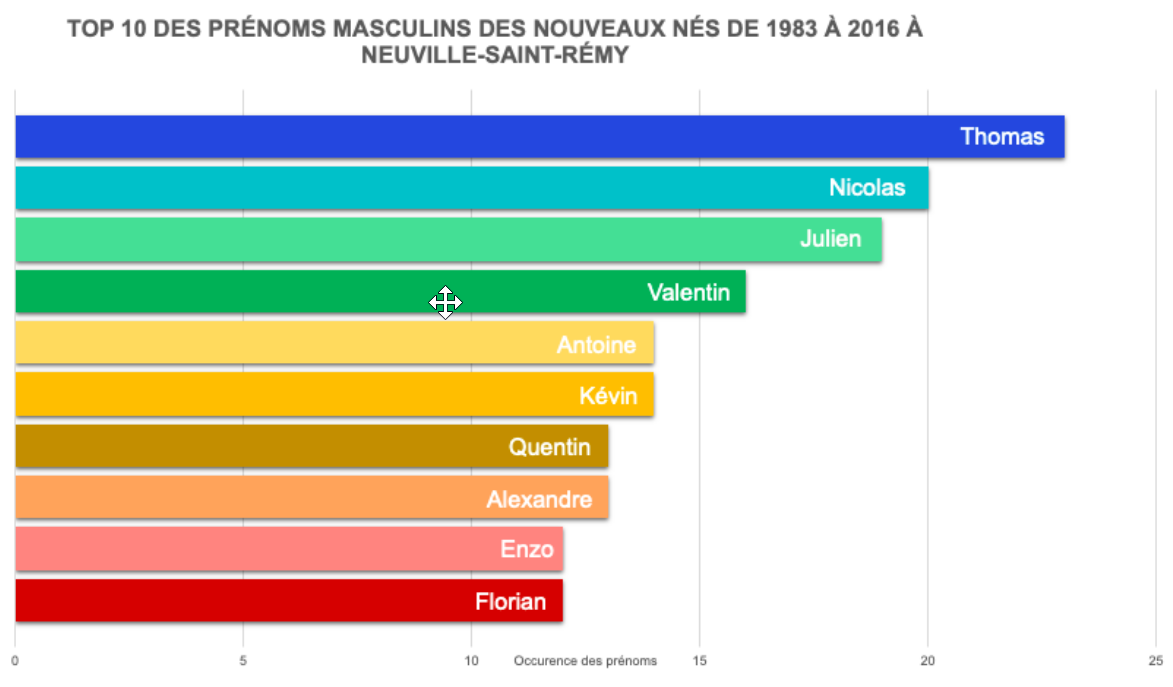
Illustrations 4 et 5: TOP 10 des prénoms féminins et masculins des Neuvillois(es) de 1983 à 2016
Dans un but plus statistique, PA a réalisé 3 graphiques superposés qui prenaient en compte à la fois le nombre de naissances de filles et de garçons, le nombre totale de naissances et la répartition des naissances en fonction du sexe. La difficulté a été de mettre en statut secondaire les diagrammes et les courbes pour pouvoir rendre harmonique le graphique cumulé. Comme dans tous les graphiques utilisant ces jeux de données, l’année 2013 manquait des données fournies par la mairie. Néanmoins, la tendance globale subsistait. La formule =NB.SI.ENS a été très utile pour aller dénicher dans les milliers de ligne le nombre d’occurence du sexe par année et permettre les diagrammes en bâton. Le graphique de comparaison était fait.
