Carnet de bord de l’ouverture des données de Baugé-En-Anjou
par Lyna B., Thomas Delaunay, Mia F., Mathilde Gambe, Jean-Etienne Lemelle et Agathe Mazars

JOUR 1 – DIAGNOSTIC
Baugé-en-Anjou est une commune située dans le département de Maine-et-Loire dans les Pays de la Loire. Elle est peuplée de 12100 habitants en 2021 (dernier chiffre communiqués par les élus), et a à sa tête l’avocat Philippe Chalopin depuis 2013. Baugé-en-Anjou est un regroupement de quinze communes, né en 2013, puis refondu en 2016.
Nous avons commencé par collecter des informations sur la commune dont nous sommes en charge, puis par prendre connaissance du site de l’Open Data. Notre interlocuteur pour la commune est un adjoint au Maire, avec qui nous avions rendez-vous à 15h. Nous avions eu deux informations différentes sur l’heure de début : 15h et 15h30. Deux interlocuteurs nous ont rejoint à 15h, mais nous avons dû attendre que tout le monde rejoigne la plateforme à 15h30 afin de commencer la réunion. C’était l’occasion pour nous de discuter plus amplement avec notre interlocuteur et un responsable informatique sur la commune et notre IEP. Il semblait que plusieurs rendez-vous étaient fixés à cette heure, et nous avons donc eu des difficultés à accueillir nos intervenants car le carré jaune d’accueil était saturé.
Une fois tout le monde réuni, nous avons pu faire la connaissance de tous les membres présents. Durant cet entretien, plusieurs intervenants étaient en fait présents : d’abord donc notre interlocuteur (adjoint au maire), un responsable informatique, un responsable communication, une Directrice pôle environnement, une Directrice générale des services et Julia de Datactivist. Après avoir fait un tour de table des présentations, nous avons exposé les objectifs de ce Challenge Data. En effet, nos interlocuteurs n’avaient pas tous l’air ni très informés, ni très convaincus du but de l’ouverture de leurs données. Nous leur avons donc demandé quels étaient leurs freins, et à l’inverse leurs motivations à participer à ce challenge. Ils nous ont répondu qu’ils étaient enthousiastes à l’idée d’exploiter des données froides, qui ne sont pour l’instant pas beaucoup exploitées, afin de connaître plus amplement leur population. Il est intéressant de noter qu’à cette question, la DGS a tout de suite répondu “notre interlocuteur” comme principal porteur du projet. En ce qui concerne les freins, les élus nous expliquent que Baugé-en-Anjou étant une commune nouvelle récente, ils n’avaient pas vraiment eu le temps de se pencher sur la question. Nous avons donc commencé par leur soumettre les questions du questionnaire, que nous nous étions réparties en amont afin d’en comprendre tout le vocabulaire. La commune de Baugé-en-Anjou à un niveau 3 de maturité Open Data, ce qui est pour nous un grand terrain d’exploration. Nous leur avons ensuite demandé s’ils avaient déjà des idées des thèmes qu’ils souhaiteraient traiter. Le nombre de participants étant très élevé, tous n’étaient pas d’accord sur le choix des thématiques, ainsi que sur l’ordre de préférence. Nous avons abordé beaucoup de sujets, dont beaucoup leur paraissaient intéressants, mais dont également les élus ignoraient s’ils avaient accès aux bases de données ou si la quantité était suffisante. Le diagnostic a donc été très large : nous avons abordé toutes les thématiques présentes dans le catalogue de jeux de données. A l’issue de cette réunion, nous avons pu dégager onze thèmes correspondant à un jeu de données, mais nous n’avons pas pu les hiérarchiser. En effet, tous les élus ont réussi à s’accorder sur le choix des thèmes, mais ont relevé l’importance de la décision du Maire de Baugé-en-Anjou pour les valider et les hiérarchiser. Un conseil municipal se tenant le soir même, la DGS nous a indiqué qu’elle soumettrait la liste établie au Maire, et nous communiquerait au plus vite la wishlist hiérarchisée.
Nous sommes donc tous très enthousiastes à l’idée de concrétiser ce projet, mais n’avons pour l’instant aucune certitude sur les choix de la commune. Nous sommes dans l’attente de la réponse de la DGS afin de pouvoir commencer à rechercher les données exploitables à partir de demain. C’est une difficulté et une source d’inquiétude pour notre groupe : la DGS a tenu à ce qu’elle centralise nos demandes, et non pas à ce que nous contactions nous mêmes les services concernés. Ce n’est pas un problème en soi, et pourrait même paraître plus simple, cependant la DGS nous a indiqué être absente demain, mardi. Nous espérons donc qu’elle puisse nous envoyer au plus vite la wishlist finalisée afin que nous puissions commencer nos recherches.
Voici, à ce jour, les thèmes que nous avons relevés et que nous avons récapitulés par mail à notre référent :
- Budget primitif : autorisations de programmes et crédits de paiements
- Marchés publics : critères sociaux/environnementaux
- Marchés publics : critères de genre et de promotions
- Associations
- Espaces verts : arbres
- Etablissements d’accueil petite enfance et écoles
- Actes d’état civil
- Prénoms des nouveaux nés
- Monuments historiques : petit patrimoine
- Eclairage public
- Médiathèque
JOUR 2 – IDENTIFICATION
2.1 Exploration à la recherche de données
Ce matin, nous sommes repartis de la réponse de la Direction Générale des Services, que nous avons reçue hier soir, après la fin de la première journée. Elle nous y avait communiqué la hiérarchie des jeux de données possiblement ouvrables ainsi que les coordonnées des services à contacter pour obtenir ces données. Nous avons fixé une réunion avec notre interlocuteur, adjoint au Maire de Baugé-en-Anjou, afin de lui présenter à 16h30 le choix des jeux de données que nous pouvions retenir pour l’ouverture. Nous avons envoyé des courriels aux différents services et personnes pour lesquels la DGS nous avait fourni des contacts. Nous avons fait face à quelques difficultés durant cette étape. La DGS était absente ce jour-là, mardi 16 février. Autre difficulté rencontrée, les premiers services à nous communiquer des données ne nous ont pas fourni le fichier ou document complémentaire pour comprendre les données choisies (sigles, abréviations etc.).
Notre recherche a porté sur les dix jeux de données que souhaite ouvrir Baugé-en-Anjou qui sont, selon l’ordre hiérarchisé (du plus au moins souhaité) : le budget primitif (budget d’investissement), les espaces verts (E.V.) (espaces verts et arbres urbains), l’éclairage public, les monuments historiques, les marchés publics (critères sociaux/environnementaux), les subventions (associations), les usagers de la médiathèque, les établissements d’accueil de la petite enfance (écoles), les actes d’état civil et les prénoms des nouveaux-nés.
