Carnet de bord de l’ouverture des données de Grenoble-alpes Métropole
par Maël Leroux, Ninon Thomas, Axel Delbecq, Alice Ferber, Emma Le Berre, Matthieu David Larrousse et Clémence Oswald

INTRODUCTION
Tout au long de cette semaine nous allons accompagner Grenoble-Alpes Métropole (GAM), située en région Auvergne-Rhône-Alpes. Avec près de 450 000 habitants, il s’agit de l’intercommunalité la plus peuplée. Les 49 communes qui composent la Métropole sont largement dominées par le poids de la ville de Grenoble qui compte à elle seule 160 000 habitants.
Si la Métropole n’a pas été un acteur pionnier sur la question des données ouvertes, elle reste néanmoins un acteur engagé. En effet, l’article 106(V) de la loi nᵒ 2015-991 du 7 août 2015 portant nouvelle organisation territoriale de la République a assujetti la métropole de Grenoble-Alpes et ses parties prenantes à l’obligation de publication de données ouvertes, à compter de 2018 (Art. L1112-23 Code général des collectivités territoriales). Ce principe d’ouverture par défaut des données publiques communicables avait pour objectifs de constituer un levier d’innovation économique, d’améliorer la transparence et l’efficience de l’action publique. Dans le cadre de la GAM, toutes les collectivités territoriales n’y sont pas soumises puisque seules les collectivités territoriales de plus de 3500 habitants et employant plus de 50 agents (en équivalent temps plein) y sont tenues.
De cette obligation est née une démarche commune entre la Ville de Grenoble, Grenoble-Alpes-Métropole et le Syndicat Mixte des Mobilités de l’Air Grenobloise (SMMAG), matérialisée par le portail de données ouvertes http://data.metropolegrenoble.fr/. Cette démarche engagée a permis de mutualiser à l’échelle de la métropole l’ouverture des données des 49 communes avec l’outil open source Ckan. Lancée en 2015, cette plateforme revendique aujourd’hui la mise à disposition de plus de 135 jeux de données et la réutilisation de plus de 19 jeux de données. Cet outil favorise le développement des données ouvertes à l’échelle métropolitaine avec la mise en avant d’une démarche type à suivre pour les parties prenantes souhaitant publier des données. Les thématiques abordées sont globalements au nombre de six : “Solidarité et Citoyenneté” (42), “Aménagement du territoire” (41), “Transport et Mobilité” (32), “Education et Enfance” (11) “Culture” (10), “Environnement (4)”.
La ville de Grenoble et la SMAAG sont les principaux producteurs de données ouvertes puisqu’ils représentent à deux plus de la moitié des données publiées. Le bilan de cette plateforme est plutôt positif même si deux aspects sont préoccupants.
Aujourd’hui, seules 5 collectivités territoriales semblent réellement impliquées et publient des données régulièrement. S’agissant ensuite du traitement des métadonnées, l’absence de grandes lignes directrices au niveau national semble être un frein à un traitement global.
Par ailleurs, la GAM a pu s’affirmer comme un acteur important au niveau national, de 2017 à 2020, avec la nomination de Laurence Comparat, représentante de la Ville de Grenoble, à la présidence de Open Data France, qui oeuvre à regrouper et soutenir les collectivités territoriales françaises dans leur démarche d’ouverture de leurs données.
Tous ces éléments permettent de dresser le portrait d’une métropole et d’acteurs territoriaux résolument tournés vers la transparence et le partage des données ouvertes. Conscients de ces enjeux, ils ont mis au point une démarche que nous entendons renforcer.
JOUR 1 – DIAGNOSTIC
Cette première journée de diagnostic nous a appris à : nous immerger dans une collectivité territoriale de grande échelle (445 000 habitants pour 49 communes), appréhender les objectifs de ce challenge, organiser notre emploi du temps à la journée et se projeter sur la semaine entière, comprendre nos propres limites, agir avec transparence et professionnalisme, surmonter les tâches complexes et techniques, ne pas nous arrêter aux aléas déstabilisants.
Depuis sa création en 2015, la métropole de Grenoble investit dans l’open data. Elle a déjà publié 135 jeux de données et ses services sont autonomes sur ce point (ils utilisent le logiciel libre CKAN). C’est une situation spécifique par rapport aux 18 autres communes participantes. Nous pensions qu’elle serait un atout, mais elle s’est révélée être un frein à notre démarche.
La motivation de la métropole à ouvrir ses données réside dans la transparence de la vie politique. Elle veut rendre des comptes aux citoyens, les informer du fonctionnement de l’entité en interne, et se conformer à la loi de 2016. La métropole évoque aussi un objectif pédagogique, en termes de décloisonnement entre les différentes directions : il s’agit de faire en sorte que la donnée soit accessible.
Réussites de la journée :
- La première réunion à 11h45 avec notre référent 1 et notre référent 2 (membre de son équipe), tous deux sont très volontaires, bien formés et réceptifs. Ils ont clairement identifié le thème de la finance/économie/gestion comme une priorité dans leurs attentes.
- La disponibilité et la bienveillance d’Allyson sont aussi à souligner, car il s’est évertué à nous guider tout au long de la journée, même dans les temps forts
- Nous nous sommes efforcés de déchiffrer le langage complexe des métadonnées et des logiciels évoqués malgré notre non-initiation
- Nous nous sommes rapidement approprié l’interface Canva du challenge data grâce aux tutoriels intuitifs et nous avons fait preuve de réactivité en contactant immédiatement par appel téléphonique nos relais à Grenoble (30 en tout)
- La “pêche à la donnée” et l’exploration sur les bases de données ne nous ont pas fait peur, mais nous nous sommes pourtant rapidement heurtés à des réalités qui nous dépassaient.
Les difficultés sont survenues dès lors que nous avons cherché à contacter les responsables de service, en nous basant sur un tableau de coordonnées transmis par notre référent 1.
Difficultés de communication :
- En amont, la métropole n’avait pas officiellement communiqué sur notre démarche (ou alors les récepteurs n’avaient pas pris connaissance des mails qui leur avaient été envoyés) donc il était difficile de nouer un lien de confiance avec les détenteurs des données, peu enclins à nous écouter
- Les responsables de services ne voyaient pas quels documents nous attendions d’eux (des fichiers de données brutes en format xml, cvs ou excel), ils avaient l’impression d’avoir déjà publié leurs données sur leurs propres sites (ville, communauté de communes, plutôt que sur data.gouv) et donc ne ressentaient aucun intérêt ni le besoin de nous solliciter. Or, selon notre référent 1, “leurs documents ne répondent pas aux standards de l’open data car ils sont publiés en format PDF, et donc inexploitables”
- Le niveau de maturité des interlocuteurs quant à la data variait d’un service à l’autre (certains ne voyaient pas de quoi l’on parlait, tandis que d’autres disposaient déjà une équipe dédiée à la data)
- Sur les 28 responsables que nous avons démarchés, peu nous ont accordé de leur temps, et nous avons souvent été redirigés de standards en standards, parfois sans aboutissement. Malgré nos relances par téléphone et par mail, aucun interlocuteur n’a accepté de nous envoyer de document
- C’est pourquoi nous pensons que le contact de petites communes, membres de la métropole, aurait été plus utile que celui de services importants au fonctionnement déjà huilé, et détaché du site de l’open data métropole
- Dernier problème de communication, et de taille : la ville de Grenoble et sa métropole sont en clash politique. On nous a conseillé de nous présenter sous la casquette de la ville, afin de ne pas se faire éconduire. Or la convention a été passée avec la métropole.