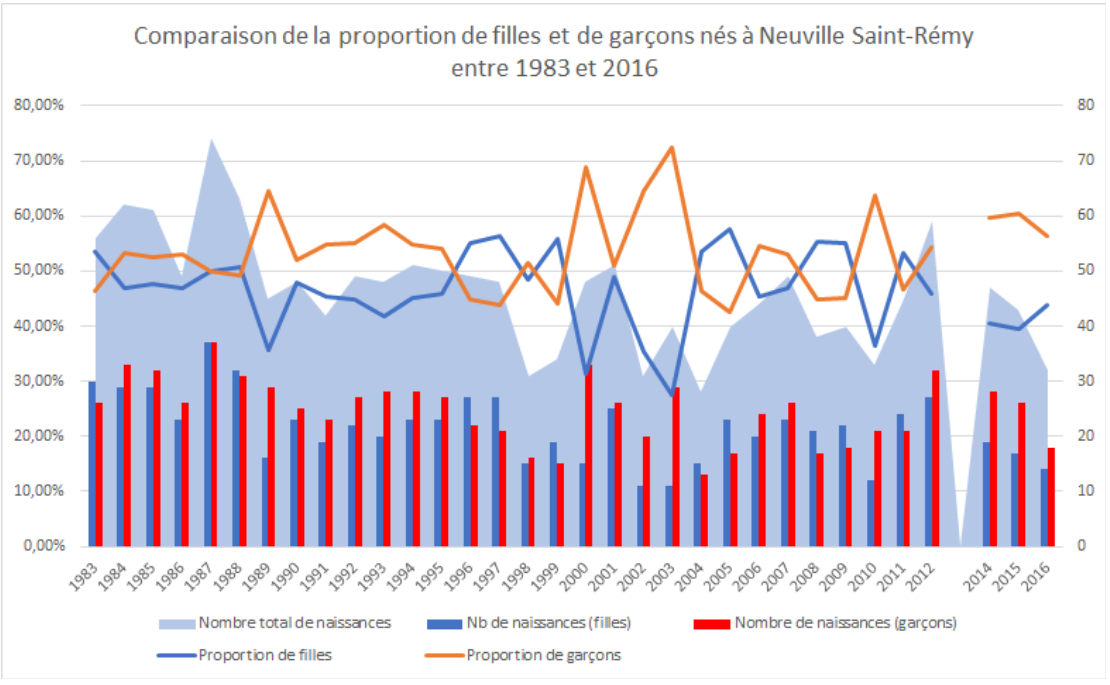
Illustration 6: comparaison de la proportion de filles et de garçons nés à Neuville Saint-Rémy entre 1983 et 2016
Entre-temps, l’ensemble de l’équipe s’attelait équitablement à remplir l’analyse et la description des datavisualisations au fur et à mesure de leur construction. Leur publication était cependant chapeautée d’une main de maître par Manon et Yannis, experts en la matière.
Clémence et Manon ont eu un appel surprise en début d’après-midi de notre interlocutrice. Après une explication du mail envoyé la veille et des différents pdf mis à disposition, et une création d’un statut administrateur sur data gouv, nous lui avons demandé si elle avait besoin d’une méthodologie pour utiliser un fichier CSV à partir de data.gouv. Elle a accepté l’offre avec grand intérêt.
Aussitôt demandé, PA et Manon se sont executés et ont préparé un document word de 14 pages de méthodologie pour notre interlocutrice (et plus globalement l’ensemble des agents) pour télécharger un fichier sur data gouv, le transformer en excel, le modifier et ensuite l’exporter pour actualiser les données. Un document qui détaille toutes les étapes, utile pour le débutant comme le novice.
Pour continuer dans une bonne voie, Jérémy a recruté Yannis pour créer une nouvelle map de datavisualisation encore plus difficile à réaliser. L’idée était de cartographier la provenance géographique des élèves de primaires scolarisés à Neuville Saint-Rémy. L’implacable Jérémy s’est donc lancé dans une course contre la montre toute l’après-midi et a fait face à de nombreux problèmes. Faire une capture d’écran d’une carte de la ville et pointer maladroitement les emplacements sans distinction quantitative était d’emblé rejeté. La qualité, ou rien. Après avoir choisi le format bubble map chart, il fallait trouver un logiciel: Umap n’a pas répondu aux attentes, alors à partir d’une vidéo explicative sur youtube, Excel a été une nouvelle fois choisi. Au début, il était pensé de saisir les données géographiques des communes une par une et changer les colonnes de workbench, puis de les exporter en csv. Mais cela n’a pas fonctionné. La deuxième option se révelera être la bonne: importer la couverture géographique de google maps en arrière plan d’un graphique à point où chaque point correspond à une localisation d’une ville d’où proviennent les élèves. La précision nécessaire était conséquente. Il restait à changer la taille des villes pour les rendre proportionnelles au nombre d’élèves qu’elles envoyaient: l’effectif a été rentré pour faire concorder. Le dernier problème a été de rendre transparente la bulle correspondante à Neuville pour ne pas occulter les deux villes dans le rayon proche de la ville. Une fois fait, quelques ajustements ont suffit. Le jeu en valait la chandelle, le résultat laisse sans voix.