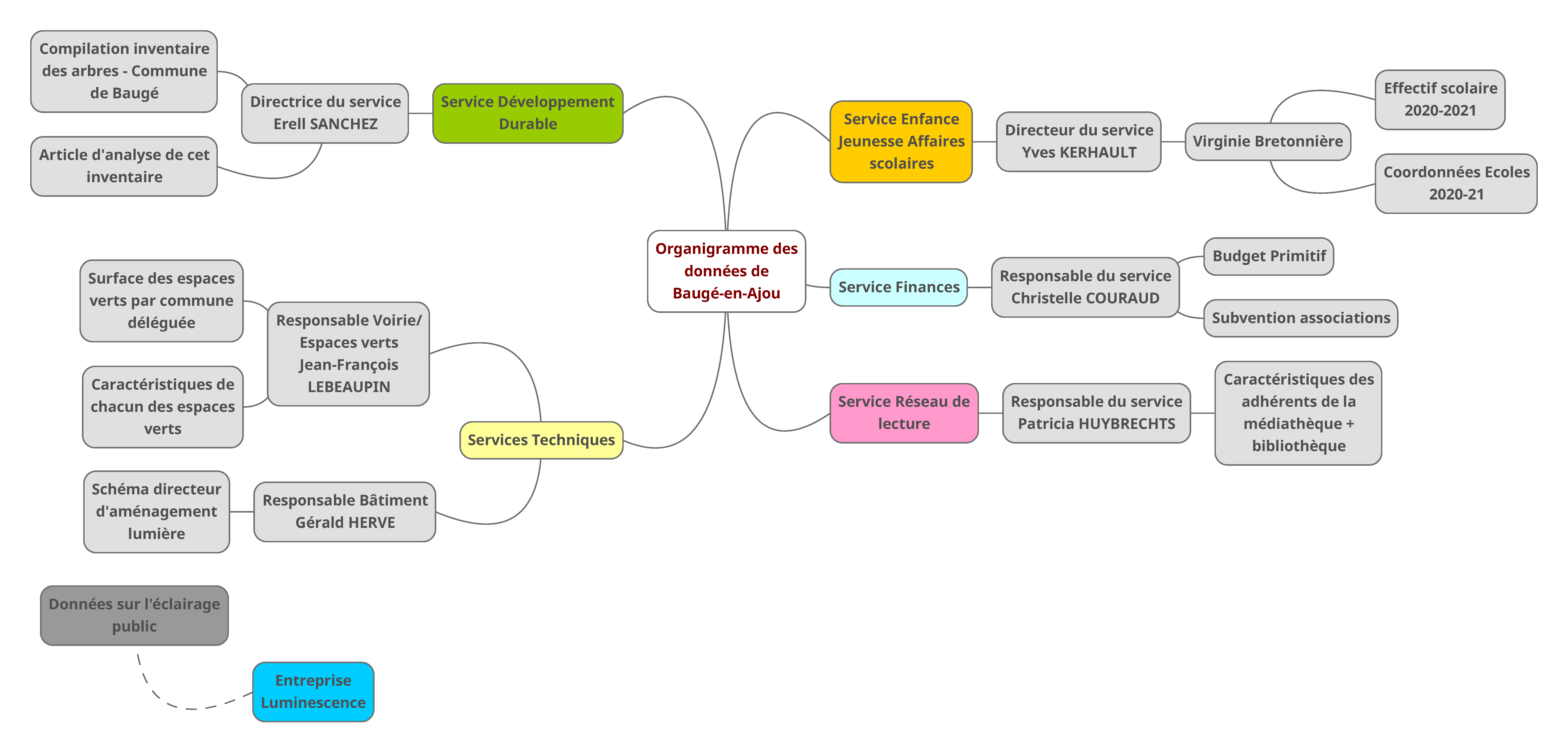
2.2 Compléter l’organigramme de la donnée
Nous avons constitué cet organigramme des données avec une carte mentale. Cette carte mentale permet de savoir vers quel service et quelle personne se tourner pour pouvoir avoir accès à tel ou tel jeu de données. Après avoir créé de grandes catégories pour indiquer les services, nous avons ajouté d’autres données sur les branches comme les noms des responsables présents au sein d’une direction, en plus du nom du directeur ou de la directrice de cette direction. La DGS nous avait fourni les adresses courriels de toutes les personnes à contacter pour obtenir ces jeux de données, ce qui a permis de réaliser cet organigramme relativement facilement. Nous n’avons pas éprouvé de difficulté particulière à constituer l’organigramme.
2.3 Évaluer le travail de mise en qualité
Pour chaque jeu de données transmis, nous avons évalué le travail à fournir pour les quatre étapes suivantes : le travail de nettoyage (supprimer les cases, lignes, colonnes vides et toutes les données inutiles) de compilation (compiler plusieurs fichiers de données entre eux pour ne former qu’un seul jeu de données), de complétion (compléter les données manquantes) et de standardisation (réécrire les données qui ne correspondent pas à l’écriture standard).
La personne responsable du budget primitif (budget d’investissement) nous a envoyé des données sur ce sujet. Les données récupérées sur le budget primitif (budget d’investissement) ont donné lieu à une évaluation relativement fine des efforts à fournir pour pouvoir les exploiter. Les tableaux Excel récupérés présentaient un nombre important de cases et de colonnes vides. Lorsque nous avons voulu télécharger le fichier sur Workbench, celui-ci s’est révélé incompatible. Pour pouvoir contourner cette difficulté, il a été nécessaire de refaire la mise en page de manière approfondie. Certaines cellules avaient par exemple été fusionnées ; il a fallu les défusionner. Ces fichiers ont également donné lieu à des problèmes de compréhension. Nous ne savions pas à quoi correspondaient certaines entrées. Il a été nécessaire de contacter la commune afin de comprendre le sens de certains sigles ou abréviations. Cependant, il n’a pas été possible de se procurer de document explicatif. Une fois toutes ces difficultés mises à l’écart, ce jeu de données paraissait facilement ouvrable, c’est pourquoi il a été classé en vert.
Concernant les espaces verts (espaces verts et arbres urbains), on nous a envoyé deux contacts, ceux du service Voirie/Espaces verts des Services techniques de la Ville, et du Service Développement durable de la Ville. On nous a envoyé une compilation de l’inventaire des arbres de la Ville. On nous a aussi envoyé un fichier portant sur la répartition et les caractéristiques des espaces verts de la Ville. Nous avions donc deux bases de données différentes à traiter, ce qui a nécessité que nous réfléchissions sur la pertinence relative de l’une ou de l’autre - s’il fallait n’en garder qu’une ou décider de retenir les deux pour l’étape postérieure. Ces deux jeux de données paraissaient facilement ouvrables au regard des critères des quatre étapes évoquées. Peu d’informations manquaient et ces jeux de données ne nécessiteraient pas de grandes modifications pour être publiables. Ils ont donc été classés en vert.
Concernant l’éclairage public, qui correspond au troisième choix de la commune, les données récupérées étaient littérales (document pdf). Il s’agissait de données textuelles et difficiles à retranscrire dans des tableaux Excel. Cela est lié au fait que la commune est passée par une entreprise privée - Luminescence - pour produire les données concernant son éclairage public. Une personne du service Bâtiment des Services techniques de la Ville, nous a fourni le contact de Luminescence pour nous procurer les données exploitables. Cependant, nous n’avons eu aucune réponse de la part de cette entreprise. C’est pourquoi, dans l’attente de cette réponse ce jour-là - notre interlocuteur nous a dit qu’il tenterait de nous faire transmettre ce jeu de données -, nous avons classé ce jeu en rouge (réponse de la commune mais incertitude quant au fait de pouvoir se procurer les données, bien que ce jeu de données soit parmi les thématiques prioritaires de la Ville).
Concernant les marchés publics (critères sociaux/environnementaux), nous avons contacté la responsable de ce sujet sur la commune. La réponse que nous avons eue a été un peu tardive (très peu de temps avant la réunion de présentation à la commune de notre évaluation des jeux de données), c’est pourquoi il aurait été difficile d’évaluer ces données. Nous avons donc laissé de côté cette thématique et avons classé ce jeu de données en noir (aucune réponse ou réponse trop tardive).
Concernant les monuments historiques, nous avons contacté un membre de la conception et de la réalisation des constructions et des espaces publics. Cependant, nous n’avons pas eu de réponse. C’est pourquoi nous avons classé ce jeu de données en noir (aucune réponse).
Concernant les subventions aux associations, une responsable du Service Finances a été très réactive pour nous envoyer ces données. Plusieurs cases et colonnes étaient vides, il y avait certains problèmes de ponctuation. Pour les subventions, il y avait un problème de forme au niveau des données. Cependant, de manière générale, ce jeu de données a été classé en vert, donc facile à mettre en qualité pour être publié et exploité.
Concernant les usagers de la médiathèque, nous avons réussi à avoir un contact direct au téléphone avec une personne du Service Réseau de lecture. Cette dernière a été très disponible ce qui nous a permis d’avoir rapidement des données sur les usagers de la médiathèque. Ces données étaient déjà bien organisées et ne nécessiteraient pas de grands efforts pour être mises en qualité. Ce jeu a donc été classé en vert.
Concernant les établissements d’accueil de la petite enfance (écoles), nous avons réussi à avoir des réponses rapides grâce au directeur du Service Enfance, Jeunesse, Affaires scolaires. La commune nous a rapidement fourni des données et a bien compris nos demandes. Une difficulté est à relever. Nous nous sommes demandés s’il était nécessaire de séparer les classes regroupées dans les écoles dans cette commune pour pouvoir comparer les données des communes déléguées entre elles. En effet, selon les communes, certaines classes ne sont pas regroupées de la même façon (CE1-CE2 ou CE2-CM1 par exemple). Après consultation des coachs, nous avons pensé qu’il serait préférable de séparer les élèves selon leur niveau plutôt que de garder les regroupements de classes des écoles, ce afin de pouvoir comparer les élèves des différentes communes déléguées entre eux. Il était parfois difficile de savoir comment formater et quel était le bon standard pour les données. C’est pourquoi ce jeu de données a été classé en orange, plus difficile à mettre en qualité pour être publié et exploité.