Difficultés logistiques :
- S’adapter à un format hybride (certains responsables travaillent en présentiel, d’autres chez eux)
- Multiplier les interactions sur les plateformes et interfaces (Gather, Zoom, Drive, site du Challenge Data, site de l’open data de la Métropole de Grenoble)
- L’indisponibilité de nos interlocuteurs (la zone de Grenoble est en période de vacances scolaires, ce qui complexifie nos échanges)
- Les imprévus techniques (mise à jour du site Gather, connexions instables, ordinateurs pas assez puissants)
- “L’aveuglement” de la métropole quant à l’utilisation faite de ces données à la suite de leur publication : elle ne peut pas accéder au nombre de téléchargements, il lui manque cette traçabilité qui lui permettrait d’évaluer précisément l’intérêt de l’open data.
Ci-dessous le tableau qui résume nos efforts du jour, hélas souvent vains.
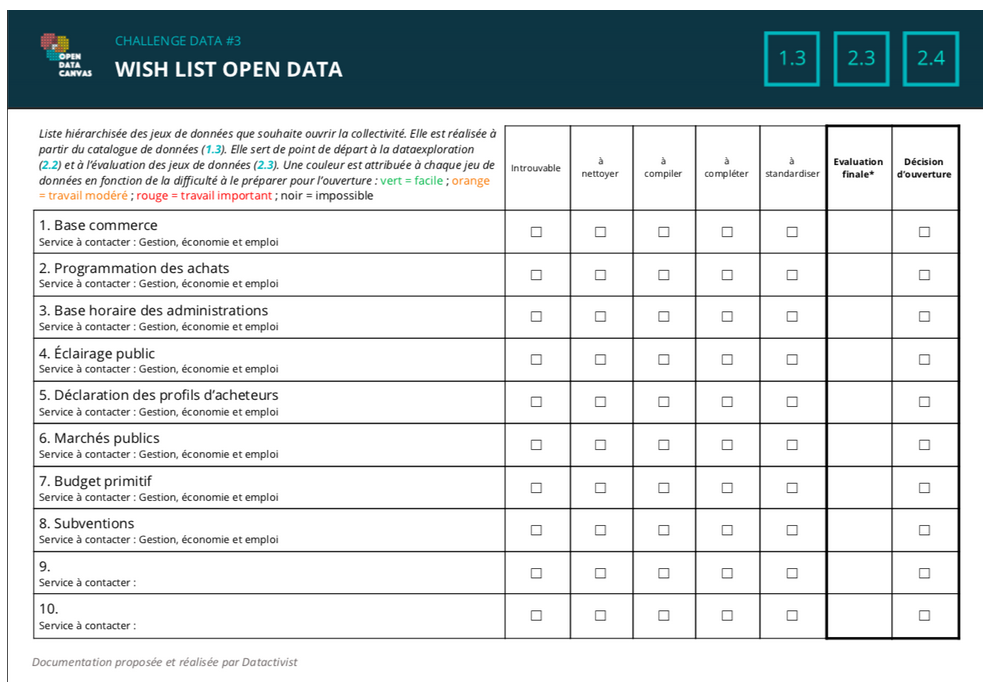
JOUR 2 – IDENTIFICATION
Cette journée de data exploration (collecte, évaluation du travail de mise en qualité nécessaire, Wanted List) a débuté par une réunion à 9h30 avec notre référent 1. Il s’est agi de discuter des difficultés rencontrées la veille (difficile établissement des prises de contact avec les services de la Métropole, ceux-ci peu/pas informés de notre projet) - et de tenter d’y remédier (renouveler ces prises de contact ; établir un dialogue en communiquant mieux, rentrer dans une démarche de pédagogie). Elle a par ailleurs affiné notre approche en précisant/rappelant quels formats de documents demander, quel vocabulaire employer, quel ton adopter. Nous lui communiquons ensuite la Wishlist et le tableau de contact des agents établis la veille afin qu’elle fluidifie et garantisse une meilleure transversalité de l’information au sein des services.
Démarche d’acculturation : Bien que la GAM soit d’un niveau de maturité open data élevé (4), nous comprenons qu’un refus ou une réticence fondé sur une “absence de besoin” (en ces termes des agents) du service contacté n’a rien d’absolu et qu’il s’agit d’expliciter l’enjeu même du partage de jeu données et des bénéfices que la communauté peut tirer de leur publication.
Nous établissons une première répartition des tâches :
- familiarisation avec les tutoriels,
- reprise de contacts avec les responsables des services de la GAM qui manipulent des données
- formalisation des documents à transmettre au référent 1.
1e acquisition de données : la Direction de l’Action Territoriale nous fait parvenir 3 jeux de données (domaine Service public et citoyenneté). Un n’est pas exploitable (rapport final d’une évaluation du projet de l’équipe juridique mobile), un n’est pas en rapport avec notre cas d’école (tableau de compilation statistiques iris 19 – 20 ; participation aux actions sociolinguistiques dans les Maisons des habitants de la Ville), et un autre ne peut être exploité que si nous parvient un jeu de données annexe (présentation COP EPC - sur les chantiers ouverts au public).
Les difficultés initiales persistent : une insuffisance de communication entre les services de la Métropole - ceux que nous contactons en mobilisent d’autres qui n’ont pas idée de l’existence du Challenge Data et de ce fait doutent de la légitimité de notre démarche - nous freine dans l’avancée de notre travail. Il est 14h, et nous ne disposons encore d’aucun jeu de données exploitable ; le retard s’accumule et le groupe commence à douter ; poursuite d’Allyson dans le Gather… nous demandons une réunion de crise !
Il nous propose de procéder autrement : en premier lieu, nous allons lister les jeux de données présents sur le site de la GAM ; puis nous allons tenter l’exploration et l’inventaire de données ouvertes publiques par d’autres sources que celles présentées par la Ville et la Métropole. Nous interrogeons le guide Datactivist ou encore le site de l’INSEE.
Si nous nous heurtons à quelques liens inactifs, inaccessibles ou obsolètes, le guide Dactactivist nous est d’une grande aide : le dernier (!) lien de la liste - geodatamine.fr, qui permet d’extraire des données géographiques d’OpenStreetMap, nous permet d’accéder à un jeu de données portant sur les aires de jeu présentes sur le territoire de communes de la Métropole. Des données portant sur ces mêmes aires de jeu, publiées sur la plateforme de la Métropole, ne concernent que la Ville ; et même si celui-ci s’avère peu complet et donc peu exploitable, c’est une première victoire - et il n’y en a pas de petites ! Cette démarche présente un intérêt en ce que la source est citoyenne, non régalienne : la proposer aux services de la Métropole peut potentiellement stimuler une démarche de leur part visant à compléter lesdites données.