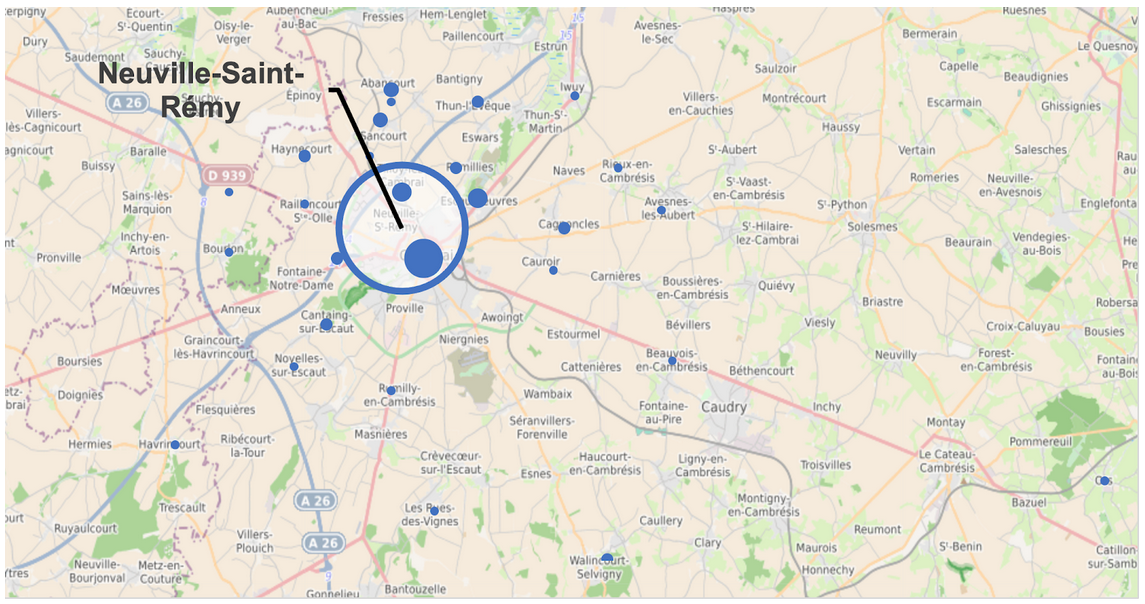
Illustration 7: cartographie bubble map chart de la provenance géographique des élèves de primaire scolarisés à Neuville Saint-Rémy
Un membre de notre équipe s’est proposé tout au long de la journée pour la tâche la plus lourde et ambitieuse: essayer tant bien que mal de réaliser un graphique dynamique montrant l’évolution des prénoms de Neuville Saint-Rémy depuis 1983. Il a réussi a déniché la série de code informatique qu’avait utilisé le sociologue pour l’adapter à notre jeu de données. Avec le logiciel R, il a tenté de recréer un nouveau graphique, en vain car le jeu de données utilisé par le sociologue n’avait pas le même nombre d’années, le même nombre de noms et différenciait les filles des garçons. D’autres problèmes de codes dépassant notre compétence sont survenus. Après plusieurs heures, il a aboutit à la création d’un graphique qui était bien dynamique, mais peu fluide, avec une superposition des noms qui avaient le même nombre d’occurence à l’année. C’était un début, mais le combat continuait. L’après-midi, après l’intervention de Julia et sa proposition d’utiliser flourish comme logiciel, un autre graphique a été construit, plus dynamique, sans superposition. Nous étions très satisfait du résultat.
Cependant, en s’inspirant d’un graphique dynamique crée sur flourish présentant l’évolution de la population dans les pays du globe, nous avons réussi à réaliser une prouesse: un graphique dynamique évolutif comprenant tous les prénoms des naissances à Neuville Saint-Rémy depuis 1983. L’équipe avait trouvé la clé de l’énigme en faisant un tableau en cumulé croissant des noms donnés à la naissance. Le résultat était au-dessus de nos espérances et fortement similaire à celui du professeur sociologue. Nous avons donc terminé la journée en apothéose.