Concernant les actes d’état civil et les prénoms des nouveaux-nés, nous avons contacté la personne responsable de l’état civil, du cimetière et des associations de la Ville. Elle nous a fourni des données sur ces deux sujets. Concernant les actes d’état civil, les données récupérées, pour être exploitées, nécessitaient d’être compilées. De même, pour les prénoms des nouveaux-nés, les données étaient difficilement exploitables car il aurait été nécessaire de fournir un travail de compilation conséquent. En effet, pour les deux jeux de données, les données étaient répertoriées par commune déléguée. Baugé-en-Anjou étant composé de quinze communes déléguées, il aurait été nécessaire de compiler les données de ces quinze fichiers ou pages pour pouvoir obtenir un seul fichier des données pour chaque jeu pour Baugé-en-Anjou. De plus, il aurait fallu ensuite retravailler de manière conséquente la forme du fichier final pour le nettoyer, le compléter et le standardiser. C’est pourquoi ces deux jeux de données ont été classés en orange.
Les coachs ont été très réactifs pour répondre à nos questions, ce qui nous a permis d’avancer rapidement.
En tant que novices en traitement de données, il a parfois été difficile de trouver des solutions quand on ne connaît pas bien les contraintes. Il a parfois été difficile de rentrer dans le “raisonnement des données” ; nous avions l’impression de découvrir.
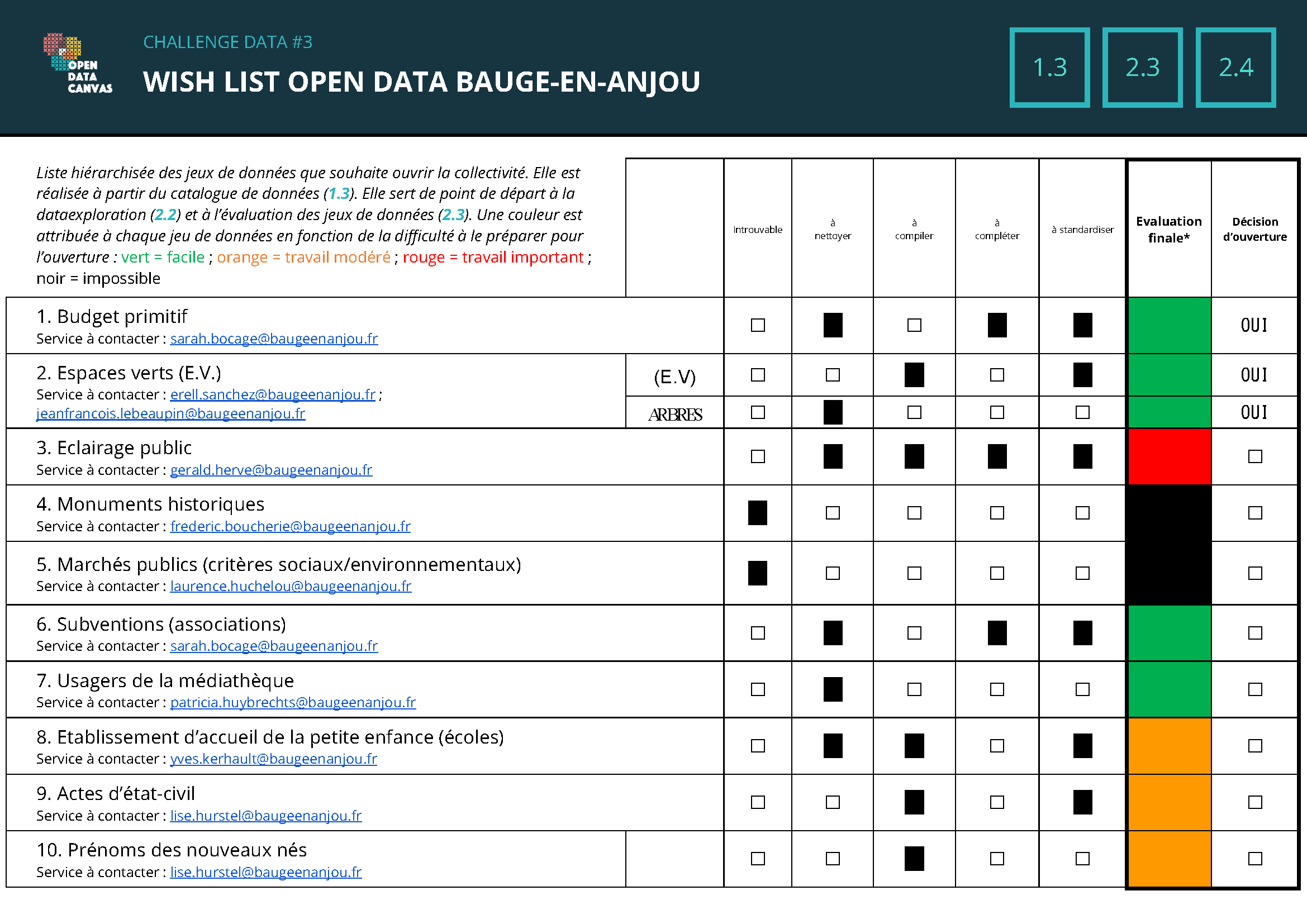
2.4 S’engager sur une wanted data list
Après avoir fait ce travail d’évaluation des données, nous avons constitué une Wanted Data List. Sur ce document, nous avons indiqué par un code couleur le niveau de difficulté du travail d’ouverture de chaque jeu de données. Après avoir réalisé l’évaluation des données en fonction de la liste hiérarchisée souhaitée par la commune, nous nous sommes engagés vis-à-vis de la Ville à ouvrir leurs données sur trois jeux : le budget primitif (budget d’investissement), les espaces verts et les arbres (les deux sous-catégories de la catégorie espaces verts). Nous leur avons indiqué que nous pourrions peut-être ouvrir un ou deux autres jeux de données : celui des subventions aux associations et celui sur les usagers de la médiathèque. En effet, les trois premiers jeux de données correspondaient à une couleur verte, c’est-à-dire qu’ils ne nécessiteraient pas de grande difficulté pour être ouverts. De même, les deux autres jeux de données possibles correspondaient à une couleur verte et seraient donc facilement ouvrables. Nous pouvions donc nous engager sur un nombre significatif de jeux de données. Les autres jeux de données étaient plus difficilement ouvrables. La Ville a été satisfaite de constater que les jeux de données facilement ouvrables étaient également ceux qu’elles souhaitaient ouvrir en priorité. C’est pourquoi nous nous sommes engagés sur leurs trois premiers choix (le deuxième thème regroupant deux jeux de données).
JOUR 3 – MISE EN QUALITÉ
Hier, nous avons obtenu les bases de données depuis les différents services municipaux, puis déterminé en concertation avec notre interlocuteur la sélection des sujets d’étude que nous traiterons en priorité. Il s’agira aujourd’hui de traiter ces bases de données - en l’occurrence celle du budget, des espaces verts et des arbres - pour qu’elles puissent être exploitables.
En quoi cela consiste-t-il ? Rendre les données exploitables est une étape-clé de notre travail car cela permettra de rendre les données publiées concrètement utiles. Des données publiées trop rapidement ne pourront pas être exploitées par des tiers ou par nous-même, elles n’ont pas de valeurs en elle-même et perdent donc leur potentiel. Pour les manipulations de données d’aujourd’hui, nous utilisons le site “Workbench”. La mise en qualité comporte 4 étapes :
- Le nettoyage des données
- La compilation des données
- La standardisation des données
-
La validation
Nous sommes prévenus de bon matin : cette tâche est assez complexe puisqu’elle demande du temps et de l’énergie. Heureusement, le moral des troupes est encore fort !