Réception données budgets primitifs: le service Gestion Financière et Analyse, nous transfère un fichier de données portant sur le budget primitif 2020 de la Ville de Grenoble. Le document est en format xml., donc il ne peut être visualisé ; nous ne parvenons pas à l’exploiter. De plus, nous n’avons pas les métadonnées qui nous permettraient d’expliciter le document (“BGT_MTBUDGPREC” ? BGT_MTPROPNOUV ?) - nous espérons une réponse rapide du service.
Une seconde réunion à 15h30 avec nos référents, Arthur et Allyson nous permet de recentrer nos recherches et d’approfondir nos axes de développement. Notre référent 2 nous signale que les données portant sur les chantiers ouverts au public sont déjà publiées par la Métropole. Tensions intercommunales : la difficile obtention des données, de laquelle résulte notre paralysie, tient bien de la mésentente politique entre l’établissement intercommunal et la Ville - nous présenter à cette dernière comme relevant de la Métropole, et requérant leurs jeux de données, ne relève peut-être pas de la plus grande adresse relationnelle. Plusieurs solutions s’offrent à nous : Notre référent 2 nous propose de nous présenter, auprès des services à contacter, comme affiliés à la Ville (d’autant que le responsable par nos référents représente les 2 collectivités) ; cette stratégie n’est pas retenue pour des raisons de cohérence et nous décidons simplement d’engager plusieurs relances téléphoniques en explicitant notre projet, notre démarche, et les enjeux de notre prise de contact #diplomatie. Nous évoquons l’acquisition du jeu données portant sur les budgets primitifs : 36 heures après s’être lancés dans la course, le sourire d’Allyson, sa proposition d’ériger des statues à notre effigie si nous arrivons à faire aboutir l’exploitation de ces données, et l’enthousiasme d’Arthur pour ce sujet nous remettent en marche.
Il est 16h, nous nous attaquons à l’étape 2.1. Entre temps, un cafouillage technique lors de l’utilisation collective de Workbench déclenche le #Template Gate… le template de l’équipe de la Ville de Lens a été modifié, leurs informations remplacées par des données concernant Grenoble… c’est l’incompréhension, Grenoble plaide l’innocence.
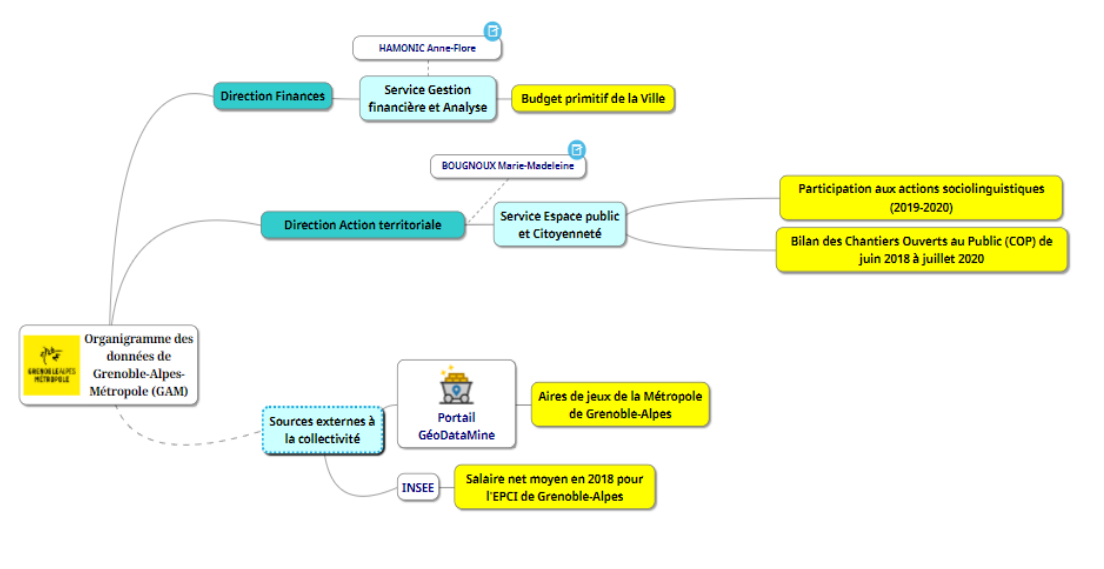
2.2 Compléter l’organigramme de la donnée
En dehors d’un imprévu technique qui a empêché la synchronisation au compte google opendata.canvas, la réalisation de la mindmup s’est, elle, avérée relativement aisée. La prise en main intuitive et presque ludique n’a pas posé de difficultés majeures pour composer l’organigramme.
Dire ce qu’on fait, c’est bien, mais dire ce qu’on n’a pas pu faire, c’est nécessaire aussi : nous avons choisi d’intégrer nos pistes de recherche externes à la collectivité à cette carte mentale, afin de rendre compte de notre parcours de recherche de manière quasiment exhaustive. Il en résulte donc un témoin assez fidèle de nos avancées du jour, laborieuses mais effectives.
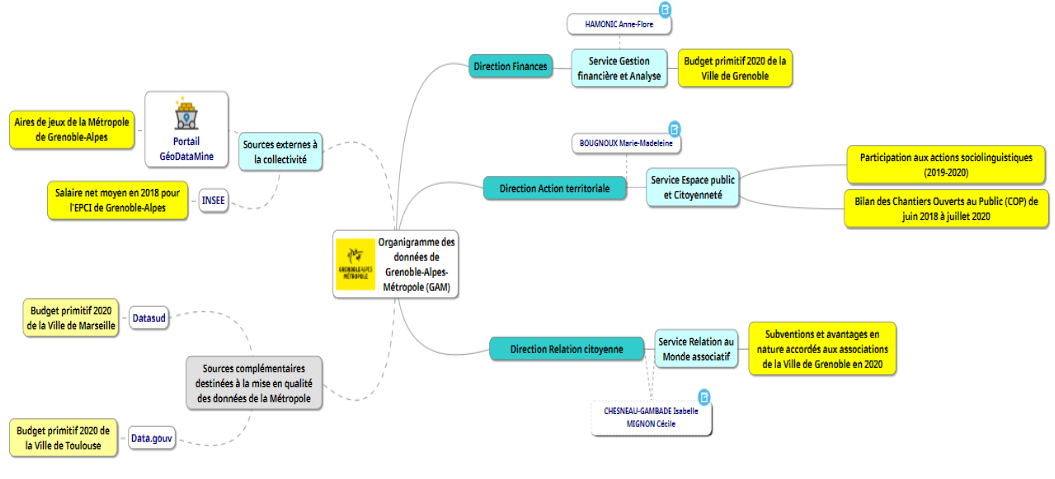
Update de l’organigramme au 19/02
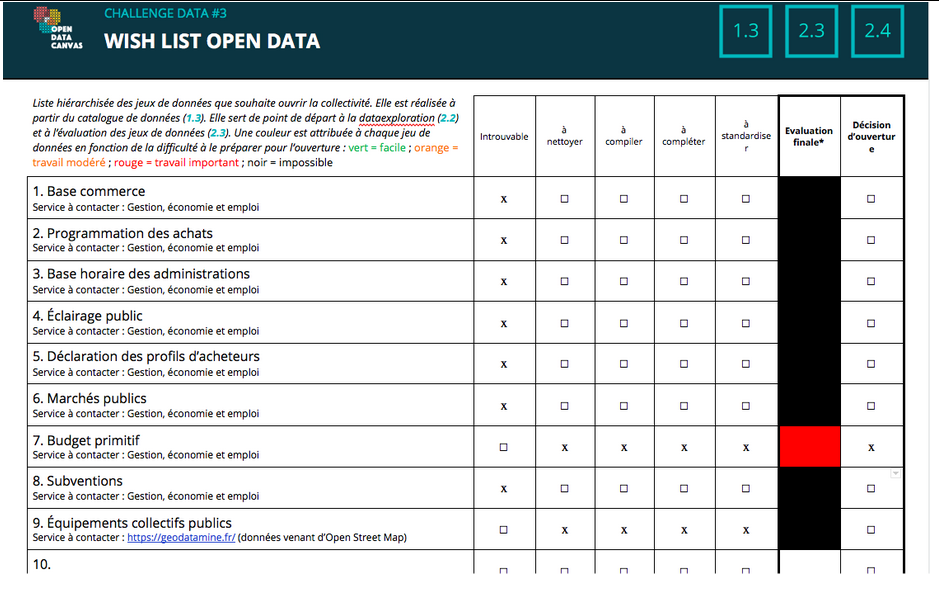
2.3 Évaluer le travail de mise en qualité
Le travail de hiérarchisation se fait plutôt facilement ; ne possédant que quelques jeux de données. L’équipe de Datactivist nous conseille de ne pas approfondir le travail portant sur les données de l’INSEE et de nous concentrer sur celles des collectivités.