Lien vers la datavisualisation créée: https://public.flourish.studio/visualisation/5342253/
Bilan de la journée: 8 jeux de données sur 4 escomptés, et des étoiles dans les yeux.
CONCLUSION
Cette semaine de Challenge Data a été très enrichissante à la fois pour nous, étudiants à Sciences Po Saint Germain en Laye, mais aussi pour la commune de Neuville-Saint-Rémy. Le bilan est positif puisque 7 jeux de données et 8 datavisualisations ont été publiés. Nous sommes fiers de ce bilan, la commune de Neuville-Saint-Rémy est désormais ouverte, alors même qu’elle n’y était pas contrainte.
- Bilan de la commune
La commune de Neuville-Saint-Rémy tire donc de nombreux bénéfices de ce partenariat:
Elle a désormais un compte sur data.gouv.fr avec 7 jeux de données publiés sur divers sujets et 8 datavisualisations les accompagnant. Ces jeux de données ont pour sujet les infrastructures d’accueil des enfants de 0 à 17, les capacités d’accueil de l’Accueil de loisirs “Les pt’its futés”, les effectifs genrés des élèves du primaire, la provenance géographique des élèves scolarisés à Neuville Saint-Rémy, les actes civils de mariages ou de décès, les prénoms des nouveaux nés et enfin les subventions accordées en 2020 aux associations de la ville de Neuville-Saint-Rémy. Les 8 datavisualisations sont diverses, avec une carte de localisation des infrastructures d’accueil des enfants, une carte des villes de résidence des enfants scolarisés à Neuville Saint-Rémy, quatre graphiques sur les prénoms des nouveaux nés, dont une animation dynamique et enfin un graphique circulaire sur la répartition des subventions.
La commune de Neuville-Saint-Rémy a également bénéficié d’un apport de connaissances sur le sujet de l’Open Data. En effet, alors débutante en la matière, la commune et ses agents sont désormais plus au clair sur la notion de données et ses implications, notamment celle de produire des documents sous forme de tableurs standardisés dès leur création.
La commune de Neuville-Saint-Rémy a surtout franchi la première marche de son ouverture. Cette marche est la plus dure avec de nombreux freins, en termes de connaissances, de compétences et de temps. Grâce à cette lancée, la commune va pouvoir poursuivre cette ouverture en s’appuyant sur notre travail et nos conseils. C’est à la fois intéressant pour eux à l’avenir mais aussi pour les citoyens de la commune disposant de ces données, élément important dans le cadre d’une recherche de transparence.
Toutes ces réalisations ont été permises grâce à de nombreux leviers bien qu’on ait été confronté à quelques freins.
Les leviers principaux ont été la disponibilité, la réactivité et la coopération avec les différents agents de la Mairie. Un grand merci à notre principale interlocutrice lors de cette semaine. Merci à Monsieur le Maire, pour ses conseils et sa bonne humeur. Merci également à tous les représentants des services pour leur aide en nous accordant de leur temps pour comprendre notre projet et nous communiquer les fichiers dont ils disposent. Nous notons que le faible nombre d’agents dans la commune était un atout puisque la communication entre eux nous a été utile dans nos recherches. Nous avons également apprécié la totale confiance qui nous a été accordée dans nos réalisations.
Cependant, il y a eu quelques freins, à savoir le manque de connaissances initiales de certains agents sur le sujet de l’open data, le manque de données disponibles et le format des fichiers demandant un gros travail de préparation avant publication. Tout d’abord, il y a eu un travail de pédagogie pour expliquer nos requêtes, en distinguant notamment le terme d’information et celui de données à proprement parler. Ces données justement étaient parfois inexistantes, au point que nous avons dû abandonner de nombreux potentiels jeux de données que l’on avait inscrits sur notre wishlist. Et même si l’on a pu en récupérer certains, la majorité des fichiers nécessitaient un gros travail de nettoyage, compilation, complétion et standardisation, et ce, notamment à cause de formats de fichiers.