1 - Le nettoyage des données
Notre journée commence par le nettoyage des données. Très vite, nous nous répartissons en trois groupes de deux pour “nettoyer” nos trois bases de données. Cela consiste à :
- Supprimer les lignes et colonnes vides. Ces colonnes ne sont pas utiles, tout comme les colonnes qui ne comportent qu’un nombre très réduit de données, car celles-ci ne pourront pas être systématisées à l’ensemble du jeu de données.
- Anonymisation des données : on supprime les données à caractère personnel (noms, adresse…), dans le respect du Règlement Général de la Protection des Données
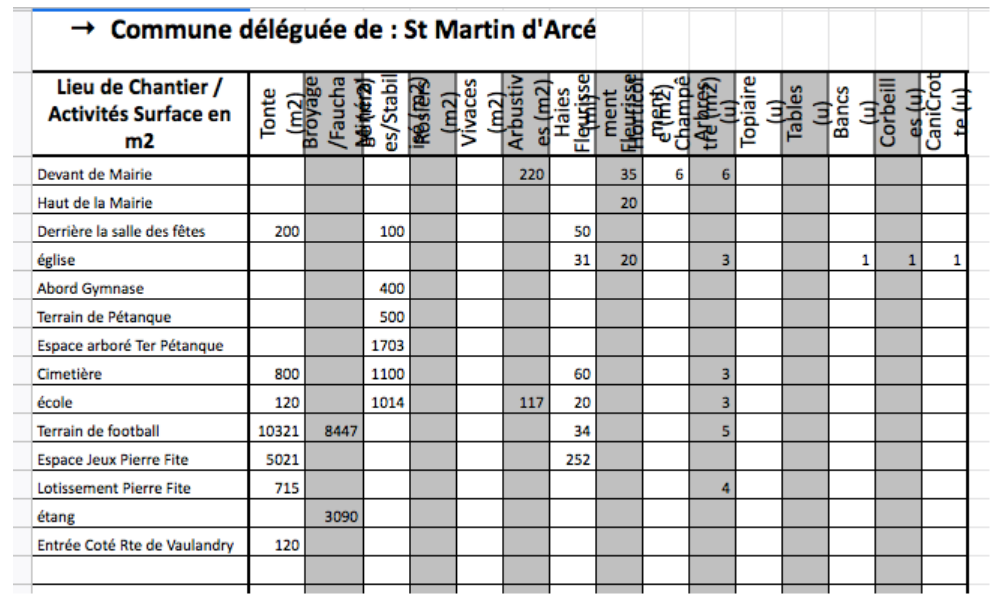
- Ajouter les informations manquantes. Par exemple, pour le cas des espaces verts (EV), les cellules étaient vides quand l’EV ne comportait pas l’item en question.
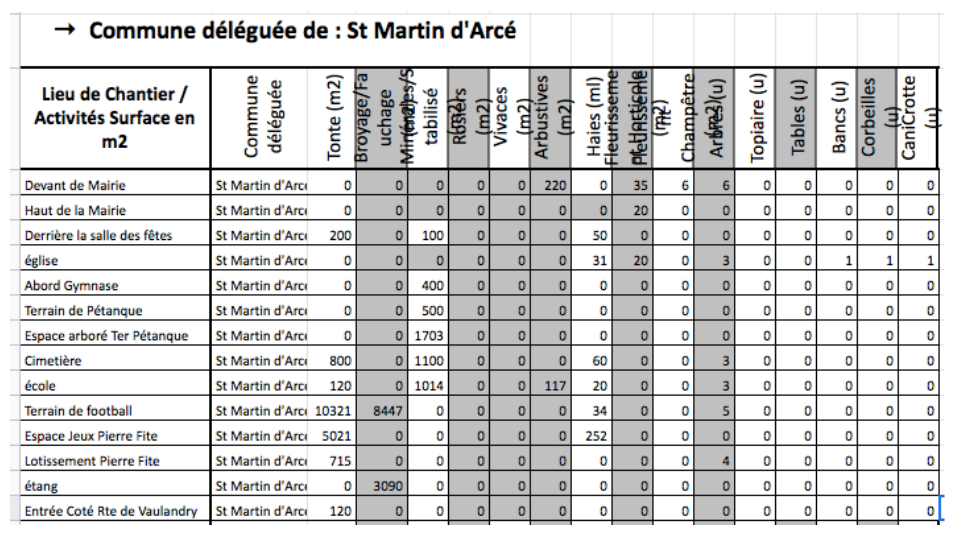
Il a donc fallu remplir ces cases par des “0” car autrement le programme ne pourrait pas analyser ces cellules.
- Corriger les informations : fautes de frappes, abréviations. On choisit par exemple de renommer des abréviations comme “Rt” en “Route”, “Pep. d’entreprise” en “Pépinière d’entreprise” afin qu’une fois répertoriée dans la base de données, la donnée concernant la route en question soit facilement trouvable par les utilisateurs de la base, qui n’ont pas forcément les mêmes codes que celui ou celle qui a produit les données.
- Défusionner les cellules : à chaque case du tableau son information
- Uniformisation : Dans la même idée, il faut que chaque ligne et chaque colonne soit cohérente dans ses informations. On ne doit pas trouver dans la même colonne des cases de texte et des cases de chiffres ou deux informations qui n’ont pas de rapport entre elles (mis à part la ligne des titres). Certaines informations de notre base de données des espaces verts étaient par exemple inscrits en km2 au lieu de m2, or il faut que toutes les informations d’une même colonne soient notées dans la même unité.
2 - La compilation des données
Vient ensuite l’étape de la compilation. Il s’agit en d’autres termes de mettre sur une base de données unique des données provenant de fichiers multiples.
Par exemple, les illustrations précédentes concernent les espaces verts de la seule commune déléguée de St Martin d’Arcé. Bien que cette information géographique soit importante, il faut la mettre dans un contexte à l’échelle de la commune de Baugé-en-Anjou. Nous devons donc compiler toutes les informations des différentes communes déléguées dans un même fichier pour pouvoir avoir une vue d’ensemble. C’est pour cela que nous avons rajouté la deuxième colonne pour pouvoir ensuite fusionner cette base de données avec les autres bases des différentes communes déléguées.
Pour compiler deux bases, il faut ajouter une nouvelle étape sur le Workbench en cliquant sur “Add step”, et exécuter l’opération “Join tab” et fusionner les listes concernées, en sélectionnant les colonnes nous intéressant.
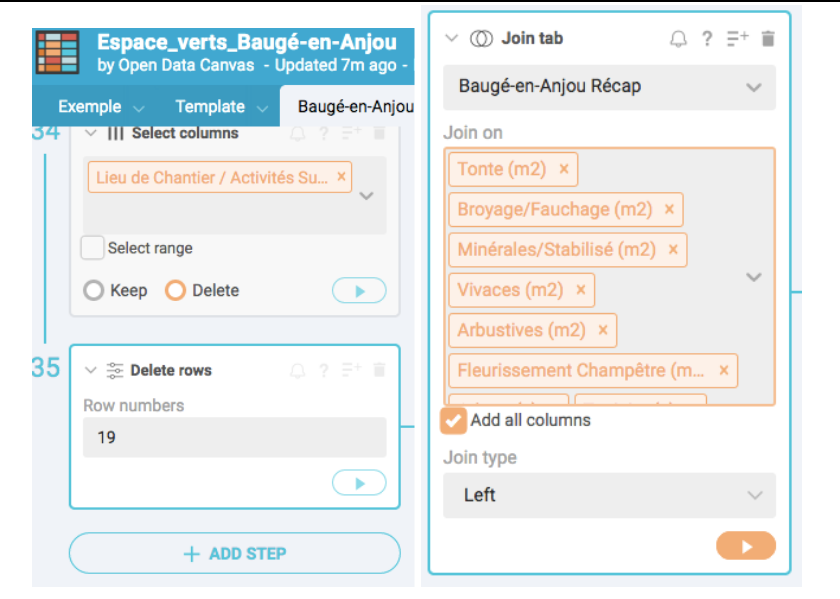
Nous avons été bloqués avec cette étape car nous n’avions pas commis une erreur de compréhension de cet outil. Il faut bien faire attention à compiler des bases de données traitant des informations qui ont au moins un élément commun d’une part, et analysant cet élément à la même échelle d’autre part. Pour reprendre l’exemple des espaces verts appliqués à ce problème, il n’est pas possible de compiler la base des données répertoriant comparant les totaux des espaces verts par communes déléguées avec un autre détaillant chacun des espaces verts de Baugé-sur-Anjou. L’échelle n’est en effet pas la même puisque la première base de données regarde l’espace vert à l’échelle des communes déléguées et la deuxième à l’échelle de l’espace vert lui-même. L’important dans l’open data est la granularité, c’est-à-dire avoir l’information la plus précise possible. La base de données des totaux des espaces verts par commune déléguée n’est donc pas nécessaire puisque celle détaillant tous les espaces verts permettra déjà d’avoir l’information des totaux à celui ou celle qui est intéressé par la question.