Nous nous posons un certain nombre de questions pour évaluer les efforts nécessaires à la constitution définitive des jeux et les comparons aux exemples des templates qui se trouvent dans la banque de données.
Nous n’allons pas ouvrir la base portant sur les aires de jeux de la GAM, qui représenterait un engagement trop important, dépassant la semaine du Challenge. Le nettoyage semble très important : il y a notamment beaucoup de cellules vides, et la base de données n’est pas standardisée.
Quant aux données portant sur les budgets primitifs 2020 de la Ville, le document est un format .xml : nettoyer ces données relevant d’une compétence professionnelle, l’équipe de Datactivist nous propose de s’en charger.
2.4 L’engagement sur une Wanted Datalist
Bilan : cette journée fut longue, mais fructueuse. Établir une politique d’open data nécessite du temps, et ne peut aboutir sans une bonne coopération entre agents et services. (et étudiants !)
- Quelques difficultés techniques persistent : la connexion instable de notre résidence étudiante nous freine dans la pleine utilisation de Gather (pas d’image, ni de son - heureusement, nous pouvons toujours courser l’avatar d’Allyson lorsque nous avons besoin de lui !). Nous avons finalement préféré ne pas tous nous regrouper toute la journée comme ce fut le cas hier, afin d’éviter empiètement et désagrément sonore.
JOUR 3 – MISE EN QUALITÉ
Cette troisième journée était dédiée à la mise en qualité des données.
Après la réunion journalière de 9h avec Allyson, où il nous a expliqué les différentes missions de la journée, ce dernier nous a transmis un document nous libérant d’un poids et nous permettant réellement de commencer la phase d’analyse et de mise en qualité des données. Effectivement, la veille, Allyson et Arthur ont durement travaillé afin de nous aider à rendre lisible le seul jeu de données exploitables procuré par la ville de Grenoble.
C’est à partir de ce moment qu’a démarré notre recherche de métadonnées pour comprendre et pouvoir analyser correctement le document contenant des abréviations parfois peu intuitives telles que « BGT_CONTNAT », mais aussi pour savoir à quoi correspondaient certains chiffres pour lesquels il manquait la labellisation. Après une réunion avec Allyson, nous avons choisi deux pistes.
- D’un côté relancer le service financier de la ville, qui nous a donné le budget primitif sous un format non lisible afin d’obtenir plus d’explications sur le document (nous lui avions déjà demandé ces méta-données la veille mais n’avions pas obtenu de réponse).
- En attendant une réponse, tous les membres se sont familiarisés avec les tutoriels et se sont mis à chercher des budgets primitifs d’autres villes afin de pouvoir les comparer avec celui de Grenoble et mieux comprendre ce dernier.
Parallèlement, une membre du groupe s’est chargée de répondre à un tweet d’une élue qui proposait son aide à notre groupe après avoir vu un tweet d’Arthur exposant notre quête de jeux de données. La membre du groupe lui a donc envoyé un mail avec des précisions sur le challenge et une proposition d’entretien dans la journée. Ce à quoi elle a répondu favorablement en nous accordant une réunion en milieu d’après-midi.
Ensuite, la recherche de métadonnées a été mise en pause le temps d’une réunion avec notre référent 1 et notre référent 2 pour faire le point. Ils ont profité de cette occasion pour nous donner un nouveau contact susceptible de pouvoir nous obtenir un jeu de données exploitables. Plus précisément, le service urbanisme a accepté d’éventuellement nous fournir le « fichier SITADEL » comprenant les autorisations de droit des sols (update au 18.02 : au diapason de nombre de leurs collègues, le service urbanisme n’a jamais répondu à notre sollicitation. Update au 19.02 : le service urbanisme s’entête dans le silence). Allyson a cependant précisé que le groupe devait prioriser la mise en qualité du budget. Il a eu raison car la piste du service urbanisme ne donnera pas suite puisque nous n’avons pas obtenu de réponse à notre mail.
Le service Gestion financière et Analyse nous a ensuite informés de l’impossibilité de nous communiquer les données avant la fin de la semaine. Nous concentrons donc nos efforts sur la recherche de budgets primitifs d’autres villes et parvenons à trouver ceux de Toulouse et de Marseille nous permettant de comprendre quelques informations du document. Ils restent néanmoins insuffisants, la recherche se focalise donc sur l’obtention d’une nomenclature nationale.
Pendant qu’une partie du groupe a poursuivi la recherche, une autre s’est entretenue avec une élue au conseil municipal déléguée au numérique. Après nous avoir donné de nouvelles informations comme le fait que la ville de Grenoble a commencé l’open data en 2014, donc avant création de la Métropole, elle a souligné les problèmes (comme le manque de communication) entre la ville et la Métropole. Aussi, très enthousiaste par rapport au projet d’open data, elle a proposé de nous aider, notamment au niveau de l’obtention de métadonnées pour le budget primitif. Elle a également demandé à être tenue au courant lors de la publication de nos données.
Une membre du groupe a également reçu une réponse de la direction relation citoyenne. Effectivement, une personne nous a accordé un appel pour voir si elle était en mesure de nous fournir de nouveaux jeux de données sur la gestion de la vie associative. Elle n’était pas très au courant du projet, c’est pourquoi elle a posé beaucoup de questions d’une part sur l’intérêt de l’open data, et d’autre part sur le rôle de notre groupe dans le projet. Elle a contacté un collègue supposé nous fournir des données exploitables mais nous n’avons pas eu de nouvelles dans la journée, nous nous sommes donc une fois de plus concentrés sur le budget primitif.