Au-delà de ces freins, nous retenons surtout le positif. Nous sommes fiers d’avoir pu aider la commune de Neuville-Saint-Rémy à entreprendre son ouverture de données.
- Bilan du groupe
Nous, étudiants de Sciences Po Saint Germain en Laye, sommes ravis d’avoir pu participer à un tel projet. Nous avons relevé le défi lancé par Datactivist d’ouvrir les données de la commune de Neuville-Saint-Rémy, et nous sommes heureux d’avoir partagé une telle expérience en tant que groupe. La réalisation de nos objectifs a été permise par de nombreux leviers, bien qu’il y ait eu quelques freins.
Tout d’abord, de nombreux leviers nous ont permis d’atteindre nos objectifs et même de les dépasser, notamment notre cohésion au sein du groupe, l’accompagnement indéfectible de Julia, et notre capacité d’adaptation constante aux problèmes rencontrés. Nous avons su en effet s’organiser tout au long de la semaine pour travailler ensemble et se répartir les tâches. Nous avons été un vrai groupe tout au long du projet, soudé et solidaire, s’entraidant sur chacune des missions. Le fait d’être réunis en présentiel à 5 a été un réel atout pour retrouver du lien social dans ce contexte et ainsi travailler dans la joie et la bonne humeur. Un grand merci également pour l’aide inestimable de Julia, qui nous a soutenu tout au long de la semaine et avec qui on a eu le plaisir d’échanger. Mention particulière à votre tonton, votre fils et votre chat, on ne s’attendait pas à rencontrer toute la famille, on adore cette convivialité en tout cas ! Un grand merci également à toute l’équipe de Datactivist pour ces fichiers, sites, vidéos et explications plus que complètes pour nous accompagner au mieux jusque dans les moindres détails. Cela a été d’autant plus bénéfique que ça nous a permis d’être le plus possible autonomes en adaptant toute consigne à notre cas. La débrouillardise a été de rigueur également cette semaine, et un grand merci à tous les membres de notre groupe d’étudiants qui ont su utiliser les compétences diverses et variées au service du projet de groupe.
Ces échanges de compétences ont été d’autant plus essentiels que nous avons été confrontés à de nombreuses difficultés. Ces freins concernaient notre manque de connaissances sur l’open data, notre manque de compétences techniques sur certains logiciels et outils ou bien encore le contenu des fichiers reçus ne correspondant pas à des jeux de données ayant des templates. Premièrement, nous étions au début de la semaine tout autant débutant que la commune de Neuville-Saint-Rémy sur le principe de l’Open Data. Heureusement que Julia était présente lors de notre premier appel avec la directrice générale des services et Monsieur le Maire pour clarifier les termes et les objectifs. Deuxièmement, nous avons été confrontés lors de cette semaine à l’utilisation de nombreux logiciels ou outils sur lesquels nos compétences étaient limitées voire inexistantes. Savoir utiliser Workbench, savoir créer des formules sur Excel, savoir ouvrir un fichier CSV ou bien encore savoir utiliser RawGraph ont été les plus gros freins à notre avancée. Nous avions en effet de nombreux problèmes techniques. Troisièmement, nous avons été confrontés à des situations dans lesquelles le contenu des fichiers qui nous avaient été communiqués ne correspondaient à aucun exemple de jeu de données. Il nous a donc fallu faire preuve de gymnastique pour proposer des jeux de données ad hoc.
Ces freins ont été importants, mais ne nous ont pourtant pas empêché de mener à bien notre mission. Ils ont au contraire été l’occasion de réfléchir encore plus pour trouver des solutions. Cette semaine a ainsi été pleine d’enrichissements pour la commune de Neuville-Saint-Rémy et pour le groupe, mais elle nous est également bénéfique personnellement pour nous, individuellement parlant en tant qu’étudiants en sciences politiques.
Cette semaine a en effet été source de nombreux apprentissages et nous a apporté des éléments essentiels pour notre développement personnel et professionnel.
Tout d’abord, cette expérience a été intéressante pour comprendre l’OpenData. Nous avons compris ce que veut dire ouvrir ses données, ce que sont des jeux de données et surtout ce que cela représente comme enjeux. En effet, au-delà de l’ouverture des données, nous avons compris les objectifs de la démarche que ce soit en termes de transparence vis-à-vis des citoyens ou bien en termes de mise à disposition de données pour des réutilisations à de plus larges échelles.