3 - La standardisation des données
Ensuite, notre base de données doit correspondre à un certain nombre de standards afin d’être exploités par le plus grand nombre et le plus facilement possible. Cela garantit la qualité des données et permet le croisement de données à des échelles plus grandes.
Les dates répondent à des standards internationaux tels que AAAA-MM-JJ. Il faut également enlever les virgules distinguant l’unité des milliers (utile pour le traitement de la base de données du budget).
Les titres des catégories de données (première ligne derépondent eux-aussi à des normes standardisées. Il faut donc rechercher ces normes et transformer en fonction de celle-ci le nom de la catégorie choisie par la commune. Par exemple, Baugé-en-Anjou catégorise sa base de données de son budget avec des termes qui lui sont propres et qu’il faut traduire par des termes précis. Ce que le budget baugeois lit comme les “Propositions” correspond en réalité au titre standardisé “BGT_MTREAL”, “Section” devient “BGT_SECTION”, etc.
Cette étape représente une vraie difficulté pour nos trois équipes car il est difficile de savoir à quoi correspondent les standards ou les catégories nommées par la mairie car nous ne connaissons pas la logique interne à la mairie. Par exemple, “OP.INVEST”, “OP.CPT.TIERS” et “C.COUT” sont des catégories qui ont été difficiles à standardiser. Il faut d’abord savoir à quoi correspondent les abréviations, par exemple “OP.CPT.TIERS” → “opérations pour compte de tiers”, puis trouver le standard. En l’occurrence pour ce dernier exemple, nous n’avons pas trouvé le standard. Ce travail a nécessité une vraie réflexion pour correctement interpréter les catégories.
Les exemples-types des bases de données déjà existantes ont été d’une grande aide pour nous aider avec cette difficulté. C’est pour cela que les experts nous ont recommandé les bases de données (BDD) les plus adaptées à nos études de cas. Par exemple, l’équipe se chargeant de la base de données des arbres serait partie sur une comparaison avec la BDD des espaces verts, alors qu’une base de données se concentrant spécifiquement sur les arbres serait plus appropriée. Ainsi, nous avons comparé notre BDD avec celles de Paris et de Montpellier, toutes deux bien renseignées. Cela nous a permis d’évaluer la pertinence et l’utilité de certaines de nos données. En comparant, nous nous sommes rendus compte qu’il nous manquait des données, certaines essentielles telles que la localisation. La BDD des arbres de Paris indique la longitude et la latitude et celle de Montpellier, à défaut, indique les adresses. Il serait préférable à l’avenir de renseigner la localisation précise des données. Cette règle vaut pour toutes les données se référant à des éléments physiques.
Une difficulté du même type gêne le traitement de la BDD des espaces verts. Parfois nécessaire, cette localisation se doit d’être la plus précise possible.
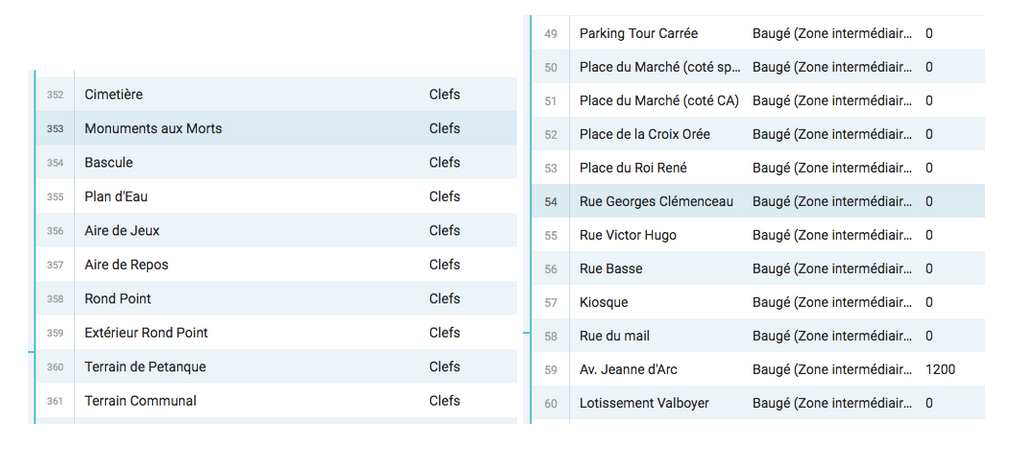
Or le lieu indiqué des espaces verts était parfois très vague. Si le “Rond Point” de Clefs est un lieu qui parle aux habitants et usagers de la commune, on doute que cela soit le cas pour les autres. Pour pouvoir exploiter la donnée de la localisation, qui est une donnée souvent très importante pour le traitement des données, il faudrait être en capacité de lier chacun des EV à une adresse précise. En l’état, la donnée de localisation est inexploitable. Nous avons essayer de faire correspondre les lieux de notre BDD à des repères géographiques grâce à un logiciel mais le taux d’erreur était trop important (repères placés sur toute la France, et quand bien même ils sont dans la bonne rue il ne désigne pas spécifiquement les EV). Nous ne pourrons malheureusement pas cartographier cet ensemble de données. A l’avenir, il serait bien de préciser le plus possible la localisation des bases de données.
4 - La validation
Enfin, la dernière étape de la journée est la validation. Il existe des sites vérifiant la qualité de nos bases de données, comme par exemple validata.etalab.studio, celui que nous avons utilisé pour vérifier la base de données du budget, correspondant à la catégorie du site nommée “Budget des collectivités et établissements publics locaux”. Une fois notre fichier déposé, il faut valider le fichier et le site affichera son résultat avec une jauge de validation évaluant en comparant avec une base de donnée standard. Voici la liste des bases de données standards qu’ils sont capables de valider :
Dans un premier temps, le site nous indiquait 674 erreurs pour la base de données du budget, qui correspondaient en majorité à des défauts de standardisation (problème de majuscule “Dépenses” → “dépenses”. Pour corriger ce type de faute de frappe sur Workbench il faut ajouter une nouvelle étape (Add a step) pour utiliser l’action “Refine”, en mergeant les deux écritures du mots différentes en une seule) ou encore dû au fait que nous avions omis la colonne du SIRET de la commune (colone BGT_SIRET). Après quelques corrections, le site a bien validé à 100% la conformité de notre base de données (BDD).
Nous avons également rencontré des difficultés pour la validation de la mise en qualité de la BDD des subventions aux associations, une BDD qui nous avons finalement eu le temps de traiter en plus des trois BDD sur lesquelles nous nous étions engagées. La difficulté provenait de données manquantes, qu’il nous a fallu attendre afin de compléter nos colonnes incomplètes. Les communes d’appartenance de certaines associations (pour le jeu de données « subventions associations ») étaient manquantes, ainsi que l’idAttribuant de chaque commune. Nous avons mis du temps à comprendre que cet identifiant correspondait au numéro SIRET et, après avoir recontacté une responsable du Service Finances, nous nous sommes assurées que le numéro SIRET était le même pour l’ensemble des quinze communes déléguées.
Enfin, nous avons dû changer les noms de colonnes pour les standardiser, supprimer des virgules et rajouter des tirets. Après plusieurs tentatives de validation sur Validata, nous avons dû nous résoudre à valider le jeu de données manuellement car la colonne ‘idBeneficiaire’ manquait au tableau Excel fourni par la collectivité. La responsable du Service Finances n’aurait ni eu le temps ni la possibilité de nous fournir les 176 identifiants manquants. Notre équipe étant déjà occupée par les trois principaux jeux de données, nous n’aurions pas eu le temps de traiter ces données manquantes. Pour cela, nous avons donc évalué 5 lignes du tableau au hasard en nous demandant si elles respectaient le format attendu (par rapport à un exemple-type), le résultat fut positif donc nous pouvons considérer que ce tableau ne contient pas d’erreur non plus. Nous avons utilisé la même méthode pour la BDD des espaces verts puisqu’aucun validateur ne nous permet de vérifier ce type de données.