Vers la fin de la journée, nous avons réussi à trouver une nomenclature officielle des budgets primitifs. Afin d’effectuer correctement les étapes de nettoyage et de complétion des données, nous avons contacté Arthur qui, après avoir observé nos données, nous a expliqué la marche à suivre.
Hormis quelques complications occasionnelles dues à la prise en main de Workbench, nous avons réussi à importer le document du budget primitif et à compléter la colonne vide de « BGT_CONTNAT_LABEL » grâce à l’option « refine » et aux informations de la nomenclature.
Ensuite, l’opération de traitement « drop empty columns » nous a permis de supprimer la colonne « BGT_NATURE_LABEL ». Nous avons un doute concernant l’utilité de certaines colonnes (nous demanderons l’avis des experts).
Concernant la standardisation, après vérification il nous a suffit de changer le nom de la colonne « MtRAR31112 » en « BGT_MTRAR3112 « pour que le document puisse être compris par la machine. Pour les valeurs, toutes les colonnes étaient considérées comme contenant du texte, nous avons donc transformé celles contenant des chiffres en numériques.
Bilan: La journée a une fois de plus été très chargée. La mission de mise en qualité n’a pas pu être totalement achevée. Nous n’avons pas eu le temps de procéder à l’étape de validation, d’un côté car nous avons été recontactés par différents services de la ville pour nous fournir de nouveaux jeux de données (en vain) et de l’autre car la recherche de métadonnées nous a pris beaucoup plus de temps que prévu.
Nous avons cependant réussi à bien avancer avec le jeu de données que nous possédons. Nous comptons rattraper le léger retard accumulé lors de la quatrième journée.
Workbench du premier jeu de données concernant le budget primitif : https://app.workbenchdata.com/workflows/132676
JOUR 4 – PUBLICATION
Cette quatrième journée est dédiée à la publication de nos jeux de données.
Cette nouvelle journée du #ChallengeData débute par une réunion zoom avec Allyson (9h30), durant laquelle plusieurs sujets sont évoqués. Comme évoqué précédemment, nous accusons un léger retard dans la standardisation de notre jeu de données sur le budget primitif de la Ville de Grenoble. Nous faisons ainsi part à Allyson de certaines interrogations sur la standardisation sur WorkBench, restées sans réponse la veille. Nous évoquons également la possibilité de traiter de nouveaux jeux de données, car en dépit de la grande quantité de travail fournie pour obtenir un jeu de données, nous sommes déterminés à élargir notre publication à au moins 2 jeux de données. Allyson nous fait part d’une certaine réserve et nous explique qu’il est peut-être préférable de se concentrer sur notre seul jeu de données et sur notre retard. Enfin, la question des plateformes de publication est évoquée. Nous lui faisons part de la volonté de nos interlocuteurs de publier sur la plateforme data de la métropole (URL: https://data.metropolegrenoble.fr/ ), ce à quoi il répond positivement en rappelant la nécessité de publier sur datagouv.fr.
Motivés et requinqués par notre coach, nous nous préparons à une réunion zoom avec nos référents 1 et 2, durant laquelle nous devons leur présenter notre stratégie open data.
En attendant la réunion, prévue à 10h15, nous finissons la standardisation de notre jeu de données. La principale difficulté de ce jeu de données, qui nous a occupé la veille, est une possible erreur glissée dans notre fichier workbench, erreur inhérente à la conversion de notre fichier .xml vers .cvs. Les “0” qui se trouvaient devant certains chapitres (modifiant leur nature) ont été perdus, ce qui nous a contraints à modifier une partie de la nomenclature du budget pour rajouter ce chiffre important, par exemple sur le chapitre 011, “charges à caractère général”. Cette erreur touche plusieurs “code chapitres” : 20 (ou 020) et 23 (ou 023). Nous faisons le choix de ne pas préciser la nature du chapitre 20, à cause d’une confusion entre “20” et “020” qui correspondent à deux opérations budgétaires différentes, mais qui ne se distinguent pas au sein de notre jeu de données. Pour éviter toute erreur, nous préférons laisser cela sans précision, tout comme pour le chapitre “23”- “023”. Un doute s’installe également quant au code chapitre “656” qui ne figure pas sur les sections de la liste des codes chapitres de notre document de référence, publié par un document administratif officiel. Nous comprenons rapidement que ce code, erroné, est en fait le code “6586” correspondant à “frais de fonctionnement des groupes élus”. Enfin, nous décidons, après écoute des conseils d’Allyson, de ne pas supprimer les colonnes pour lesquelles nous n’avons pas les informations correspondantes, afin de permettre aux utilisateurs qui téléchargeront par la suite le jeu de données de pouvoir ajouter ce qu’ils ont en leur possession pour compléter les informations recensées. Nous saisissons in fine un des principes de l’open data qui offre la possibilité à d’autres contributeurs de remplir les informations manquantes de notre jeu de données, qui, une fois publiée, sera réutilisable.
La réunion avec notre référent 1 et 2 débute (10h15) par zoom. Nos interlocuteurs nous incitent à reprendre contact avec une personne du service financier de la métropole afin qu’elle nous explique certaines métadonnées. Nous discutons ensuite de la stratégie de publication. Ils nous indiquent que nous aurons accès à un compte contributeur pour publier nos données sur la plateforme data de la métropole. Enfin, notre référent 1 nous indique avoir été en contact avec l’élue au conseil municipal déléguée au numérique qui a re-contacté les services financiers pour renforcer notre démarche. Le 4e jour est le bon : les différents services se coordonnent et les difficultés de communication auxquelles nous avons fait face s’effacent enfin. Notre détermination grandit de facto !
Peu après la réunion, une membre du groupe reçoit un mail de la Direction des Relations Citoyennes, avec qui un contact infructueux avait été établi depuis lundi (redirection vers d’autres services et d’autres interlocuteurs, etc.. ). À la suite d’un appel téléphonique durant lequel tous nos moyens de persuasion et d’explication de notre démarche sont avancés, nous recevons rapidement un nouveau jeu de données intitulé “subventions et avantages en nature en 2020” qui correspond aux différentes subventions et avantages accordés aux associations de la Ville. Victoire, nous avons un nouveau jeu de données, suffisamment complet pour être exploité, traité, nettoyé, compilé et standardisé ! Nous nous activons sur le traitement de ce jeu de données, conscients des délais réduits imposés. Le groupe se scinde en deux : une partie s’activera sur le traitement de ce nouveau jeu de données, l’autre partie sur la poursuite de l’étape 4 “publication”.
La mise en qualité du nouveau jeu de données prend du temps et se fait manuellement, du fait d’une incapacité à afficher sur une ligne des données disposées en colonnes. Nous souhaitons faire afficher dans notre jeu de données l’objet (locaux, évènements culturels et projets) correspondant aux avantages et subventions accordés à chaque bénéficiaire (association culturelle, sportive, sociale). Ce travail _titanesque _(près de 600 bénéficiaires) est effectué en 3 petites heures, puis il est poursuivi avec l’aide précieuse d’Arthur, qui nous offre son savoir-faire WorkBench pour finaliser la standardisation des données. Pour nous conformer au schéma de publication data, nous avons combiné “subventions projet, subventions sport et subventions fonctionnement” et avons supprimé “subventions culture”. Nous avons regroupé les aides numéraires et les aides en nature par souci de conformité. Les subventions “projet, sport et fonctionnement” sont regroupés dans la partie 2 du fichier (objet 2, montant 2 et nature 2) tandis que les avantages en nature sont regroupés dans la partie 1 du fichier (objet 1, montant 1 et nature 1).