Cette expérience est également intéressante en termes de compétences en la matière. Nous savons désormais comment nettoyer, compiler, compléter et standardiser un jeu de données, et nous savons aussi comment le publier sur le site data.gouv.fr.
Cette expérience est également particulièrement enrichissante pour des étudiants en sciences politiques comme nous, puisque cela nous fait mettre un pied dans les collectivités. Dans le cadre de cette semaine, nous avons eu l’occasion d’entrer en contact avec des agents travaillant à la mairie, des personnes au cœur de la démocratie locale. C’est une chance de pouvoir échanger avec eux, mais également de pouvoir comprendre le fonctionnement d’une collectivité au travers de ses différents services.
Cette expérience a également comme atout de nous confronter à de nombreux logiciels et outils dont on ne connaît pas le fonctionnement, ce qui nous pousse à nous interroger. La maîtrise de ces outils reste encore relative mais nous avons tous quand même pu développer des compétences dans leur utilisation. Bien qu’il est possible qu’on ne recroise pas certains logiciels dans notre parcours, l’outil Excel est un outil indispensable auquel il est important de se former, et cette semaine aura été l’occasion d’apprendre à mieux le maîtriser.
Cette expérience est également une expérience très professionnalisante, bien qu’ayant lieu initialement dans le cadre scolaire de nos études à Sciences Po Saint Germain En Laye. En effet, alors que nous sommes à l’heure actuelle étudiants, le futur proche est notre intégration dans le monde du travail. Pour cela, nous devons adopter des comportements professionnels et cette expérience en a été l’occasion. En effet, nous étions sur un rythme de travail intense, nous travaillions en équipe, nous devions s’organiser, prioriser les tâches ou bien encore gérer notre temps afin de tenir nos engagements. Nous nous sommes engagés sur des réalisations, et pour cela, nous avons fourni le travail, communiqué sur nos avancées, et nous nous sommes adaptés aux demandes des interlocuteurs. Cette expérience a donc été une mise en situation professionnelle très enrichissante sur le plan personnel en termes de développement de compétences dites “soft skills”.
Ainsi, cette expérience a été très enrichissante sur tous les plans, en termes de connaissances et compétences liées à l’open data, en termes de connaissances des collectivités, en termes de compétences techniques et enfin en termes de compétences professionnelles. Cette expérience est ainsi valorisable dans le cadre de nos futures recherches de stages et d’emploi.
- Plus gros casse-tête
Dans le cadre de ce challenge data, notre plus gros casse-tête a été de savoir utiliser les logiciels et outils techniques. Rappelons nous par exemple toutes les formules Excel nécessaires pour créer le jeu de données des prénoms des nouveaux-nés, couplé au_ join _nécessaire pour récupérer le sexe à partir d’un autre fichier récupéré sur data.gouv. Rappelons nous également la datavisualisation de la carte de la provenance géographique des enfants scolarisés à Neuville Saint Rémy, ou bien encore la datavisualisation dynamique du palmarès des prénoms… un vrai casse-tête.
- Plus belle réussite
Notre plus belle réussite est d’avoir publié 7 jeux de données et 8 datavisualisations pour la commune de Neuville-Saint-Rémy. Nous sommes d’autant plus fiers que 7 jeux de données est proche du record du challenge data, que Neuville-Saint-Rémy n’était pas contrainte à ouvrir ses données, et que notre interlocutrice nous a exprimé toutes ses félicitations pour le travail fourni. Nous avons tenu nos engagements et même réussi à proposer encore plus de publications… c’est une belle réussite.
Et pour finir…
Et pour finir, un grand merci à tous pour cette superbe semaine de Challenge Data. Un grand merci à Julia, un grand merci à toute l’équipe de Datactivist, un grand merci à Sciences Po Saint Germain en Laye, un grand merci à l’Agence Nationale pour la Cohésion des Territoires, un grand merci à l’ensemble des membres du groupe et un grand merci à tous les agents et Monsieur le Maire de la commune de Neuville Saint-Rémy.