Concernant la validation de la BDD des arbres, il en est ressorti des erreurs de fautes d’orthographes, de majuscules manquantes ou en trop, d’abréviations, et enfin des problèmes de ponctuation (certaines virgules, guillemets, ou points d’interrogation ne correspondant pas au standard des données). A la place des points d’interrogations, nous avons mis “Inconnu”. Un autre problème bloquant la validation venait du fait, comme relevé plus haut, que les données de géolocalisation nous manquaient. Pour pallier à ce problème nous avons tout de même mis les colonnes “latitude” et “longitude”, sans toutefois les remplir : ainsi le validateur a bien confirmé la conformité de notre BDD.
Pour faire le bilan de cette journée, les conseillers ne nous avaient pas menti en disant que cette journée serait chargée. Vu comme les conseillers étaient sollicités, ce sentiment est sûrement partagé par l’ensemble des équipes. Malgré tout, une fois avoir pris en main nos nouveaux outils de travail, nous avançons efficacement. Nous avons réalisé l’ensemble du travail sur lequel nous nous étions engagés, et nous avons même réussi à traiter une base de données supplémentaire ! Pour retrouver facilement la marche à suivre lors de la mise en qualité de données, vous pourrez dans le futur vous référer à ce carnet de bord ou suivre les étapes inscrites à gauche de la BDD dans Workbench pour facilement retrouver nos différentes manoeuvres. Demain, nous pourrons donc bien publier les données sur le budget communal, sur les arbres, sur les espaces verts et enfin sur les subventions allouées aux associations.
Liens Workbench (fichiers validés) :
- https://app.workbenchdata.com/public/moduledata/live/582155.csv (subventions associations)
- https://app.workbenchdata.com/public/moduledata/live/581550.csv (budget primitif investissements)
- https://app.workbenchdata.com/workflows/132621/ (espaces verts)
- https://app.workbenchdata.com/workflows/132898/ (arbres urbains)
JOUR 4 – PUBLICATION
Il est 9h lorsque nous arrivons (les premiers) sur Gather Town pour la réunion avec notre coach, Julia. Nous sommes revenus sur l’intense journée d’hier. Il a été noté qu’il serait nécessaire, aujourd’hui, de communiquer aux collectivités des remarques et recommandations au sujet des difficultés rencontrées lors du traitement de données.
Ce quatrième jour du challenge data est consacré à la publication de données et à l’opération communication de celle-ci. Dès la fin de notre réunion avec Julia, nous avons pris rendez-vous avec un adjoint au Maire en charge de la communication.
Nous avons ensuite entamé la complétion des fiches descriptives des jeux de données. Pour ce faire. Nous avons créé des copies du template afin que chaque binôme renseigne la fiche du jeu de donné qu’il avait traité hier. Nous ne disposions pas de toutes les informations nécessaires au remplissage de cette fiche. Chaque binôme a donc contacté, par écrit, les membres de la collectivité qui avaient envoyé les jeux de données. Si trois des quatres jeux de données ont pu recevoir leur réponse avant 11h, un binôme a dû attendre le milieu d’après-midi pour recevoir les informations manquantes à la fiche descriptive.
Nous avons ensuite partagé l’accessibilité des liens Workbench, en cochant la case ‘’Anyone can view and duplicate the workflow’’, afin que la collectivité puisse voir notre travail.
Nous avons sollicité un rendez-vous avec notre interlocuteur pour lui présenter les recommandations au sujet de ces données. Nous voulions en profiter pour leur demander si la collectivité possédait un compte Data.gouv. La procédure à suivre n’est pas la même selon si Baugé-en-Anjou possède ou non un compte.
Après une pause méridienne, nous avons préparé une stratégie de communication afin de, potentiellement, aiguiller l’adjoint au Maire chargé de la communication. Nous avons épluché les réseaux sociaux de Baugé-en-Anjou afin d’évaluer si ces-derniers étaient familiers à leur usage. Nous nous sommes également familiarisés avec leur site internet, mais aussi avec le template du plan de communication.
A 14h a eu lieu la réunion avec le service communication pour évoquer la stratégie de communication à développer. Il en est sorti que la communication devait s’accentuer sur la thématique de ‘‘l’innovation’’. Des publications seront nécessaires pour les comptes Twitter et Facebook de Baugé-en-Anjou, ainsi que pour leur site internet. Un communiqué explicatif destiné aux membres de la collectivité a également été demandé.
Les membres de la collectivité étant en réunion aujourd’hui, nous avons profité de la présence de l’adjoint au Maire pour lui faire part de nos interrogations. Il nous a indiqué que Baugé-en-Anjou ne possédait pas de compte Data.gouv.
A la suite de la réunion, nous avons divisé le groupe en deux. Certains étudiants spécialisés dans le master Culture & Communication se sont axés sur le plan de communication, tandis que l’autre moitié du groupe a suivi la procédure de création de compte Data.gouv et publié les données.
Concernant la création de compte et la publication des données, le travail s’est fait en suivant méticuleusement les indications fournies par Datactivist. Les différents services de la commune n’avaient pas précisé quel type de licence était souhaitée (ouvert/ODbl). Nous avons opté pour une licence ouverte, moins contraignante et utilisée dans 98% des cas. Aucune difficulté notable n’est à signaler lors de cette phase, si ce n’est que cela nécessite un certain temps.
L’équipe de communication a réalisé un modèle de publication étant compatible aux caractères limités de Twitter. Nous avons également réalisé plusieurs visuels, leur permettant d’illustrer les publications pour les jeux de données traité lors du Challenge Data. L’adjoint au Maire nous avait indiqué que Baugé-en-Anjou ne possédait pas de charte graphique.

Nous avons par ailleurs raccourci le lien menant au site Data.gouv avec une extension de Google Chrome. L’objectif de cette manipulation était de faire tenir le et le lien sur une publication Twitter.
Nous avons rédigé une publication pouvant être placée sur leur site internet, ainsi qu’un communiqué à destination des membres de la collectivité. Nous avons également rempli et adapté le template afin de ne retenir que des missions de communication réalisables à l’échelle de la collectivité.
A la fin de la journée, le compte Data.gouv de Baugé-en-Anjou a été créé. Les tableaux de données ainsi que leurs fiches descriptives ont été publiés. Datactivist a relayé cette publication via Twitter, également partagée par la collectivité de Baugé-en-Anjou.
Le plan de communication a été mis en place et ses éléments ont été créés et envoyés à la collectivité. N’ayant pu nous entretenir avec notre interlocuteur, nous avons créé un document compilant les recommandations pour les jeux de données, que nous lui avons transmis. Un journaliste est passé dans notre groupe afin de nous poser quelques questions.
Tout au long de la journée, lorsque nous avions des interrogations, les coachs de l’équipe Datactivist ont su répondre présent. Aujourd’hui nous avions de la chance, notre coach référente, Julia, était très présente ! Cette image témoigne de la très belle ambiance qui règne dans le Challenge Data, comme dans le groupe de Baugé-en-Anjou. Cet aspect est un véritable point positif tant il est une force d’impulsion pour le projet.
Réalisations du jour:
- Fiche des jeux de données : https://drive.google.com/file/d/1sL2WYMjZAHA_a3Zn4D8FpY06SXnw5B0x/view
- Lien Data.gouv de Baugé-en-Anjou :https://www.data.gouv.fr/fr/organizations/bauge-en-anjou/
- Plan de communication :
Stratégie de communication, textes et visuels des publications concernant les jeux de données venant d’être ouverts : https://docs.google.com/document/d/1kAToiK0VojsvYA3UlKv_5VdO7EkinEbBQTUvIkNLEk4/edit
Recommandation de stratégie de communication globale pour les jeux de données ouverts à l’avenir : https://drive.google.com/file/d/1nGNa64tS6IAEL4u6EaZXKUED9eVV_Y69/view?usp=sharing Fiche recommandation concernant les données, communiquée à la collectivité et envoyée par mail à Julia : https://docs.google.com/document/d/1U72Yo4OMCSchZAGFJrsbZ7YlwPTV9JYCIzfpGch1Vf8/edit
JOUR 5 – VALORISATION
Le but du 5ème et dernier jour était de faire parler les données en produisant des “Dataviz” (datavisualisations) pour permettre à tous de tirer des informations en quelques coups d’œil. Il nous a fallu remplir 4 objectifs: réaliser les dataviz - les contextualiser - les publier sur data.gouv et enfin, les présenter à la collectivité lors de la restitution en fin de journée.