Avant le début de l’étape 4, nous avons une réunion avec le service financier à 14h30 (zoom) qui nous explique les différentes catégories du budget (notamment la distinction entre montant prévu et montant voté) ainsi que la structure de la nomenclature comptable du budget. Il nous renvoie vers la maquette du budget publiée chaque année (un rapport sous format pdf) pour accéder à la nature des différentes opérations budgétaires. Néanmoins, si la maquette indique bien cette nature (opérations de fonctionnement ou d’investissement), les données sont inexploitables en l’état et dans le laps de temps imparti, nous ne pouvons donc pas les incorporer à notre jeu de données. Ses explications nous permettent d’envisager une nouvelle appréhension de notre lecture des données “20”-”020” et “23”-”023”. Il nous apprend que ces formalités numériques seront soumises à des réformes et qu’un flou peut exister au sein des administrations. Il nous confirme nos doutes, qu’un 0 a bien été éjecté durant les conversions de fichiers et qu’il faut “refine” certaines données pour ajouter le “0” manquant. Le fichier Budget Primitif de la Ville de Grenoble 2020 est donc prêt à la publication. Il est soumis à un test de vérification via la plateforme validata qui affirme que notre fichier ne contient pas de défauts de structure.
Nous attaquons donc l’étape 4.1 “Compléter la fiche descriptive des jeux de données” sans difficultés, du fait de notre progression dans la prise en main des logiciels proposés. Pris par le temps, nous n’avons pu publier nos jeux de données sur les plateformes mais les contacts ont été établis avec nos interlocuteurs pour lancer la publication dès demain matin. Nous avons pu échanger avec nos référents 1 et 2 au sujet de notre stratégie de communication, qui sera portée par des publications sur le site datagouv.fr et par les différents comptes de réseaux sociaux disponibles (datactivist, métropole de grenoble, ville de grenoble, Sciences Po Saint-Germain) et sur différentes plateformes (facebook, twitter, linkedin). Le second jeu de données empruntera le même processus de publication.
Bilan : Du négatif (notre retard n’a pas été entièrement comblé et nous accusons les dysfonctionnements de communication et de partage des jeux de données des 2 premiers jours) mais du positif également car nous avons récupéré un nouveau jeu de données exploitables et standardisé, nous avons amélioré notre maîtrise des outils mis à notre disposition (workbench, excel, validata), nous avons approfondi nos connaissances sur les métadonnées et les enjeux de données dans les collectivités territoriales et enfin nous avons poursuivi nos échanges avec nos coaches et interlocuteurs, nous permettant de mieux comprendre et saisir les enjeux de ce #ChallengeData !!
Subventions et avantages en nature accordées aux associations par la Ville de Grenoble en 2020 : https://data.metropolegrenoble.fr/ckan/dataset/subventions-et-avantages-en-nature-accordees-aux-associations-par-la-ville-de-grenoble-en-2020
Budget primitif de la Ville de Grenoble pour 2020 : https://data.metropolegrenoble.fr/ckan/dataset/budget-primitif-de-la-ville-de-grenoble-pour-2020
JOUR 5 – VALORISATION
En dépit des obstacles rencontrés sur le chemin, cette cinquième journée est placée sous le signe de la valorisation: des données, de nos efforts, de la posture de père, de mère et de mentor qu’Allyson a incarné pour notre équipe tout au long de la semaine.
1. Volonté de rattraper notre retard et constat des difficultés
Au regard du retard accumulé depuis lundi, notre priorité consiste en réalité à publier nos deux jeux de données au plus vite, afin de consacrer la plus grande partie de la journée à leur mise en valeur. Pour discuter de cette étape et des suivantes, nous avons rendez-vous à 10h15 avec nos référents. Le temps de latence avant cette entrevue nous permet de prendre connaissance des tutoriels du jour et de compléter l’organigramme de données avec celles obtenues et traitées en quatrième vitesse la veille - Arthur, ces données te doivent beaucoup.
A noter que l’absence d’interaction avec Allyson pour lancer la journée se fait ressentir. Outre les difficultés de concentration liées au travail en distanciel qui pèsent beaucoup sur notre état d’esprit, nous connaissons également quelques difficultés à surmonter fatigue et découragement collectif après la réunion avec nos interlocuteurs de la Métropole. De fait, malgré leur cordialité et leur bonne humeur constante, nos référents 1 et 2 ne se montrent pas d’une grande précision quant à la forme qu’ils souhaitent voir prendre à leur plan de communication. Nous signalant d’abord que le responsable du service dédié est en congé, ils expliquent ensuite de manière assez vague qu’ils envisagent de communiquer sur le site de la métropole et sur Twitter, sans nous donner davantage d’indications sur leurs attentes, malgré nos relances. Malheureusement, ce qui leur semble liberté, confiance et marge de manœuvre, se traduit pour nous en hésitations et incertitudes.
Il convient également de revenir sur la seconde difficulté née de cette réunion. Notre référent 1, à qui nous avons envoyé avant la réunion le deuxième jeu de données traité, émet des réserves sur la possibilité de le publier tel quel. Pour rappel, celui-ci contient, rassemblés en un même tableau, le compte-rendu des subventions et des avantages en nature accordés aux associations par la Ville de Grenoble en 2020. Dans la mesure où ces mêmes informations pour les années 2013 à 2016 sont publiées séparément sur le site d’open data de la Métropole de Grenoble, notre interlocutrice considère qu’un critère de cohérence et de logique exige que nos données soient remaniées pour être publiées de la même façon, en deux tableaux différents. Sachant bien qu’il nous reste peu de temps avant la fin du challenge, elle nous conseille donc - bien évidemment sans penser à mal - de nous concentrer sur l’autre jeu de données en abandonnant la piste des subventions aux associations.
Cette possibilité nous paraît inconcevable après le temps et les efforts consacrés la veille à traiter ces données dans les temps. Étant déjà largement en retard, nous ne pouvons pas nous permettre de retraiter ces données. Nous tirons donc de son propos la conviction que notre seule chance de publier ce deuxième jeu est de convaincre notre référent 1 qu’il est parfaitement exploitable en l’état.
Suite à cette réunion, branle-bas de combat : nous contactons Allyson pour convoquer une cellule de crise. Bientôt rejoint par Arthur, il nous explique que notre argument majeur dans cette affaire est l’exigence de conformité aux standards de l’open data. En réponse aux interrogations de notre référent 1 sur le bilan des traitements réalisés sur ces données, décision est donc prise de rédiger un long mail explicatif pour détailler tout l’intérêt que présente cette mise en qualité en termes de transparence et de légalité. Envoyé aux alentours de 13h30, ce mail ne connaîtra malheureusement jamais de réponse.
En parallèle se joue un drame : sur le point de publier les données du Budget primitif 2020 de la Ville de Grenoble sur le site open data de la Métropole, nous nous avisons de l’impossibilité d’achever cette manœuvre. Bien que notre référent 2 nous ait assuré avoir autorisé notre compte à publier ces données, il n’en est rien. Autrement dit, nous sommes vendredi midi et nous n’avons toujours aucun jeu de données publié. Un membre de notre groupe s’empresse de l’en prévenir par mail, et commence alors la seconde partie de la journée. Pressés par le temps, nous devons réaliser en 5h ce que les autres groupes ont fait en 14h.
2. Passion, fièvre et excès : la publication et la valorisation des données
Scindant une nouvelle fois le groupe, nous nous attelons à des tâches différentes :
- efforts de persuasion pour obtenir la publication des subventions associatives sur un seul fichier
- Etude du plan de communication relatif aux deux jeux de données
- Travail de mise en valeur du budget primitif de la Ville par la visualisation
- Tentative de mise en valeur des subventions associatives par la visualisation
L’élaboration du plan de communication n’a pas été tâche facile. Déjà évoquée le jeudi après-midi, cette thématique est finalement repoussée au point du vendredi matin par nos interlocuteurs. Les orientations larges et vagues qu’ils évoquent nous placent face à la problématique suivante : confrontés à un template (produit par Datactivist) très fourni, très détaillé et ambitieux, nous ne disposons pas des attentes et des capacités de la Métropole. Face au relatif désintérêt et au manque d’information que nous avons ressenti de la part de nos interlocuteurs, nous optons donc pour une présentation simple de nos objectifs, stratégies et réseaux mobilisés, en dehors du cadre prévu par le template. Puisque la Métropole de Grenoble-Alpes est déjà bien armée (compte Twitter dédié à la publication de données ouvertes et base de données relatives à la Ville et la Métropole), la meilleure manière de présenter la communication nous semble être de la centraliser, dans un souci de cohérence et d’efficacité, en usant des techniques déjà pensées par leur service. Si nous n’avons pas débordé de créativité dans notre projet de communication, l’ensemble des discussions liées à nos incertitudes en la matière ont considérablement rallongé le temps de l’opération, qui nous a occupé plus du double du temps nécessaire. Voici en pdf le document final détaillant le plan de communication sur les données ouvertes de la Métropole :
https://drive.google.com/file/d/1zRzVncBv4eRYSU_UdT140v88u_Lsv2yJ/view?usp=sharing
En parallèle à ces réflexions, notre référent 2 parvient finalement à autoriser la publication des données en .json et .csv aux alentours de 14h. Malgré de nombreuses difficultés de format et d’URL, nous sommes à nouveau dans la course et réussissons finalement à publier les données relatives au budget primitif de la Ville un peu après 15h. Commence alors le travail de visualisation des données, tandis que nous n’avons toujours pas obtenu l’autorisation de publier le second jeu de données sur les subventions accordées aux associations. C’est un appel téléphonique au responsable de nos référents, qui réglera sobrement la question vers 17h. Puisque les données de subventions sont publiées (en pdf) dans un seul et même tableau sur le site de la Ville de Grenoble, nous avons le feu vert. Nous publions les données liées aux subventions dans la dernière demi-heure du challenge data, exténués mais apaisés.
Parmi les obstacles rencontrés lors de cette cinquième journée, le travail de visualisation des données est probablement celui qui s’est avéré le plus laborieux à surmonter, d’autant qu’il nous a été parfaitement impossible de contacter la facilitatrice graphique pour obtenir son aide.
En premier lieu, la plupart des plateformes proposées semblent payantes ou très limitées, et notre préférence se porte sur l’outil RAWGraphs. Nous nous orientons ensuite rapidement vers le choix d’une carte proportionnelle (ou treemap) pour traduire visuellement nos données relatives au budget primitif. Cependant, le constat initial est le suivant : notre datavisualisation est imparfaite. En effet, la répartition du budget est illustrée en fonction de trois types de données : de l’article du budget qui indique la couleur du carré (BGT_CONTNAT), le libellé de l’article qui correspond au titre du carré (BGT_CONTNAT_LABEL), et le montant de la dépense associée qui définit la taille du carré. (BGT_MTPREV) . Or certains chapitres correspondent à des montants nuls ou ridiculement faibles par rapport aux autres. La conséquence visuelle directe de cette différence est un écart de taille trop inégal entre les carrés pour ne pas nuire à la clarté de la datavisualisation. Nous décidons donc de créer un nouveau label d’article “Autre” pour recouvrir les articles aux montants trop faibles pour apparaître en tant que tels sur le visuel. Il est évidemment inenvisageable d’opérer ces modifications directement sur la base de données initiale, qui répond à une convention standardisée et a vocation à demeurer structurée exactement comme elle l’est. Nous créons donc un second document, sur lequel nous trions les dépenses par articles, cumulons ces dépenses et ces recettes, puis sélections et rassemblons les articles aux montants les plus faibles sous le nom “Autre”, avec un libellé associé changé en 0. Traduites en datavisualisation, ces manipulations permettent d’améliorer grandement la lisibilité de la carte proportionnelle en supprimant les superpositions de titres. Ainsi optimisée, nous publions finalement cette datavisualisation à la suite du jeu de données en guise d’exemple de réutilisation, toujours dans une démarche de pédagogie autour de l’open data.
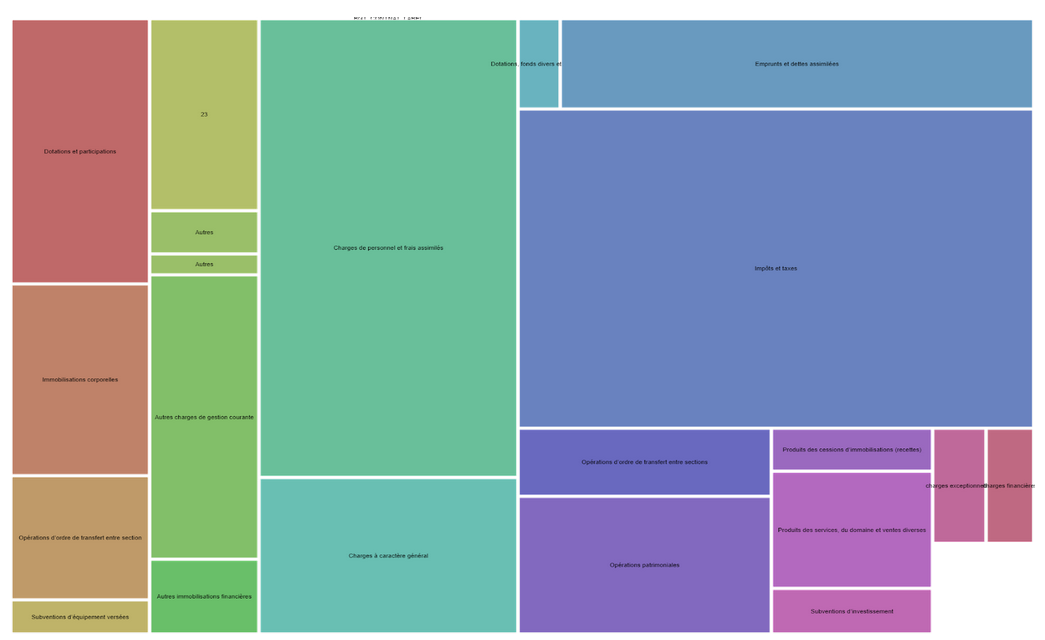
Toute cette démarche ayant pris un temps considérable et mobilisé toute notre attention, nous avons préféré ne pas nous aventurer à tenter une datavisualisation des données relatives aux subventions. Disperser nos efforts aurait risqué de nous conduire à deux impasses, au lieu d’une réussite.