Objectif n°1: Réalisation des dataviz
Avant de nous lancer dans la réalisation des datavisualisations, nous nous sommes répartis le travail en groupes de deux, afin de travailler sur 4 jeux de données (budget des investissements pour 2021, subventions des associations de 2018 à 2020, espaces verts et arbres urbains). Par la suite, il nous a fallu nous rendre sur un des sites conseillés par les experts (https://app.rawgraphs.io/ , https://www.opendatasoft.com/fr/ et https://app.workbenchdata.com). Cependant, nous avons rencontré des difficultés avec chacun de ces sites. Par exemple, le site Rawgraphs ne nous permettait pas d’importer nos fichiers csv ou excel. Nous avons ainsi tenté une autre approche en copiant toutes les données de nos tableaux et en les collant dans l’onglet “paste” du site. Toutefois, une fois après avoir réussi à faire cela, nous nous sommes rendus compte que les graphiques réalisés n’étaient pas très esthétiques, nous ne pouvions pas modifier la police des éléments inscrits sur les graphiques par exemple. Certains membres de l’équipe ont décidé de poursuivre avec cet outil, quant aux autres, ils ont choisi de passer par Excel ou Google Sheets pour réaliser les dataviz car les autres outils ne leur convenaient pas.
Afin de commencer notre sélection de données à représenter sur les graphiques, nous avons tous formulé une question centrale pour guider la lecture de nos dataviz.
Les graphiques portant sur les subventions répondaient à la question : “quelle est l’évolution de la répartition des subventions aux associations de la ville de Baugé-en-Anjou par domaines de 2018 à 2020 ?”. Les données budget ont fait l’objet d’une sélection suivant la question : “quelle est la répartition du budget d’investissement effectif et prévisionnel de 2021 ?”. Les données “espace verts” répondent à la question : “quelle est la répartition, et quelles sont les caractéristiques des espaces verts de Baugé-en-Anjou ? Enfin, concernant les arbres urbains, le graphique tentait de répondre à la question: “quels sont les attributs des arbres urbains de Baugé-en-Anjou ?”
Une fois après avoir trouvé le bon logiciel pour réaliser les dataviz, nous avons enfin pu commencer à sélectionner les colonnes utiles pour les graphiques. Par exemple, pour le budget, nous n’avions pas besoin de la colonne “BGT_SIRET”, car le numéro de SIRET nous importait peu. Nous avons seulement gardé les colonnes “BGT_CODRD”, “BGT_NOM” et “BGT_MTREAL”. Nous avons également décidé de réaliser plusieurs dataviz pour chaque jeu de données (par exemple pour le jeu de données sur le budget nous avons un dataviz concernant les dépenses et un concernant les recettes, ce qui nous permettra de donner des informations différentes pour un même jeu de données).
Nous avons ensuite cherché les modèles de graphiques correspondants aux jeux de données choisis sur le site https://datavizproject.com/ . Pour le jeu de données “budget” nous avons retenu un graphique de type “Treemap” car il permettait de bien représenter les dépenses des différents services (finances, environnement, voirie…). Le modèle packedcircle chart a quant à lui été retenu pour les arbres, une représentation en cercles est en effet visuellement parlante pour représenter le nombre d’arbres par communes déléguées. D’autre part, la répartition des types de plantes et infrastructures (type tables, bancs etc.) fera l’objet d’un autre dataviz et a été réalisé sous le modèle d’un histogramme groupé et d’un autre empilé. Enfin, le modèle retenu pour les subventions des associations était “column charts”, les colonnes étant un bon moyen de représentation de la répartition des subventions par type d’association.
Toutefois, les difficultés se sont multipliées au moment de la réalisation des dataviz. En effet, pour prendre un exemple simple: Excel comptait plusieurs fois les mêmes catégories de données, ce qui rendait une dataviz de cette forme :
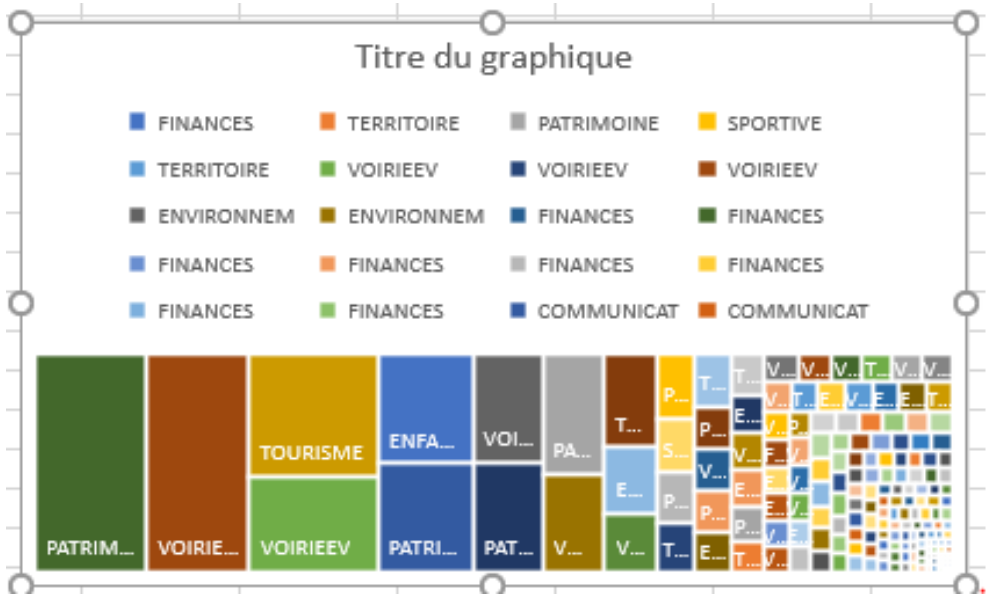
Aussi avons-nous dû calculer les totaux de chaque pôle (tous les totaux des pôles finances, environnement, équipement etc.) dans un nouveau tableau Excel, puis, ne fonctionnant toujours pas, nous nous nous sommes rendus compte qu’il fallait mettre des virgules dans les tableaux de calcul pour effectuer les totaux, virgules que nous avions enlevé pour standardiser les fichiers dans workbench. Une fois les totaux faits, nous nous sommes rendus compte que nous avions calculé les recettes et les dépenses en même temps, ce qui nous donnait des résultats erronés. Après ces erreurs de calcul nous avons enfin pu réaliser la dataviz.
Autre exemple de difficulté, pour les subventions d’associations : nous ne savions pas quelle forme adopter pour le tableau car nous possédions des données selon les années et selon les secteurs. Au départ, nous avions choisi de faire 5 colonnes pour 5 domaines mais combiner les 3 années dans les 5 colonnes s’est avéré trop compliqué. Nous nous sommes alors résolus à réaliser 3 colonnes correspondant aux 3 années représentées. Par ailleurs, ces 3 années nous ont aussi posé problème car elles ne permettaient pas de comparer de grandes différences avec un autre mandat par exemple. Enfin, le graphique en numéraire (et non en pourcentage) montrait une baisse de subventions accordées pour l’année 2020, ce qui ne mettait pas forcément la collectivité en valeur. Nous avons alors d’abord pensé transformer les valeurs en pourcentage mais cela rendait le graphique moins lisible. Aussi avons-nous opté pour la transparence et choisi des valeurs numéraires.
A cause de ces difficultés, nous n’avions toujours pas fini nos dataviz respectives à 12h30. En milieu d’après-midi nous avons cependant tous réussi à réaliser les visualisations. La mise en page nous a cependant pris du temps, Excel ne nous permettant pas de modifier toutes les caractéristiques du graphique, nous sommes parfois passés par word pour agrandir la légende par exemple.
Objectif n°2: Contextualisation
Dans un deuxième temps, il nous a fallu expliquer nos choix car des visualisations ne sont jamais neutres. Nos choix pourront être lus ici : https://docs.google.com/document/d/1V7J1KlKCjvqqjclNjclwwWtCp3yWcN1Ahn3HspdlGOw/edit#
Objectif n°3: Publication
Étant passés par Excel ou Google Sheets nous ne pouvions pas directement publier nos réalisations. Nous avons donc envoyé le lien de notre présentation avec toutes les dataviz à l’expert Arthur qui nous a apporté son aide.
Objectif n°4: Restitution
De 17h à 18h30 nous avons restitué notre travail devant le Maire de Baugé-en-Anjou, la DGS, un adjoint au Maire, et notre interlocuteur. Nous avons commencé notre présentation par une restitution globale et brève de nos activités de la semaine, en rappelant les étapes clés de notre processus. Pour poursuivre, nous avons présenté nos différentes visualisations en les commentant. Il nous a fallu insister sur le fait que notre travail n’était pas d’analyser les données mais bien de les ouvrir, et que nos jeux de données ouverts étaient des exemples de ce que la collectivité pourrait faire. Il semble que le jeu de données sur les arbres ait intéressé nos interlocuteurs car il a permis de bien faire comprendre aux élus là où il manquait des données. Cette dataviz a en effet illustré l’utilité de la visualisation et de l’ouverture des jeux de données. M. Le Maire en a donc conclu qu’il fallait veiller à ce que leurs jeux de données soient complets.
CONCLUSION
Bilan pour la commune
Au terme de ces cinq jours de travail intensif, notre équipe dresse un bilan très positif de ce Challenge Data. Nous sommes ravis d’avoir pu fournir un travail précis et consciencieux à la Ville de Baugé-en-Anjou à partir des données fournies par ses différents services, que nous tenons à remercier tout particulièrement pour leur temps et réactivité tout au long de la semaine.
Notre interlocteur, qui a suivi notre projet avec enthousiasme et intérêt, nous a chaudement félicités pour le travail accompli : ceci prouve, nous l’espérons, que notre travail a été utile à la collectivité et la rapproche un peu plus de son objectif d’ouverture et de transparence des données. Nous sommes parvenus à publier cinq jeux de données alors même que nous craignions de manquer de temps pour en faire plus de trois ; les agents et usagers de la collectivité pourront désormais consulter facilement les données relatives au budget d’investissement de Baugé-en-Anjou, aux subventions accordées aux associations de la Ville, ainsi qu’aux données concernant ses arbres et espaces verts (https://www.data.gouv.fr/fr/organizations/bauge-en-anjou/). Notre travail a eu pour but de débloquer les freins à la transition open data soulevés par les représentants de la Ville, à savoir une certaine méconnaissance du sujet et un manque de temps (dû à la récente création de la collectivité, pour laquelle tous les efforts étaient jusque-là mobilisés). Nous espérons avoir épargné aux services de la Ville un travail long et laborieux d’évaluation de la maturité open data de la collectivité, en posant un premier diagnostic des capacités actuelles et en soumettant des propositions pour mettre en œuvre une politique d’ouverture des données sur le long terme. Pour cela, nous avons consciencieusement tenu à jour ce carnet de bord afin d’y consigner notre activité journalière dans les moindres détails, ce qui nous permet de fournir un guide précis aux continuateurs de cet ambitieux projet et de leur éviter les difficultés que nous avons pu rencontrer au cours de la semaine. Cela devrait leur permettre de surmonter l’obstacle technique, le plus tenace lorsque l’on souhaite se lancer dans une transition open data, et servira à leur ouvrir la voie vers toujours plus d’innovation et de transparence en toute fluidité.
Comme le soulignait très justement l’adjoint au Maire lors de notre première réunion avec la collectivité, s’engager dans l’open data permet non seulement de donner du sens à des données froides et inexploitées, mais surtout de mieux connaître sa Ville et ses habitants : ceci en fait un outil prometteur et pertinent dans les processus de renforcement démocratique. Nous espérons que la Ville trouvera un appui dans notre travail, et soutiendra dans les années à venir la mise en place d’un service ou d’un personnel responsable de l’open data !
Bilan pour le groupe
Notre groupe de six étudiants, tous issus de spécialités différentes, est ressorti plus soudé et qualifié de cette expérience, plus conscient des problématiques et des enjeux liés à l’open data. Nous avons particulièrement apprécié cette semaine de travail en groupe, à l’heure où les interactions sociales et les échanges entre jeunes se font rares, et nous tirons un bilan très positif de notre organisation ces cinq derniers jours. Les sessions de brainstorming et le travail en binôme se sont révélés être des stratégies efficaces et stimulantes, les compétences des uns (Excel, finances publiques, communication, etc) palliant aux difficultés des autres. Ce challenge nous a également redonné un rythme de travail structuré, avec un emploi du temps intense (9h-18h) mais indispensable pour fournir un travail de qualité en peu de temps. Nous regrettons néanmoins qu’il ait eu lieu en pleine période de partiels, de candidatures en masters, voire même de recherche de stage de M1 pour certains, mais comprenons que le choix des dates ait été grandement conditionné par le contexte exceptionnel de cette année. Nous sommes ravis d’avoir découvert des sites, logiciels et outils performants tels que Workbench, Airtable, Raw Graph, Gather et data.gouv.fr, qui nous seront sans nul doute utiles lors de futurs stages ou emplois et ne manqueront pas d’ajouter une plus-value à nos CV respectifs. Nous avons bien compris que ce challenge reposait sur une base de “donnant-donnant”, ce qui nous a permis de l’aborder avec sérieux et enthousiasme.
Cette semaine n’est pas allée sans son lot de victoires et de difficultés, mais toutes ont été bénéfiques et formatrices. Que ce soit des problèmes de standardisation des données, de logiciels difficiles à maîtriser du premier coup, de données inexploitables ou de délais serrés, nous sommes chaque jour parvenus à surmonter ces obstacles en y réfléchissant collectivement ou en faisant appel à l’expertise de nos coachs Datactivist. Leur aide, leur patience et leur pédagogie nous ont été très précieuses tout au long de ce challenge et nous tenons à les remercier de nous avoir si bien encadrés et formés ! Nous considérons que notre plus grande difficulté aura été la valorisation des données, certains logiciels de mise en forme n’étant pas compatibles avec nos fichiers ; notre plus grande réussite aura été de publier plus de jeux de données que prévu à force d’entraide et de persévérance.
En tant qu’étudiants en sciences politiques, nous avons progressivement pris conscience de l’intérêt de l’open data au sein des institutions démocratiques, et ce par le meilleur des moyens : la pratique alliée à la théorie. Il est regrettable que ces problématiques soient encore obscures pour de nombreux services publics, qui pourraient tirer profit, crédit et efficacité de ce type d’initiative en faveur de l’open data. Au-delà des agents de collectivités, notre travail d’ouverture, de transparence et d’accessibilité bénéficiera également aux usagers de Baugé-en-Anjou, qui auront la possibilité d’accéder plus facilement à des données qui les concernent directement. Nous l’avons notamment réalisé lors de l’étape de valorisation des données, quand nous avons dû choisir la forme de graphique la plus adaptée à notre jeu de données “Subventions aux associations” ; l’une des formes mettait clairement en évidence que les associations classées dans la catégorie “social-enfant-jeunesse-scolaires” étaient de loin les plus subventionnées par la collectivité, et nous avons hésité à publier ce graphique au risque de créer une gêne entre décideurs et associations au vu de ce qui pouvait être perçu comme un certain déséquilibre. Nous avons toutefois fini par retenir cette forme car le but de l’open data est de biaiser le moins possible les données et c’était la forme de visualisation la plus parlante et pertinente pour le jeu de données que nous avions à traiter donc ce choix s’imposait. Cette expérience nous a montré ce que la publication et l’analyse de données pouvaient avoir de politique (publier c’est déjà, d’une certaine façon, s’engager) et nous a fait comprendre l’importance de la promotion des initiatives open data au travers du territoire.
Nous espérons sincèrement que notre travail sera utile à la Ville de Baugé-en-Anjou, pour laquelle nous avons eu plaisir à travailler, et espérons qu’il n’est que le début d’une longue aventure démocratique et connectée !