Bilan : Cette dernière journée s’est déroulée dans un climat de fatigue et de stress, lié à l’échéance proche, la conscience de notre retard et le sentiment que nos interlocuteurs n’étaient pas pleinement disponibles pour nous aider à mener à bien notre défi. Décrire cette journée de manière chronologique n’était pas aisé, dans la mesure où nous avons fait face à des problématiques croisées et simultanées, en fonction du différent niveau d’avancement des processus de publication. Heureusement ponctuellement éclairée par la jovialité d’Allyson, cette atmosphère ne nous a cependant pas empêché de réaliser une belle revanche sur notre malus initial, en publiant nos deux jeux de données reçus tardivement.
CONCLUSION
Nous sommes fiers, honorés et reconnaissants d’avoir pu ouvrir deux jeux de données à l’issue de cette semaine du Data Challenge !
Chaque publication a le goût de l’ouvrage achevé, de l’effort récompensé, de la coopération magnifiée. Nous sommes surtout heureux d’avoir pu ouvrir deux jeux de données en réalité assez complémentaires, et surtout essentiels à l’échelle d’une collectivité : le budget primitif pour l’année 2020, qui retrace les recettes et les dépenses prévues pour l’année, et les subventions versées aux associations, qui vient préciser ces dépenses de la municipalité pour dynamiser le tissu associatif local.
Cette joie qui nous emporte n’est pas seulement liée au plaisir que nous avons pris à travailler pendant toute la semaine avec Allyson et sa bonne humeur communicative (et avec Arthur dont l’aide nous a aussi été précieuse), mais bien aux difficultés que nous avons dû surmonter pour parvenir à l’ouverture de ces jeux de données.
Tout d’abord, nous ne pouvons que souligner la distance entre la bonne volonté et la disponibilité de nos référents 1 et 2, et l’accueil que nous avons reçu de la part du reste des services de la Ville et de la Métropole. La communication assez catastrophique entre les différents services, le manque d’informations des services par rapport à notre initiative et les rivalités entre la Ville et la Métropole expliquent largement les difficultés majeures que nous avons rencontrées pour récupérer des jeux de données exploitables. Nos interlocuteurs ne pouvaient certes pas tout résoudre, mais ont été bienveillants avec nous, malgré les difficultés et quelques limites de leur part (notamment sur leur réactivité le dernier jour, qui a entraîné un retard et une pression dommageable sur la publication de notre deuxième jeu de données).
Nous tenons également à souligner une certaine difficulté, voire une certaine charge mentale et intellectuelle face à la situation qui a été la nôtre lundi matin : à 9h, nous avons reçu un briefing général, à 9h45 nous étions face à des agents territoriaux qui travaillent depuis de nombreuses années dans le domaine de l’open data, alors que nous étions pour la plupart incapables d’expliquer des notions de bases du sujet- ce qui impacte quelque peu notre confiance en nous et notre légitimité à demander des jeux de données. Une journée de formation préalable, nous permettant d’appréhender le vocabulaire, les processus et les techniques à l’oeuvre nous aurait peut-être permis d’entamer cette semaine avec moins d’appréhension, et de se sentir plus légitimes à intervenir.
Néanmoins, ces difficultés ont été oubliées, surmontées, piétinées grâce à la qualité de notre travail en équipe et de l’encadrement dont nous avons bénéficiés. La précision et la pédagogie des tutoriels ainsi que des ressources mises à notre disposition nous ont permis de prendre en main assez facilement les différentes tâches, malgré des temps d’adaptation inévitables (certains d’entre nous ayant pu développer une relation passive-agressive avec certains logiciels de traitement de données). Ce qui ressort des différents avis des membres de l’équipe, c’est d’abord l’expérience professionnalisante et formatrice qu’a représenté cette semaine. La prise en main de logiciels jusqu’alors inconnus, la découverte des enjeux multiples et primordiaux liés à l’open data et à la transparence de l’action publique, et enfin l’aspect _concret _des obstacles et de leurs solutions nous ont beaucoup appris, et nous ont fait prendre conscience de l’ampleur de la tâche que représente l’ouverture des données des personnes publiques. Là où nous constatons une rupture avec l’enseignement de Sciences Po par ce côté très concret, très pratique de nos activités, nous avons également observé une complémentarité stimulante entre cet enseignement et notre action concrète : nos connaissances dans l’organisation des collectivités territoriales et des finances publiques nous ont ainsi beaucoup aidé. De plus, nous sommes passés de “l’autre côté de l’écran” : étudier en cours les contraintes du “mille-feuilles administratif” français est une chose, se heurter concrètement aux difficultés politiques et techniques entre une grande ville et une métropole en est une autre.
L’accomplissement de ce projet n’aurait été évidemment pas possible sans l’encadrement des experts de Datactivist, mais ce n’est pas ce qui nous a le plus marqué : nous traversons honnêtement tous une période difficile, et la perspective de passer 9h devant un écran en distanciel pendant cinq jours pour ouvrir des jeux de données n’était pas notre programme initial pour cette semaine à cheval entre nos partiels, nos vacances et notre stage. Pourtant, il a été très simple de changer d’état d’esprit dans un environnement de travail aussi positif, avec une volonté de s’entraider et de réussir qui était communicative, et avec une équipe qui a travaillé avec autant de détermination pour que nous puissions passer cette semaine dans les meilleures conditions. Nous avons ri, nous avons un peu pleuré, nous avons beaucoup essayé, mais nous avons traité, nous avons visualisé, et nous avons publié !
C’est ainsi que nous choisissons assez naturellement la publication des données sur le portail de l’open data de la Métropole comme la plus belle réussite de cette semaine, et ce moment précis, à 15h22 ce vendredi 19 février, où nous avons contemplé notre magnifique page de présentation du jeu de données sur la page de l’Open Data de la Métropole.
Et, après un vote à l’unanimité, nous avons désigné nos multiples rejets par les services de la ville pour accéder aux jeux de données comme le plus gros casse-tête de la semaine, la liste de nos refus étant plus longue mardi après-midi que le nombre de lignes dans le budget primitif de Grenoble (soit 1 600 lignes pour les amateurs du détail). Ces refus devancent la “connexion à l’espace Gather”, source de nombreux troubles de l’humeur chez tous les membres de l’équipe : la frustration de ne pas voir ni entendre, ou l’un sans l’autre, ou bien être entendu sans le vouloir, rien n’a été facile.
Malgré, mais surtout grâce à tout cela, cette semaine du Challenge Data restera une belle aventure pour chacun d’entre nous, et nous en sommes sincèrement ravis.